 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Decision Making Under Strategic Behavior
May 22, 2019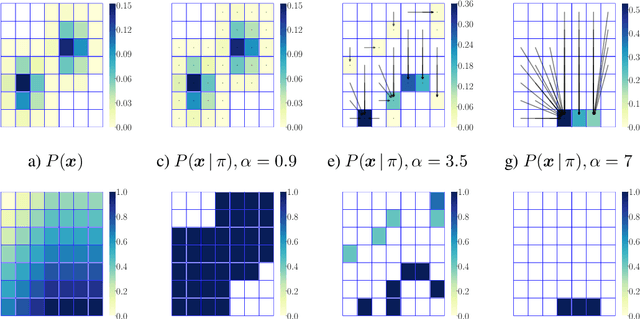
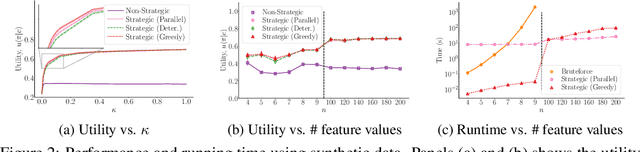
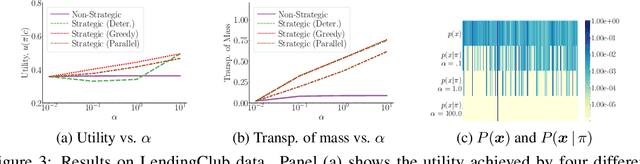
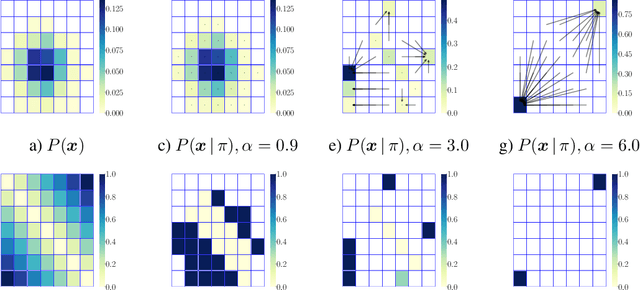
We are witnessing an increasing use of data-driven predictive models to inform decisions. As decisions have implications for individuals and society, there is increasing pressure on decision makers to be transparent about their decision policies, models, and the features they use. At the same time, individuals may use knowledge, gained by transparency, to invest effort strategically in order to maximize their chances of receiving a beneficial decision. In this paper, our goal is to find decision policies that are optimal in terms of utility in such a strategic setting. To this end, we first use the theory of optimal transport to characterize how strategic investment of effort by individuals leads to a change in the feature distribution at a population level. Then, we show that, in contrast with the non-strategic setting, optimal decision policies are stochastic, and we cannot expect to find them in polynomial time. Finally, we derive an efficient greedy algorithm that is guaranteed to find locally optimal decision policies in polynomial time. Experiments on synthetic and real lending data illustrate our theoretical findings and show that the decision policies found by our greedy algorithm achieve higher utility than deterministic threshold rules, which are optimal policies in a non-strategic setting.
Consequential Ranking Algorithms and Long-term Welfare
May 13, 2019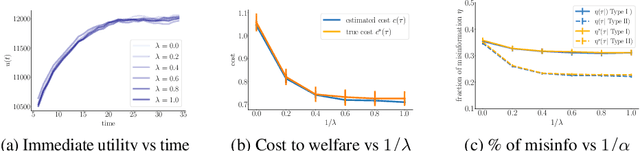



Ranking models are typically designed to provide rankings that optimize some measure of immediate utility to the users. As a result, they have been unable to anticipate an increasing number of undesirable long-term consequences of their proposed rankings, from fueling the spread of misinformation and increasing polarization to degrading social discourse. Can we design ranking models that understand the consequences of their proposed rankings and, more importantly, are able to avoid the undesirable ones? In this paper, we first introduce a joint representation of rankings and user dynamics using Markov decision processes. Then, we show that this representation greatly simplifies the construction of consequential ranking models that trade off the immediate utility and the long-term welfare. In particular, we can obtain optimal consequential rankings just by applying weighted sampling on the rankings provided by models that maximize measures of immediate utility. However, in practice, such a strategy may be inefficient and impractical, specially in high dimensional scenarios. To overcome this, we introduce an efficient gradient-based algorithm to learn parameterized consequential ranking models that effectively approximate optimal ones. We showcase our methodology using synthetic and real data gathered from Reddit and show that ranking models derived using our methodology provide ranks that may mitigate the spread of misinformation and improve the civility of online discussions.
Optimizing Human Learning
Mar 10, 2018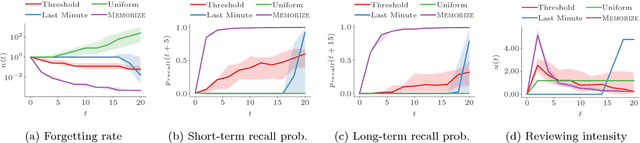
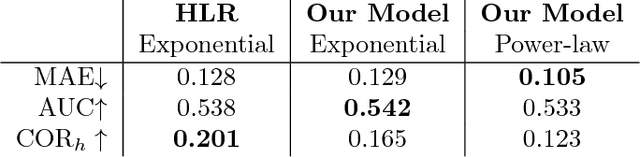

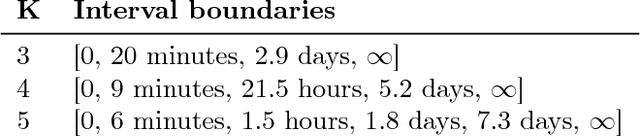
Spaced repetition is a technique for efficient memorization which uses repeated, spaced review of content to improve long-term retention. Can we find the optimal reviewing schedule to maximize the benefits of spaced repetition? In this paper, we introduce a novel, flexible representation of spaced repetition using the framework of marked temporal point processes and then address the above question as an optimal control problem for stochastic differential equations with jumps. For two well-known human memory models, we show that the optimal reviewing schedule is given by the recall probability of the content to be learned. As a result, we can then develop a simple, scalable online algorithm, Memorize, to sample the optimal reviewing times. Experiments on both synthetic and real data gathered from Duolingo, a popular language-learning online platform, show that our algorithm may be able to help learners memorize more effectively than alternatives.
Leveraging the Crowd to Detect and Reduce the Spread of Fake News and Misinformation
Nov 27, 2017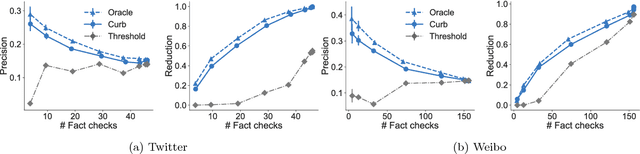
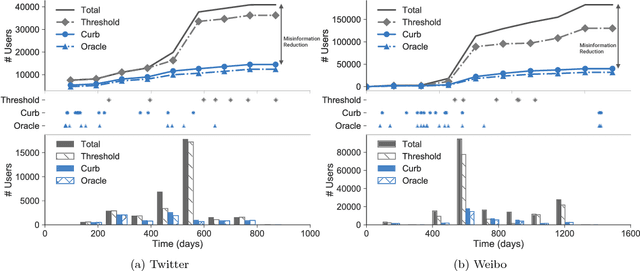
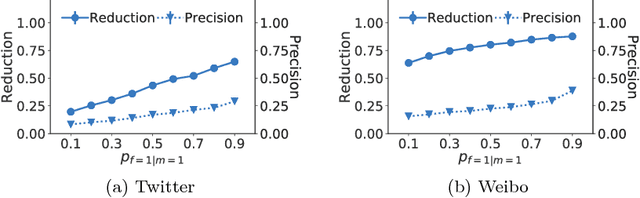
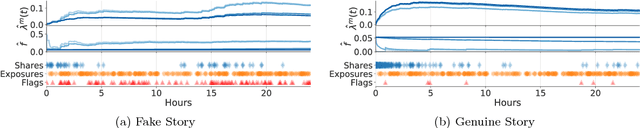
Online social networking sites are experimenting with the following crowd-powered procedure to reduce the spread of fake news and misinformation: whenever a user is exposed to a story through her feed, she can flag the story as misinformation and, if the story receives enough flags, it is sent to a trusted third party for fact checking. If this party identifies the story as misinformation, it is marked as disputed. However, given the uncertain number of exposures, the high cost of fact checking, and the trade-off between flags and exposures, the above mentioned procedure requires careful reasoning and smart algorithms which, to the best of our knowledge, do not exist to date. In this paper, we first introduce a flexible representation of the above procedure using the framework of marked temporal point processes. Then, we develop a scalable online algorithm, Curb, to select which stories to send for fact checking and when to do so to efficiently reduce the spread of misinformation with provable guarantees. In doing so, we need to solve a novel stochastic optimal control problem for stochastic differential equations with jumps, which is of independent interest. Experiments on two real-world datasets gathered from Twitter and Weibo show that our algorithm may be able to effectively reduce the spread of fake news and misinformation.
Distilling Information Reliability and Source Trustworthiness from Digital Traces
Apr 02, 2017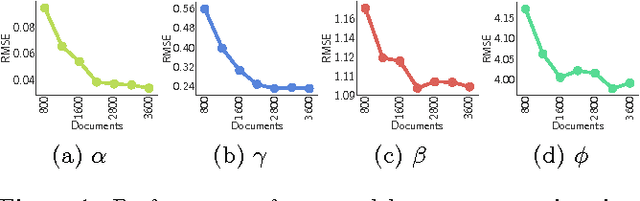
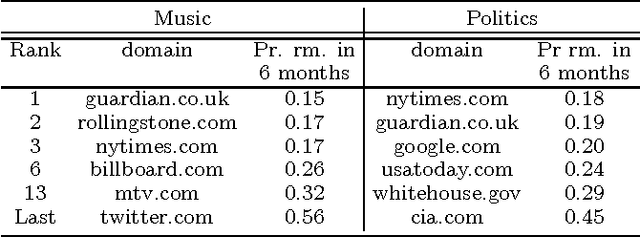
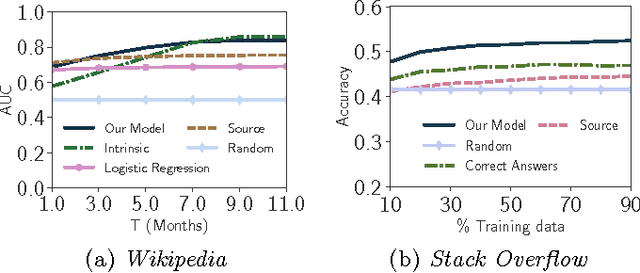
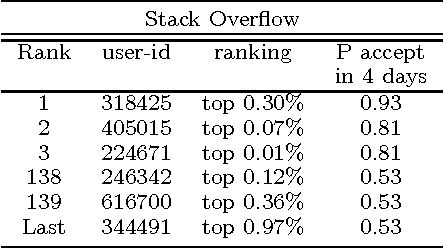
Online knowledge repositories typically rely on their users or dedicated editors to evaluate the reliability of their content. These evaluations can be viewed as noisy measurements of both information reliability and information source trustworthiness. Can we leverage these noisy evaluations, often biased, to distill a robust, unbiased and interpretable measure of both notions? In this paper, we argue that the temporal traces left by these noisy evaluations give cues on the reliability of the information and the trustworthiness of the sources. Then, we propose a temporal point process modeling framework that links these temporal traces to robust, unbiased and interpretable notions of information reliability and source trustworthiness. Furthermore, we develop an efficient convex optimization procedure to learn the parameters of the model from historical traces. Experiments on real-world data gathered from Wikipedia and Stack Overflow show that our modeling framework accurately predicts evaluation events, provides an interpretable measure of information reliability and source trustworthiness, and yields interesting insights about real-world events.