 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Causal Nature of Sentiment Analysis
Apr 17, 2024


Sentiment analysis (SA) aims to identify the sentiment expressed in a text, such as a product review. Given a review and the sentiment associated with it, this paper formulates SA as a combination of two tasks: (1) a causal discovery task that distinguishes whether a review "primes" the sentiment (Causal Hypothesis C1), or the sentiment "primes" the review (Causal Hypothesis C2); and (2) the traditional prediction task to model the sentiment using the review as input. Using the peak-end rule in psychology, we classify a sample as C1 if its overall sentiment score approximates an average of all the sentence-level sentiments in the review, and C2 if the overall sentiment score approximates an average of the peak and end sentiments. For the prediction task, we use the discovered causal mechanisms behind the samples to improve the performance of LLMs by proposing causal prompts that give the models an inductive bias of the underlying causal graph, leading to substantial improvements by up to 32.13 F1 points on zero-shot five-class SA. Our code is at https://github.com/cogito233/causal-sa
CausalCite: A Causal Formulation of Paper Citations
Nov 05, 2023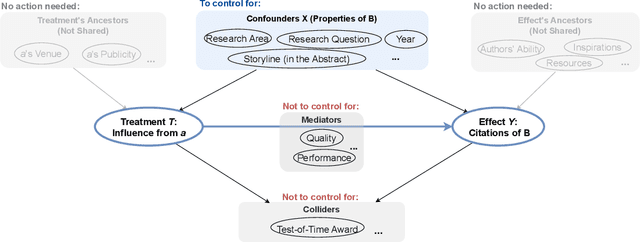


Evaluating the significance of a paper is pivotal yet challenging for the scientific community. While the citation count is the most commonly used proxy for this purpose, they are widely criticized for failing to accurately reflect a paper's true impact. In this work, we propose a causal inference method, TextMatch, which adapts the traditional matching framework to high-dimensional text embeddings. Specifically, we encode each paper using the text embeddings by large language models (LLMs), extract similar samples by cosine similarity, and synthesize a counterfactual sample by the weighted average of similar papers according to their similarity values. We apply the resulting metric, called CausalCite, as a causal formulation of paper citations. We show its effectiveness on various criteria, such as high correlation with paper impact as reported by scientific experts on a previous dataset of 1K papers, (test-of-time) awards for past papers, and its stability across various sub-fields of AI. We also provide a set of findings that can serve as suggested ways for future researchers to use our metric for a better understanding of a paper's quality. Our code and data are at https://github.com/causalNLP/causal-cite.
Voices of Her: Analyzing Gender Differences in the AI Publication World
May 24, 2023



While several previous studies have analyzed gender bias in research, we are still missing a comprehensive analysis of gender differences in the AI community, covering diverse topics and different development trends. Using the AI Scholar dataset of 78K researchers in the field of AI, we identify several gender differences: (1) Although female researchers tend to have fewer overall citations than males, this citation difference does not hold for all academic-age groups; (2) There exist large gender homophily in co-authorship on AI papers; (3) Female first-authored papers show distinct linguistic styles, such as longer text, more positive emotion words, and more catchy titles than male first-authored papers. Our analysis provides a window into the current demographic trends in our AI community, and encourages more gender equality and diversity in the future. Our code and data are at https://github.com/causalNLP/ai-scholar-gender.
Psychologically-Inspired Causal Prompts
May 02, 2023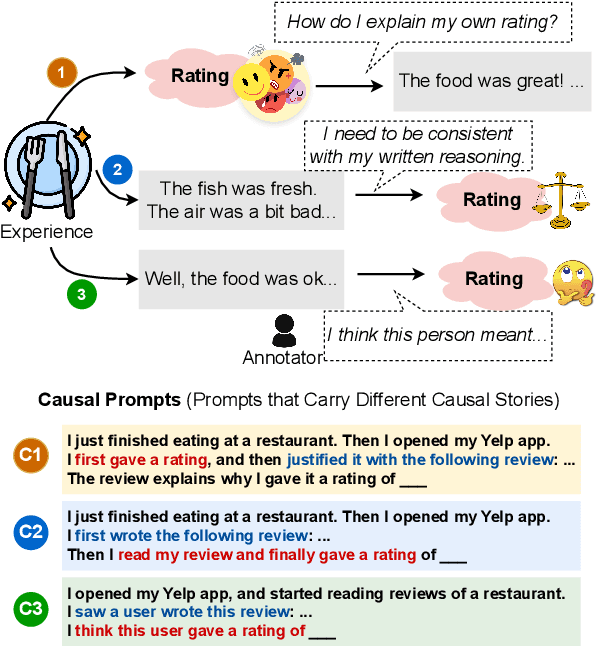


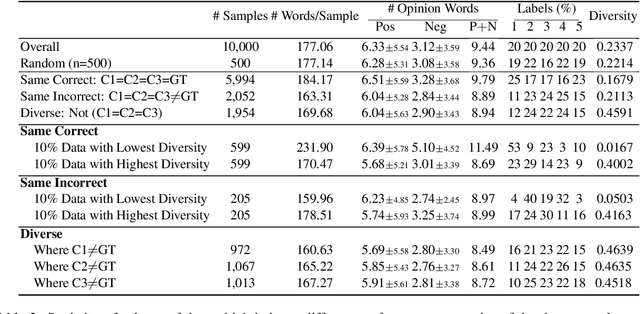
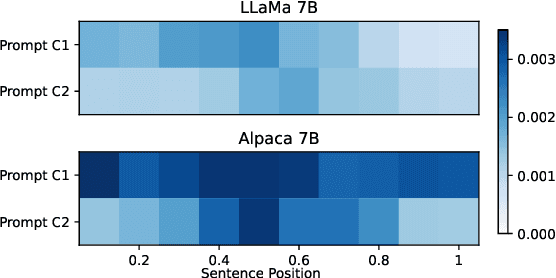
NLP datasets are richer than just input-output pairs; rather, they carry causal relations between the input and output variables. In this work, we take sentiment classification as an example and look into the causal relations between the review (X) and sentiment (Y). As psychology studies show that language can affect emotion, different psychological processes are evoked when a person first makes a rating and then self-rationalizes their feeling in a review (where the sentiment causes the review, i.e., Y -> X), versus first describes their experience, and weighs the pros and cons to give a final rating (where the review causes the sentiment, i.e., X -> Y ). Furthermore, it is also a completely different psychological process if an annotator infers the original rating of the user by theory of mind (ToM) (where the review causes the rating, i.e., X -ToM-> Y ). In this paper, we verbalize these three causal mechanisms of human psychological processes of sentiment classification into three different causal prompts, and study (1) how differently they perform, and (2) what nature of sentiment classification data leads to agreement or diversity in the model responses elicited by the prompts. We suggest future work raise awareness of different causal structures in NLP tasks. Our code and data are at https://github.com/cogito233/psych-causal-prompt
Differentially Private Language Models for Secure Data Sharing
Oct 26, 2022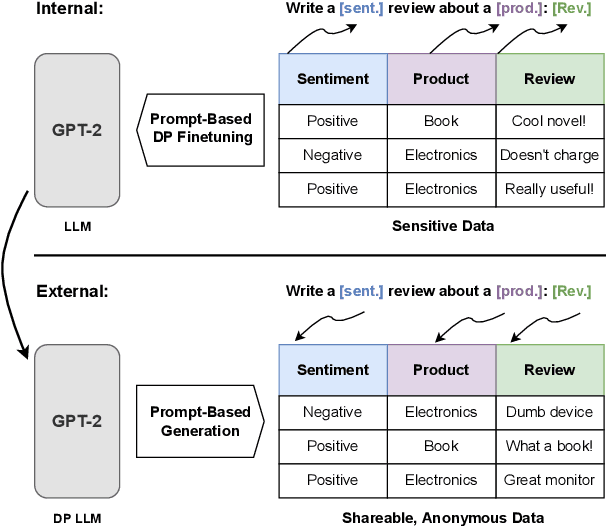
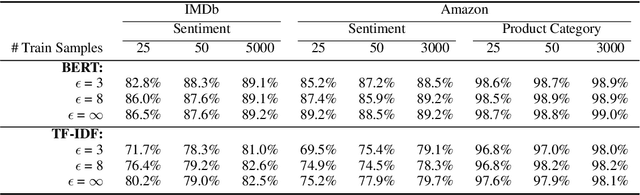

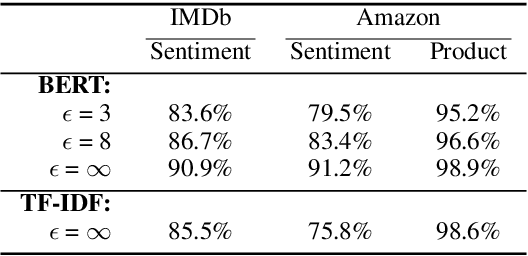
To protect the privacy of individuals whose data is being shared, it is of high importance to develop methods allowing researchers and companies to release textual data while providing formal privacy guarantees to its originators. In the field of NLP, substantial efforts have been directed at building mechanisms following the framework of local differential privacy, thereby anonymizing individual text samples before releasing them. In practice, these approaches are often dissatisfying in terms of the quality of their output language due to the strong noise required for local differential privacy. In this paper, we approach the problem at hand using global differential privacy, particularly by training a generative language model in a differentially private manner and consequently sampling data from it. Using natural language prompts and a new prompt-mismatch loss, we are able to create highly accurate and fluent textual datasets taking on specific desired attributes such as sentiment or topic and resembling statistical properties of the training data. We perform thorough experiments indicating that our synthetic datasets do not leak information from our original data and are of high language quality and highly suitable for training models for further analysis on real-world data. Notably, we also demonstrate that training classifiers on private synthetic data outperforms directly training classifiers on real data with DP-SGD.
From Deterministic ODEs to Dynamic Structural Causal Models
Jul 09, 2018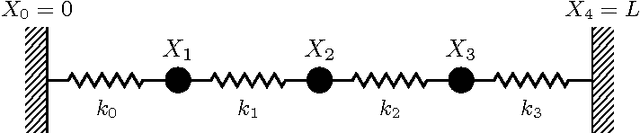
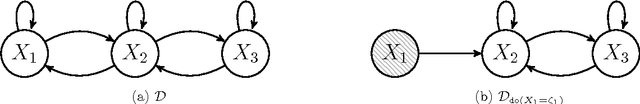


Structural Causal Models are widely used in causal modelling, but how they relate to other modelling tools is poorly understood. In this paper we provide a novel perspective on the relationship between Ordinary Differential Equations and Structural Causal Models. We show how, under certain conditions, the asymptotic behaviour of an Ordinary Differential Equation under non-constant interventions can be modelled using Dynamic Structural Causal Models. In contrast to earlier work, we study not only the effect of interventions on equilibrium states; rather, we model asymptotic behaviour that is dynamic under interventions that vary in time, and include as a special case the study of static equilibria.
Causal inference for cloud computing
Mar 13, 2018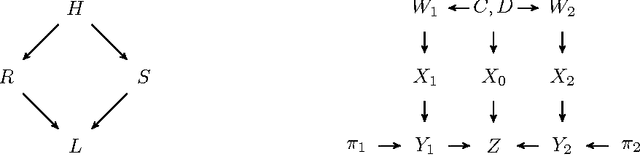
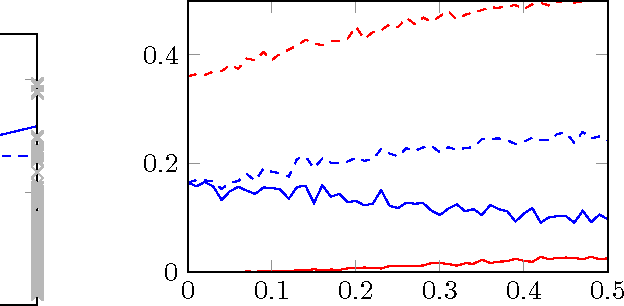
Cloud computing involves complex technical and economical systems and interactions. This brings about various challenges, two of which are: (1) debugging and control of computing systems with the help of sandbox experiments, and (2) prediction of the cost of "spot" resources for decision making of cloud clients. In this paper, we formalize debugging by counterfactual probabilities and control by post-(soft-)interventional probabilities. We prove that counterfactuals can approximately be calculated from a "stochastic" graphical causal model (while they are originally defined only for "deterministic" functional causal models), and based on this sketch an approach to address problem (1). To address problem (2), we formalize bidding by post-(soft-)interventional probabilities and present a simple mathematical result on approximate integration of "incomplete" conditional probability distributions. We show how this can be used by cloud clients to trade off privacy against predictability of the outcome of their bidding actions in a toy scenario. We report experiments on simulated and real data.
Wasserstein Auto-Encoders
Mar 12, 2018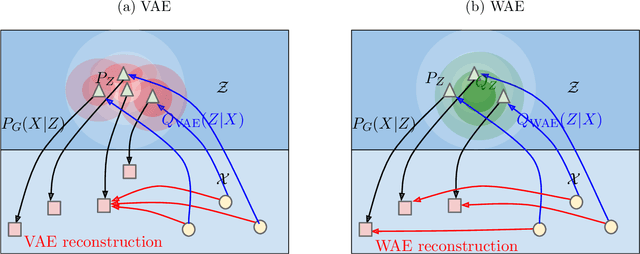



We propose the Wasserstein Auto-Encoder (WAE)---a new algorithm for building a generative model of the data distribution. WAE minimizes a penalized form of the Wasserstein distance between the model distribution and the target distribution, which leads to a different regularizer than the one used by the Variational Auto-Encoder (VAE). This regularizer encourages the encoded training distribution to match the prior. We compare our algorithm with several other techniques and show that it is a generalization of adversarial auto-encoders (AAE). Our experiments show that WAE shares many of the properties of VAEs (stable training, encoder-decoder architecture, nice latent manifold structure) while generating samples of better quality, as measured by the FID score.
Optimizing Human Learning
Mar 10, 2018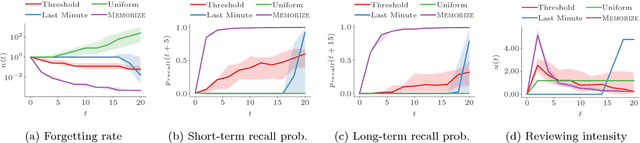
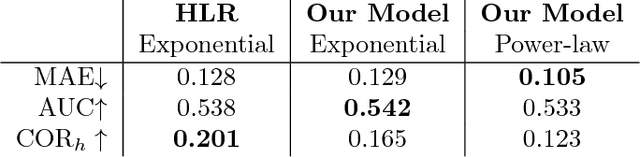

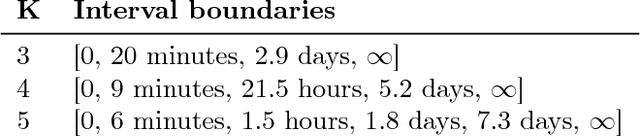
Spaced repetition is a technique for efficient memorization which uses repeated, spaced review of content to improve long-term retention. Can we find the optimal reviewing schedule to maximize the benefits of spaced repetition? In this paper, we introduce a novel, flexible representation of spaced repetition using the framework of marked temporal point processes and then address the above question as an optimal control problem for stochastic differential equations with jumps. For two well-known human memory models, we show that the optimal reviewing schedule is given by the recall probability of the content to be learned. As a result, we can then develop a simple, scalable online algorithm, Memorize, to sample the optimal reviewing times. Experiments on both synthetic and real data gathered from Duolingo, a popular language-learning online platform, show that our algorithm may be able to help learners memorize more effectively than alternatives.
Detecting non-causal artifacts in multivariate linear regression models
Mar 02, 2018


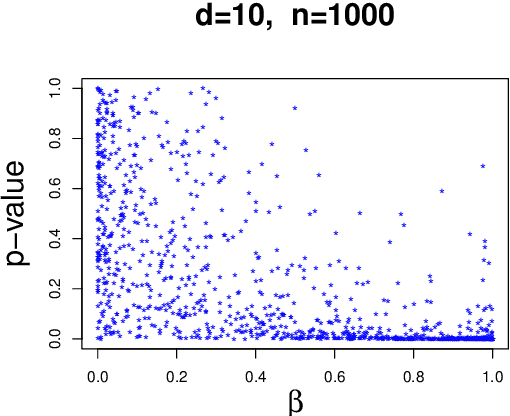
We consider linear models where $d$ potential causes $X_1,...,X_d$ are correlated with one target quantity $Y$ and propose a method to infer whether the association is causal or whether it is an artifact caused by overfitting or hidden common causes. We employ the idea that in the former case the vector of regression coefficients has 'generic' orientation relative to the covariance matrix $\Sigma_{XX}$ of $X$. Using an ICA based model for confounding, we show that both confounding and overfitting yield regression vectors that concentrate mainly in the space of low eigenvalues of $\Sigma_{XX}$.