 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Best Arm Identification with Post-Action Context
Paper and Code
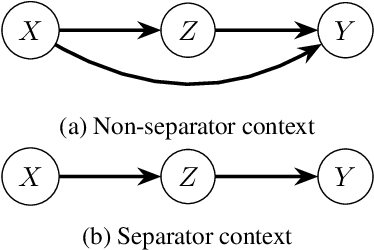
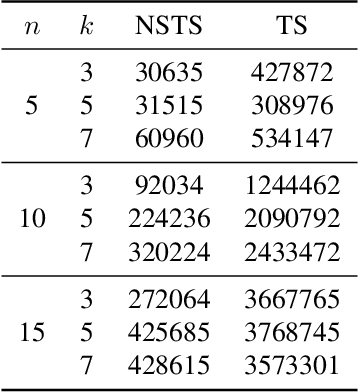
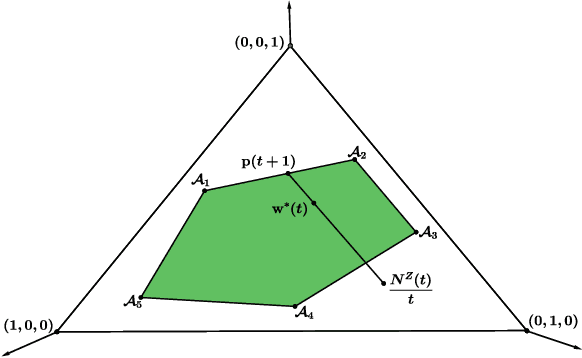
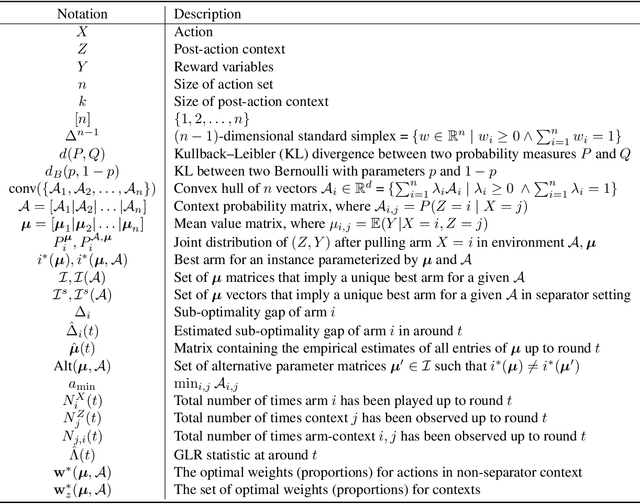
We introduce the problem of best arm identification (BAI) with post-action context, a new BAI problem in a stochastic multi-armed bandit environment and the fixed-confidence setting. The problem addresses the scenarios in which the learner receives a $\textit{post-action context}$ in addition to the reward after playing each action. This post-action context provides additional information that can significantly facilitate the decision process. We analyze two different types of the post-action context: (i) $\textit{non-separator}$, where the reward depends on both the action and the context, and (ii) $\textit{separator}$, where the reward depends solely on the context. For both cases, we derive instance-dependent lower bounds on the sample complexity and propose algorithms that asymptotically achieve the optimal sample complexity. For the non-separator setting, we do so by demonstrating that the Track-and-Stop algorithm can be extended to this setting. For the separator setting, we propose a novel sampling rule called $\textit{G-tracking}$, which uses the geometry of the context space to directly track the contexts rather than the actions. Finally, our empirical results showcase the advantage of our approaches compared to the state of the art.