 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-RADS Synthetic Radiology Report Dataset and Head-to-Head Benchmarking of 41 Open-Weight and Proprietary Language Models
Jan 06, 2026Background: Reporting and Data Systems (RADS) standardize radiology risk communication but automated RADS assignment from narrative reports is challenging because of guideline complexity, output-format constraints, and limited benchmarking across RADS frameworks and model sizes. Purpose: To create RXL-RADSet, a radiologist-verified synthetic multi-RADS benchmark, and compare validity and accuracy of open-weight small language models (SLMs) with a proprietary model for RADS assignment. Materials and Methods: RXL-RADSet contains 1,600 synthetic radiology reports across 10 RADS (BI-RADS, CAD-RADS, GB-RADS, LI-RADS, Lung-RADS, NI-RADS, O-RADS, PI-RADS, TI-RADS, VI-RADS) and multiple modalities. Reports were generated by LLMs using scenario plans and simulated radiologist styles and underwent two-stage radiologist verification. We evaluated 41 quantized SLMs (12 families, 0.135-32B parameters) and GPT-5.2 under a fixed guided prompt. Primary endpoints were validity and accuracy; a secondary analysis compared guided versus zero-shot prompting. Results: Under guided prompting GPT-5.2 achieved 99.8% validity and 81.1% accuracy (1,600 predictions). Pooled SLMs (65,600 predictions) achieved 96.8% validity and 61.1% accuracy; top SLMs in the 20-32B range reached ~99% validity and mid-to-high 70% accuracy. Performance scaled with model size (inflection between <1B and >=10B) and declined with RADS complexity primarily due to classification difficulty rather than invalid outputs. Guided prompting improved validity (99.2% vs 96.7%) and accuracy (78.5% vs 69.6%) compared with zero-shot. Conclusion: RXL-RADSet provides a radiologist-verified multi-RADS benchmark; large SLMs (20-32B) can approach proprietary-model performance under guided prompting, but gaps remain for higher-complexity schemes.
Coarse-Grained Configurational Polymer Fingerprints for Property Prediction using Machine Learning
Nov 20, 2023In this work, we present a method to generate a configurational level fingerprint for polymers using the Bead-Spring-Model. Unlike some of the previous fingerprinting approaches that employ monomer-level information where atomistic descriptors are computed using quantum chemistry calculations, this approach incorporates configurational information from a coarse-grained model of a long polymer chain. The proposed approach may be advantageous for the study of behavior resulting from large molecular weights. To create this fingerprint, we make use of two kinds of descriptors. First, we calculate certain geometric descriptors like Re2, Rg2 etc. and label them as Calculated Descriptors. Second, we generate a set of data-driven descriptors using an unsupervised autoencoder model and call them Learnt Descriptors. Using a combination of both of them, we are able to learn mappings from the structure to various properties of the polymer chain by training ML models. We test our fingerprint to predict the probability of occurrence of a configuration at equilibrium, which is approximated by a simple linear relationship between the instantaneous internal energy and equilibrium average internal energy.
CausalCite: A Causal Formulation of Paper Citations
Nov 05, 2023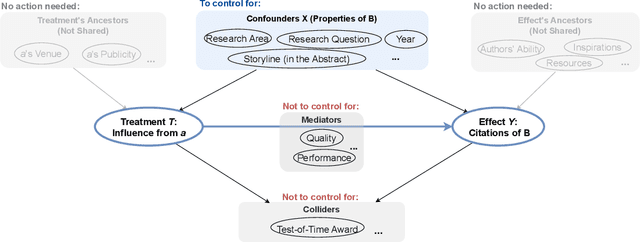


Evaluating the significance of a paper is pivotal yet challenging for the scientific community. While the citation count is the most commonly used proxy for this purpose, they are widely criticized for failing to accurately reflect a paper's true impact. In this work, we propose a causal inference method, TextMatch, which adapts the traditional matching framework to high-dimensional text embeddings. Specifically, we encode each paper using the text embeddings by large language models (LLMs), extract similar samples by cosine similarity, and synthesize a counterfactual sample by the weighted average of similar papers according to their similarity values. We apply the resulting metric, called CausalCite, as a causal formulation of paper citations. We show its effectiveness on various criteria, such as high correlation with paper impact as reported by scientific experts on a previous dataset of 1K papers, (test-of-time) awards for past papers, and its stability across various sub-fields of AI. We also provide a set of findings that can serve as suggested ways for future researchers to use our metric for a better understanding of a paper's quality. Our code and data are at https://github.com/causalNLP/causal-cite.