 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification Under Human Assistance
Jun 21, 2020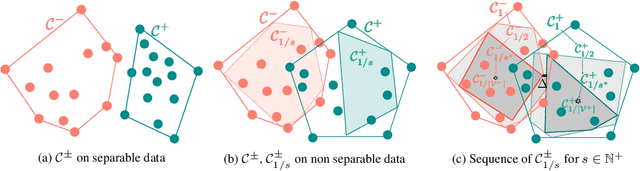
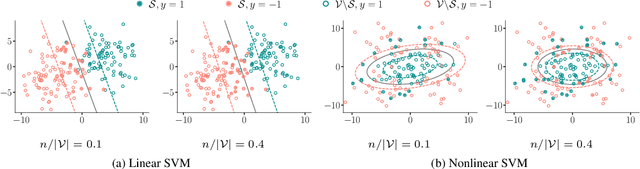
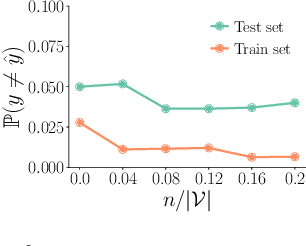
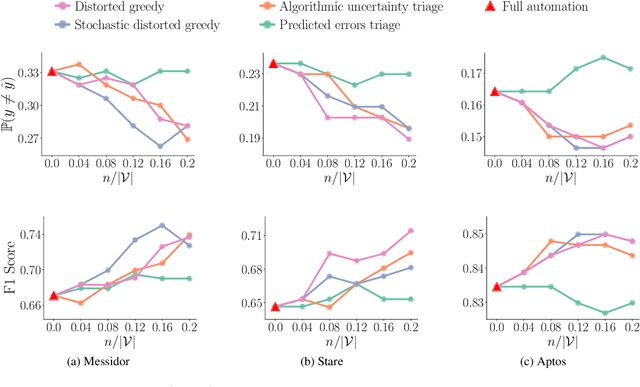
Most supervised learning models are trained for full automation. However, their predictions are sometimes worse than those by human experts on some specific instances. Motivated by this empirical observation, our goal is to design classifiers that are optimized to operate under different automation levels. More specifically, we focus on convex margin-based classifiers and first show that the problem is NP-hard. Then, we further show that, for support vector machines, the corresponding objective function can be expressed as the difference of two functions f = g - c, where g is monotone, non-negative and {\gamma}-weakly submodular, and c is non-negative and modular. This representation allows a recently introduced deterministic greedy algorithm, as well as a more efficient randomized variant of the algorithm, to enjoy approximation guarantees at solving the problem. Experiments on synthetic and real-world data from several applications in medical diagnosis illustrate our theoretical findings and demonstrate that, under human assistance, supervised learning models trained to operate under different automation levels can outperform those trained for full automation as well as humans operating alone.
Optimizing Human Learning
Mar 10, 2018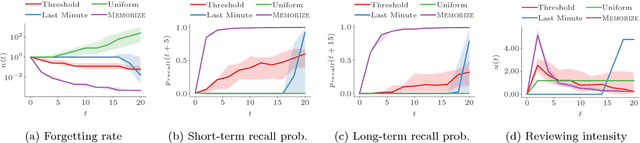
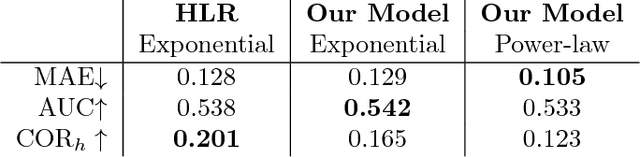

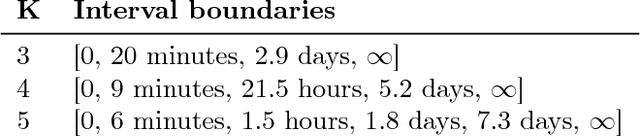
Spaced repetition is a technique for efficient memorization which uses repeated, spaced review of content to improve long-term retention. Can we find the optimal reviewing schedule to maximize the benefits of spaced repetition? In this paper, we introduce a novel, flexible representation of spaced repetition using the framework of marked temporal point processes and then address the above question as an optimal control problem for stochastic differential equations with jumps. For two well-known human memory models, we show that the optimal reviewing schedule is given by the recall probability of the content to be learned. As a result, we can then develop a simple, scalable online algorithm, Memorize, to sample the optimal reviewing times. Experiments on both synthetic and real data gathered from Duolingo, a popular language-learning online platform, show that our algorithm may be able to help learners memorize more effectively than alternatives.
Steering Social Activity: A Stochastic Optimal Control Point Of View
Feb 19, 2018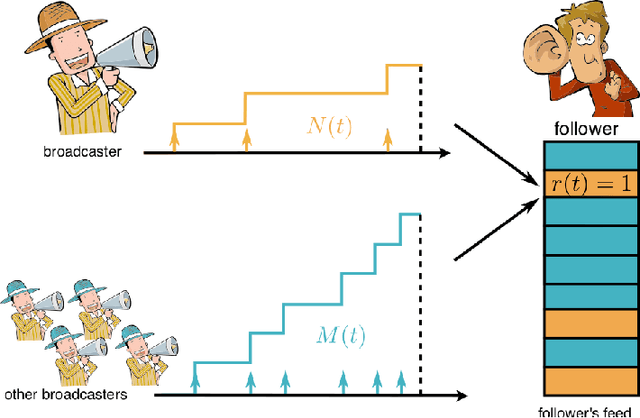
User engagement in online social networking depends critically on the level of social activity in the corresponding platform--the number of online actions, such as posts, shares or replies, taken by their users. Can we design data-driven algorithms to increase social activity? At a user level, such algorithms may increase activity by helping users decide when to take an action to be more likely to be noticed by their peers. At a network level, they may increase activity by incentivizing a few influential users to take more actions, which in turn will trigger additional actions by other users. In this paper, we model social activity using the framework of marked temporal point processes, derive an alternate representation of these processes using stochastic differential equations (SDEs) with jumps and, exploiting this alternate representation, develop two efficient online algorithms with provable guarantees to steer social activity both at a user and at a network level. In doing so, we establish a previously unexplored connection between optimal control of jump SDEs and doubly stochastic marked temporal point processes, which is of independent interest. Finally, we experiment both with synthetic and real data gathered from Twitter and show that our algorithms consistently steer social activity more effectively than the state of the art.
Spatio-Temporal Modeling of Users' Check-ins in Location-Based Social Networks
Apr 10, 2017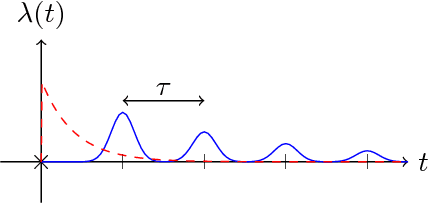
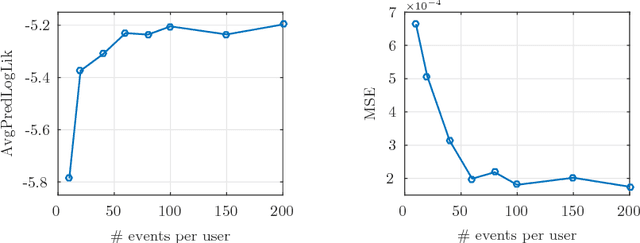
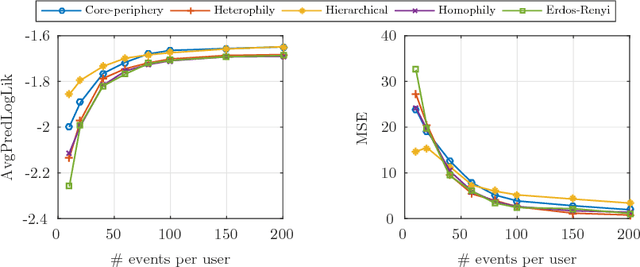
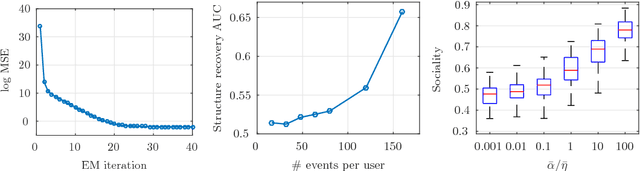
Social networks are getting closer to our real physical world. People share the exact location and time of their check-ins and are influenced by their friends. Modeling the spatio-temporal behavior of users in social networks is of great importance for predicting the future behavior of users, controlling the users' movements, and finding the latent influence network. It is observed that users have periodic patterns in their movements. Also, they are influenced by the locations that their close friends recently visited. Leveraging these two observations, we propose a probabilistic model based on a doubly stochastic point process with a periodic decaying kernel for the time of check-ins and a time-varying multinomial distribution for the location of check-ins of users in the location-based social networks. We learn the model parameters using an efficient EM algorithm, which distributes over the users. Experiments on synthetic and real data gathered from Foursquare show that the proposed inference algorithm learns the parameters efficiently and our model outperforms the other alternatives in the prediction of time and location of check-ins.
Cheshire: An Online Algorithm for Activity Maximization in Social Networks
Mar 06, 2017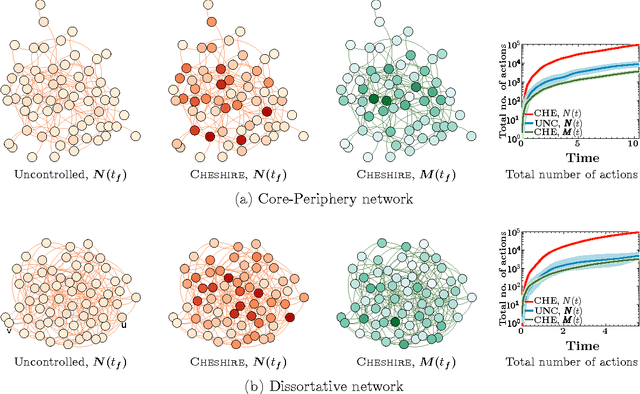
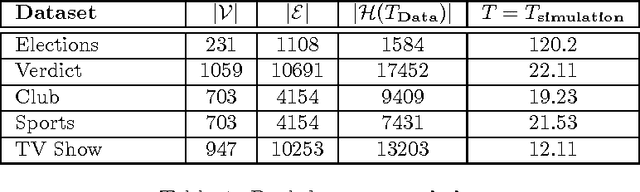
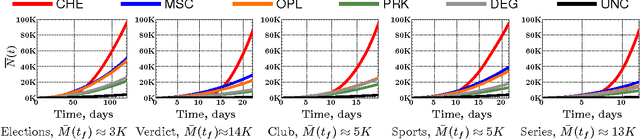
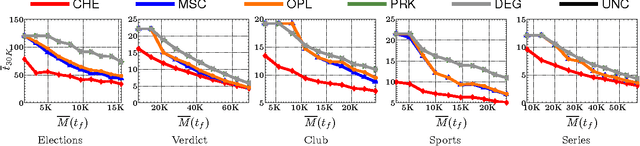
User engagement in social networks depends critically on the number of online actions their users take in the network. Can we design an algorithm that finds when to incentivize users to take actions to maximize the overall activity in a social network? In this paper, we model the number of online actions over time using multidimensional Hawkes processes, derive an alternate representation of these processes based on stochastic differential equations (SDEs) with jumps and, exploiting this alternate representation, address the above question from the perspective of stochastic optimal control of SDEs with jumps. We find that the optimal level of incentivized actions depends linearly on the current level of overall actions. Moreover, the coefficients of this linear relationship can be found by solving a matrix Riccati differential equation, which can be solved efficiently, and a first order differential equation, which has a closed form solution. As a result, we are able to design an efficient online algorithm, Cheshire, to sample the optimal times of the users' incentivized actions. Experiments on both synthetic and real data gathered from Twitter show that our algorithm is able to consistently maximize the number of online actions more effectively than the state of the art.
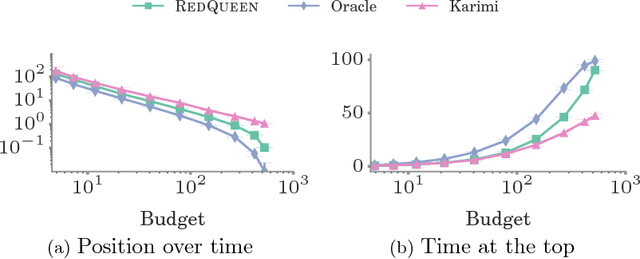
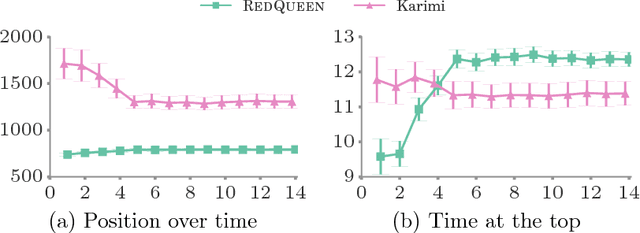
RedQueen: An Online Algorithm for Smart Broadcasting in Social Networks
Oct 18, 2016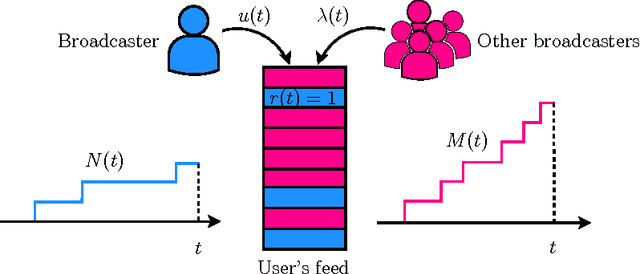
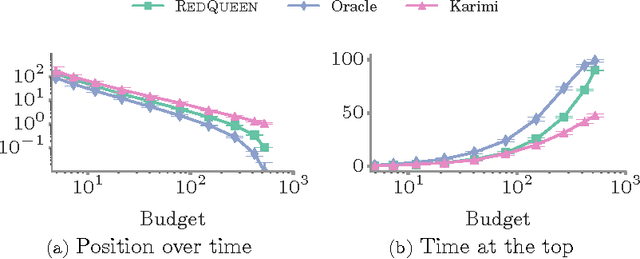
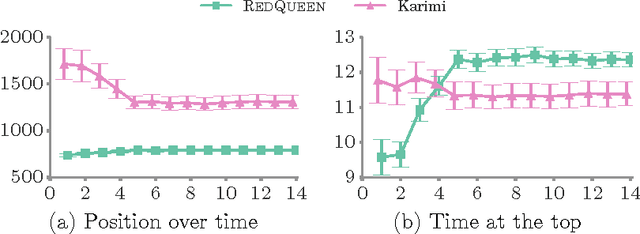
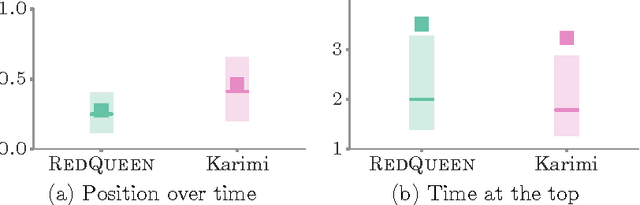
Users in social networks whose posts stay at the top of their followers'{} feeds the longest time are more likely to be noticed. Can we design an online algorithm to help them decide when to post to stay at the top? In this paper, we address this question as a novel optimal control problem for jump stochastic differential equations. For a wide variety of feed dynamics, we show that the optimal broadcasting intensity for any user is surprisingly simple -- it is given by the position of her most recent post on each of her follower's feeds. As a consequence, we are able to develop a simple and highly efficient online algorithm, RedQueen, to sample the optimal times for the user to post. Experiments on both synthetic and real data gathered from Twitter show that our algorithm is able to consistently make a user's posts more visible over time, is robust to volume changes on her followers' feeds, and significantly outperforms the state of the art.
Patchwise Joint Sparse Tracking with Occlusion Detection
Feb 05, 2014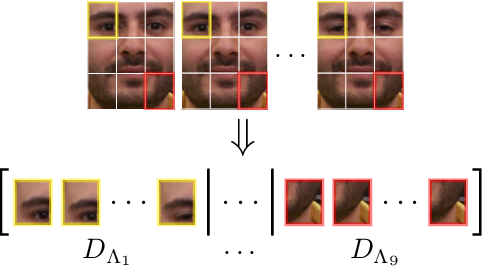
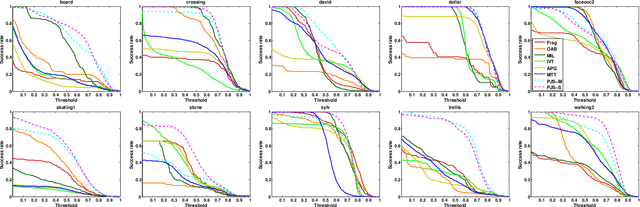
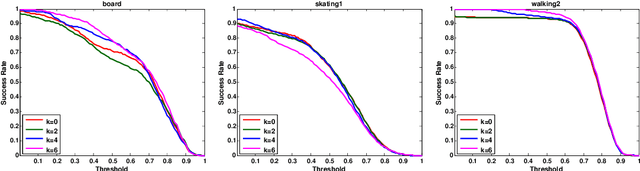
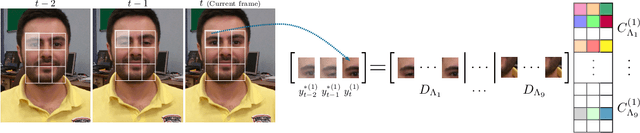
This paper presents a robust tracking approach to handle challenges such as occlusion and appearance change. Here, the target is partitioned into a number of patches. Then, the appearance of each patch is modeled using a dictionary composed of corresponding target patches in previous frames. In each frame, the target is found among a set of candidates generated by a particle filter, via a likelihood measure that is shown to be proportional to the sum of patch-reconstruction errors of each candidate. Since the target's appearance often changes slowly in a video sequence, it is assumed that the target in the current frame and the best candidates of a small number of previous frames, belong to a common subspace. This is imposed using joint sparse representation to enforce the target and previous best candidates to have a common sparsity pattern. Moreover, an occlusion detection scheme is proposed that uses patch-reconstruction errors and a prior probability of occlusion, extracted from an adaptive Markov chain, to calculate the probability of occlusion per patch. In each frame, occluded patches are excluded when updating the dictionary. Extensive experimental results on several challenging sequences shows that the proposed method outperforms state-of-the-art trackers.