 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Context Selection Improves Simple Regret in Contextual Bandits
May 19, 2026We study the contextual multi-armed bandit problem with a finite context space (a.k.a. subpopulations), where the learner recommends a best action for each context and is evaluated by context-weighted simple regret. Our guarantees are worst-case over the reward distributions, while remaining instance-dependent with respect to the context distribution vector $p$. Akin to experimental design problems where the population of interest is fixed but the sampled subpopulation can be controlled, we allow the learner to actively choose which context to sample from. For a known $p$, we characterize tight regret rates: passive sampling where contexts are randomly revealed achieves regret of order $\sqrt{n/T \, \lVert p \rVert_{1/2}}$, whereas active sampling with allocation $q_j \propto p_j^{2/3}$ achieves the tight rate $\sqrt{n/T} \, \lVert p \rVert_{2/3}$. The resulting improvement can be as large as $Θ(k^{1/4})$, where $k$ is the number of contexts. We further extend the analysis to budgeted active sampling, characterize the corresponding tight rate, and identify when a limited active budget suffices to recover the fully active rate. When $p$ is unknown, we propose the Explore-Explore-Then-Commit (EETC) algorithm, which optimally balances estimating the context distribution and the time to switch to active allocation, such that for large horizons, it matches the known-$p$ active rate up to constants. Experiments on synthetic and real-world data support our theoretical findings.
Select-then-differentiate: Solving Bilevel Optimization with Manifold Lower-level Solution Sets
May 09, 2026We study optimistic bilevel optimization when the lower-level problem has a non-isolated manifold of minimizers. In this setting, the hyper-objective may be non-differentiable because the upper-level criterion must choose among multiple lower-level solutions. Under a local Polyak--Łojasiewicz (PŁ) condition, we show that differentiability does not require the lower-level solution set to be a singleton: uniqueness of the optimistic selection is sufficient. This yields an explicit pseudoinverse-based hyper-gradient formula extending the classical singleton-minimizer result. We further characterize the regularity of the hyper-objective: non-degeneracy of the selected minimizer along the solution manifold yields local smoothness, while failure of uniqueness can create many non-differentiable points and failure of non-degeneracy can destroy all positive Hölder regularity of the hyper-gradient. Motivated by this theory, we propose HG-MS, a select-then-differentiate method combining explicit optimistic selection with efficient pseudoinverse-based hyper-gradient computation. Despite the nonconvex nature of optimistic selection over the lower-level solution manifold, we show that HG-MS converges to a stationary point of the optimistic objective with complexity governed by the intrinsic dimension of the solution manifold rather than its ambient dimension. Empirically, we test a practical variant of HG-MS for matched-budget LLM source reweighting. This variant preserves the select-then-differentiate principle and obtains the best GSM8K/MATH scores across the tested backbones, along with competitive or best MT-Bench instruction-following results.
Zeroth-Order Stackelberg Control in Combinatorial Congestion Games
Feb 26, 2026We study Stackelberg (leader--follower) tuning of network parameters (tolls, capacities, incentives) in combinatorial congestion games, where selfish users choose discrete routes (or other combinatorial strategies) and settle at a congestion equilibrium. The leader minimizes a system-level objective (e.g., total travel time) evaluated at equilibrium, but this objective is typically nonsmooth because the set of used strategies can change abruptly. We propose ZO-Stackelberg, which couples a projection-free Frank--Wolfe equilibrium solver with a zeroth-order outer update, avoiding differentiation through equilibria. We prove convergence to generalized Goldstein stationary points of the true equilibrium objective, with explicit dependence on the equilibrium approximation error, and analyze subsampled oracles: if an exact minimizer is sampled with probability $κ_m$, then the Frank--Wolfe error decays as $\mathcal{O}(1/(κ_m T))$. We also propose stratified sampling as a practical way to avoid a vanishing $κ_m$ when the strategies that matter most for the Wardrop equilibrium concentrate in a few dominant combinatorial classes (e.g., short paths). Experiments on real-world networks demonstrate that our method achieves orders-of-magnitude speedups over a differentiation-based baseline while converging to follower equilibria.
Causal Effect Identification in Heterogeneous Environments from Higher-Order Moments
Jun 13, 2025We investigate the estimation of the causal effect of a treatment variable on an outcome in the presence of a latent confounder. We first show that the causal effect is identifiable under certain conditions when data is available from multiple environments, provided that the target causal effect remains invariant across these environments. Secondly, we propose a moment-based algorithm for estimating the causal effect as long as only a single parameter of the data-generating mechanism varies across environments -- whether it be the exogenous noise distribution or the causal relationship between two variables. Conversely, we prove that identifiability is lost if both exogenous noise distributions of both the latent and treatment variables vary across environments. Finally, we propose a procedure to identify which parameter of the data-generating mechanism has varied across the environments and evaluate the performance of our proposed methods through experiments on synthetic data.
Causal Effect Identification in lvLiNGAM from Higher-Order Cumulants
Jun 06, 2025This paper investigates causal effect identification in latent variable Linear Non-Gaussian Acyclic Models (lvLiNGAM) using higher-order cumulants, addressing two prominent setups that are challenging in the presence of latent confounding: (1) a single proxy variable that may causally influence the treatment and (2) underspecified instrumental variable cases where fewer instruments exist than treatments. We prove that causal effects are identifiable with a single proxy or instrument and provide corresponding estimation methods. Experimental results demonstrate the accuracy and robustness of our approaches compared to existing methods, advancing the theoretical and practical understanding of causal inference in linear systems with latent confounders.
Best Group Identification in Multi-Objective Bandits
May 23, 2025We introduce the Best Group Identification problem in a multi-objective multi-armed bandit setting, where an agent interacts with groups of arms with vector-valued rewards. The performance of a group is determined by an efficiency vector which represents the group's best attainable rewards across different dimensions. The objective is to identify the set of optimal groups in the fixed-confidence setting. We investigate two key formulations: group Pareto set identification, where efficiency vectors of optimal groups are Pareto optimal and linear best group identification, where each reward dimension has a known weight and the optimal group maximizes the weighted sum of its efficiency vector's entries. For both settings, we propose elimination-based algorithms, establish upper bounds on their sample complexity, and derive lower bounds that apply to any correct algorithm. Through numerical experiments, we demonstrate the strong empirical performance of the proposed algorithms.
Multi-Domain Causal Discovery in Bijective Causal Models
Apr 30, 2025We consider the problem of causal discovery (a.k.a., causal structure learning) in a multi-domain setting. We assume that the causal functions are invariant across the domains, while the distribution of the exogenous noise may vary. Under causal sufficiency (i.e., no confounders exist), we show that the causal diagram can be discovered under less restrictive functional assumptions compared to previous work. What enables causal discovery in this setting is bijective generation mechanisms (BGM), which ensures that the functional relation between the exogenous noise $E$ and the endogenous variable $Y$ is bijective and differentiable in both directions at every level of the cause variable $X = x$. BGM generalizes a variety of models including additive noise model, LiNGAM, post-nonlinear model, and location-scale noise model. Further, we derive a statistical test to find the parents set of the target variable. Experiments on various synthetic and real-world datasets validate our theoretical findings.
Sample Complexity of Nonparametric Closeness Testing for Continuous Distributions and Its Application to Causal Discovery with Hidden Confounding
Mar 10, 2025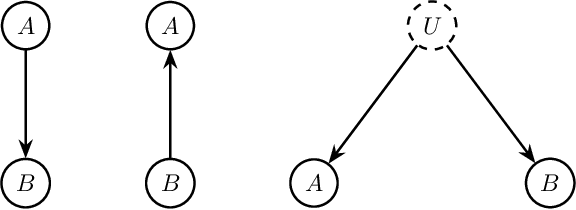
We study the problem of closeness testing for continuous distributions and its implications for causal discovery. Specifically, we analyze the sample complexity of distinguishing whether two multidimensional continuous distributions are identical or differ by at least $\epsilon$ in terms of Kullback-Leibler (KL) divergence under non-parametric assumptions. To this end, we propose an estimator of KL divergence which is based on the von Mises expansion. Our closeness test attains optimal parametric rates under smoothness assumptions. Equipped with this test, which serves as a building block of our causal discovery algorithm to identify the causal structure between two multidimensional random variables, we establish sample complexity guarantees for our causal discovery method. To the best of our knowledge, this work is the first work that provides sample complexity guarantees for distinguishing cause and effect in multidimensional non-linear models with non-Gaussian continuous variables in the presence of unobserved confounding.
Graph-Dependent Regret Bounds in Multi-Armed Bandits with Interference
Mar 10, 2025Multi-armed bandits (MABs) are frequently used for online sequential decision-making in applications ranging from recommending personalized content to assigning treatments to patients. A recurring challenge in the applicability of the classic MAB framework to real-world settings is ignoring \textit{interference}, where a unit's outcome depends on treatment assigned to others. This leads to an exponentially growing action space, rendering standard approaches computationally impractical. We study the MAB problem under network interference, where each unit's reward depends on its own treatment and those of its neighbors in a given interference graph. We propose a novel algorithm that uses the local structure of the interference graph to minimize regret. We derive a graph-dependent upper bound on cumulative regret showing that it improves over prior work. Additionally, we provide the first lower bounds for bandits with arbitrary network interference, where each bound involves a distinct structural property of the interference graph. These bounds demonstrate that when the graph is either dense or sparse, our algorithm is nearly optimal, with upper and lower bounds that match up to logarithmic factors. We complement our theoretical results with numerical experiments, which show that our approach outperforms baseline methods.
Optimal Best Arm Identification with Post-Action Context
Feb 05, 2025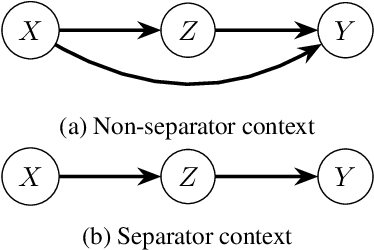
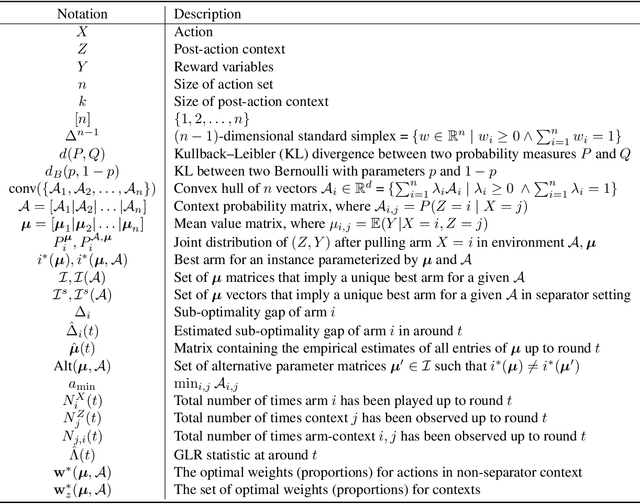
We introduce the problem of best arm identification (BAI) with post-action context, a new BAI problem in a stochastic multi-armed bandit environment and the fixed-confidence setting. The problem addresses the scenarios in which the learner receives a $\textit{post-action context}$ in addition to the reward after playing each action. This post-action context provides additional information that can significantly facilitate the decision process. We analyze two different types of the post-action context: (i) $\textit{non-separator}$, where the reward depends on both the action and the context, and (ii) $\textit{separator}$, where the reward depends solely on the context. For both cases, we derive instance-dependent lower bounds on the sample complexity and propose algorithms that asymptotically achieve the optimal sample complexity. For the non-separator setting, we do so by demonstrating that the Track-and-Stop algorithm can be extended to this setting. For the separator setting, we propose a novel sampling rule called $\textit{G-tracking}$, which uses the geometry of the context space to directly track the contexts rather than the actions. Finally, our empirical results showcase the advantage of our approaches compared to the state of the art.