 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLRW-Persian: Lip-reading in the Wild Dataset for Persian Language
Oct 26, 2025Lipreading has emerged as an increasingly important research area for developing robust speech recognition systems and assistive technologies for the hearing-impaired. However, non-English resources for visual speech recognition remain limited. We introduce LRW-Persian, the largest in-the-wild Persian word-level lipreading dataset, comprising $743$ target words and over $414{,}000$ video samples extracted from more than $1{,}900$ hours of footage across $67$ television programs. Designed as a benchmark-ready resource, LRW-Persian provides speaker-disjoint training and test splits, wide regional and dialectal coverage, and rich per-clip metadata including head pose, age, and gender. To ensure large-scale data quality, we establish a fully automated end-to-end curation pipeline encompassing transcription based on Automatic Speech Recognition(ASR), active-speaker localization, quality filtering, and pose/mask screening. We further fine-tune two widely used lipreading architectures on LRW-Persian, establishing reference performance and demonstrating the difficulty of Persian visual speech recognition. By filling a critical gap in low-resource languages, LRW-Persian enables rigorous benchmarking, supports cross-lingual transfer, and provides a foundation for advancing multimodal speech research in underrepresented linguistic contexts. The dataset is publicly available at: https://lrw-persian.vercel.app.
Learning Peer Influence Probabilities with Linear Contextual Bandits
Oct 21, 2025In networked environments, users frequently share recommendations about content, products, services, and courses of action with others. The extent to which such recommendations are successful and adopted is highly contextual, dependent on the characteristics of the sender, recipient, their relationship, the recommended item, and the medium, which makes peer influence probabilities highly heterogeneous. Accurate estimation of these probabilities is key to understanding information diffusion processes and to improving the effectiveness of viral marketing strategies. However, learning these probabilities from data is challenging; static data may capture correlations between peer recommendations and peer actions but fails to reveal influence relationships. Online learning algorithms can learn these probabilities from interventions but either waste resources by learning from random exploration or optimize for rewards, thus favoring exploration of the space with higher influence probabilities. In this work, we study learning peer influence probabilities under a contextual linear bandit framework. We show that a fundamental trade-off can arise between regret minimization and estimation error, characterize all achievable rate pairs, and propose an uncertainty-guided exploration algorithm that, by tuning a parameter, attains any pair within this trade-off. Our experiments on semi-synthetic network datasets show the advantages of our method over static methods and contextual bandits that ignore this trade-off.
Best Group Identification in Multi-Objective Bandits
May 23, 2025We introduce the Best Group Identification problem in a multi-objective multi-armed bandit setting, where an agent interacts with groups of arms with vector-valued rewards. The performance of a group is determined by an efficiency vector which represents the group's best attainable rewards across different dimensions. The objective is to identify the set of optimal groups in the fixed-confidence setting. We investigate two key formulations: group Pareto set identification, where efficiency vectors of optimal groups are Pareto optimal and linear best group identification, where each reward dimension has a known weight and the optimal group maximizes the weighted sum of its efficiency vector's entries. For both settings, we propose elimination-based algorithms, establish upper bounds on their sample complexity, and derive lower bounds that apply to any correct algorithm. Through numerical experiments, we demonstrate the strong empirical performance of the proposed algorithms.
Graph-Dependent Regret Bounds in Multi-Armed Bandits with Interference
Mar 10, 2025Multi-armed bandits (MABs) are frequently used for online sequential decision-making in applications ranging from recommending personalized content to assigning treatments to patients. A recurring challenge in the applicability of the classic MAB framework to real-world settings is ignoring \textit{interference}, where a unit's outcome depends on treatment assigned to others. This leads to an exponentially growing action space, rendering standard approaches computationally impractical. We study the MAB problem under network interference, where each unit's reward depends on its own treatment and those of its neighbors in a given interference graph. We propose a novel algorithm that uses the local structure of the interference graph to minimize regret. We derive a graph-dependent upper bound on cumulative regret showing that it improves over prior work. Additionally, we provide the first lower bounds for bandits with arbitrary network interference, where each bound involves a distinct structural property of the interference graph. These bounds demonstrate that when the graph is either dense or sparse, our algorithm is nearly optimal, with upper and lower bounds that match up to logarithmic factors. We complement our theoretical results with numerical experiments, which show that our approach outperforms baseline methods.
Optimal Best Arm Identification with Post-Action Context
Feb 05, 2025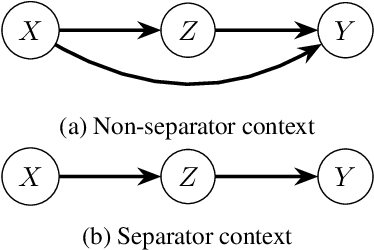
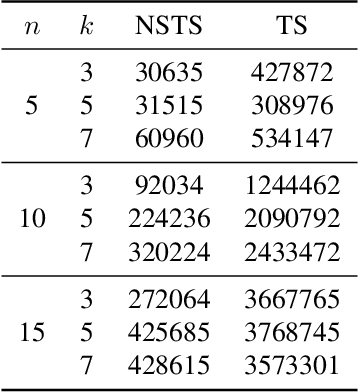
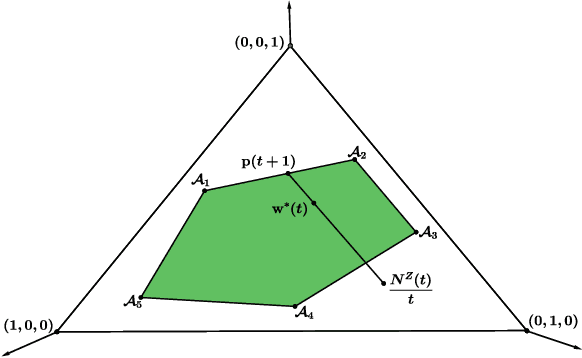
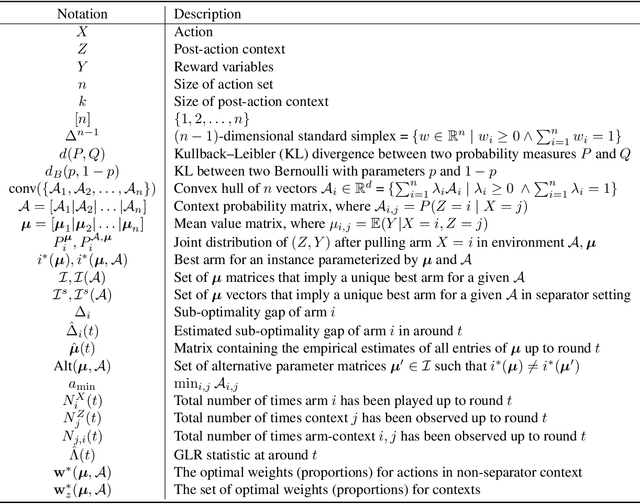
We introduce the problem of best arm identification (BAI) with post-action context, a new BAI problem in a stochastic multi-armed bandit environment and the fixed-confidence setting. The problem addresses the scenarios in which the learner receives a $\textit{post-action context}$ in addition to the reward after playing each action. This post-action context provides additional information that can significantly facilitate the decision process. We analyze two different types of the post-action context: (i) $\textit{non-separator}$, where the reward depends on both the action and the context, and (ii) $\textit{separator}$, where the reward depends solely on the context. For both cases, we derive instance-dependent lower bounds on the sample complexity and propose algorithms that asymptotically achieve the optimal sample complexity. For the non-separator setting, we do so by demonstrating that the Track-and-Stop algorithm can be extended to this setting. For the separator setting, we propose a novel sampling rule called $\textit{G-tracking}$, which uses the geometry of the context space to directly track the contexts rather than the actions. Finally, our empirical results showcase the advantage of our approaches compared to the state of the art.
QWO: Speeding Up Permutation-Based Causal Discovery in LiGAMs
Oct 30, 2024Causal discovery is essential for understanding relationships among variables of interest in many scientific domains. In this paper, we focus on permutation-based methods for learning causal graphs in Linear Gaussian Acyclic Models (LiGAMs), where the permutation encodes a causal ordering of the variables. Existing methods in this setting are not scalable due to their high computational complexity. These methods are comprised of two main components: (i) constructing a specific DAG, $\mathcal{G}^\pi$, for a given permutation $\pi$, which represents the best structure that can be learned from the available data while adhering to $\pi$, and (ii) searching over the space of permutations (i.e., causal orders) to minimize the number of edges in $\mathcal{G}^\pi$. We introduce QWO, a novel approach that significantly enhances the efficiency of computing $\mathcal{G}^\pi$ for a given permutation $\pi$. QWO has a speed-up of $O(n^2)$ ($n$ is the number of variables) compared to the state-of-the-art BIC-based method, making it highly scalable. We show that our method is theoretically sound and can be integrated into existing search strategies such as GRASP and hill-climbing-based methods to improve their performance.