 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Alignment Influences the Utility of AI-assisted Decision Making
Jan 23, 2025



Whenever an AI model is used to predict a relevant (binary) outcome in AI-assisted decision making, it is widely agreed that, together with each prediction, the model should provide an AI confidence value. However, it has been unclear why decision makers have often difficulties to develop a good sense on when to trust a prediction using AI confidence values. Very recently, Corvelo Benz and Gomez Rodriguez have argued that, for rational decision makers, the utility of AI-assisted decision making is inherently bounded by the degree of alignment between the AI confidence values and the decision maker's confidence on their own predictions. In this work, we empirically investigate to what extent the degree of alignment actually influences the utility of AI-assisted decision making. To this end, we design and run a large-scale human subject study (n=703) where participants solve a simple decision making task - an online card game - assisted by an AI model with a steerable degree of alignment. Our results show a positive association between the degree of alignment and the utility of AI-assisted decision making. In addition, our results also show that post-processing the AI confidence values to achieve multicalibration with respect to the participants' confidence on their own predictions increases both the degree of alignment and the utility of AI-assisted decision making.
Controlling Counterfactual Harm in Decision Support Systems Based on Prediction Sets
Jun 10, 2024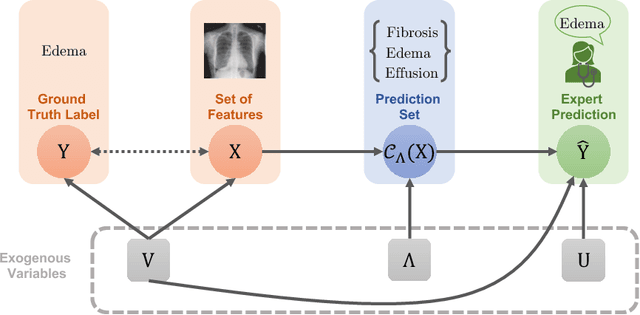
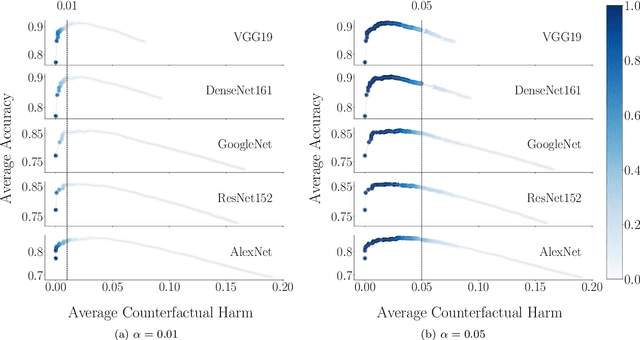
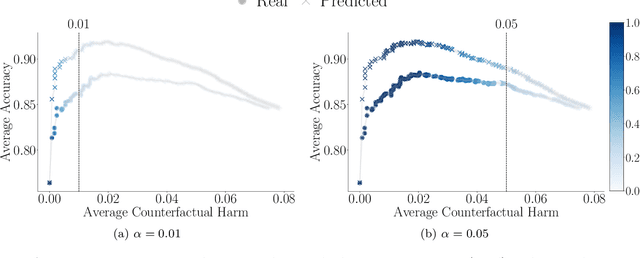
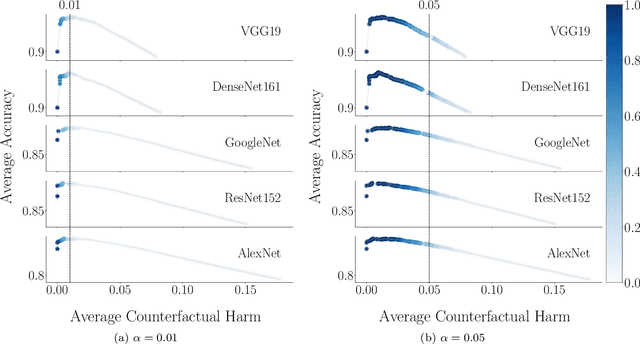
Decision support systems based on prediction sets help humans solve multiclass classification tasks by narrowing down the set of potential label values to a subset of them, namely a prediction set, and asking them to always predict label values from the prediction sets. While this type of systems have been proven to be effective at improving the average accuracy of the predictions made by humans, by restricting human agency, they may cause harm$\unicode{x2014}$a human who has succeeded at predicting the ground-truth label of an instance on their own may have failed had they used these systems. In this paper, our goal is to control how frequently a decision support system based on prediction sets may cause harm, by design. To this end, we start by characterizing the above notion of harm using the theoretical framework of structural causal models. Then, we show that, under a natural, albeit unverifiable, monotonicity assumption, we can estimate how frequently a system may cause harm using only predictions made by humans on their own. Further, we also show that, under a weaker monotonicity assumption, which can be verified experimentally, we can bound how frequently a system may cause harm again using only predictions made by humans on their own. Building upon these assumptions, we introduce a computational framework to design decision support systems based on prediction sets that are guaranteed to cause harm less frequently than a user-specified value using conformal risk control. We validate our framework using real human predictions from two different human subject studies and show that, in decision support systems based on prediction sets, there is a trade-off between accuracy and counterfactual harm.
Prediction-Powered Ranking of Large Language Models
Feb 27, 2024Large language models are often ranked according to their level of alignment with human preferences -- a model is better than other models if its outputs are more frequently preferred by humans. One of the most popular ways to elicit human preferences utilizes pairwise comparisons between the outputs provided by different models to the same inputs. However, since gathering pairwise comparisons by humans is costly and time-consuming, it has become a very common practice to gather pairwise comparisons by a strong large language model -- a model strongly aligned with human preferences. Surprisingly, practitioners cannot currently measure the uncertainty that any mismatch between human and model preferences may introduce in the constructed rankings. In this work, we develop a statistical framework to bridge this gap. Given a small set of pairwise comparisons by humans and a large set of pairwise comparisons by a model, our framework provides a rank-set -- a set of possible ranking positions -- for each of the models under comparison. Moreover, it guarantees that, with a probability greater than or equal to a user-specified value, the rank-sets cover the true ranking consistent with (the distribution of) human pairwise preferences. Our framework is computationally efficient, easy to use, and does not make any assumption about the distribution of human preferences nor about the degree of alignment between the pairwise comparisons by the humans and the strong large language model.
Designing Decision Support Systems Using Counterfactual Prediction Sets
Jun 06, 2023

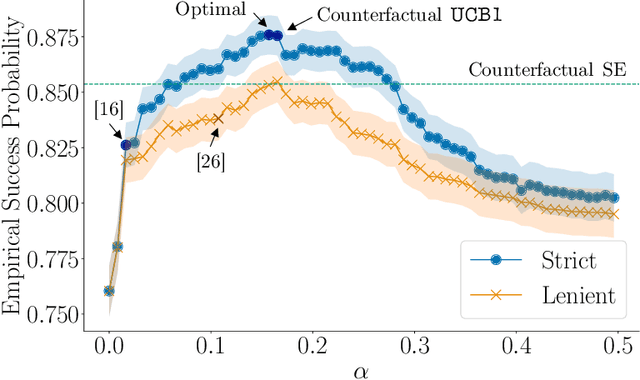

Decision support systems for classification tasks are predominantly designed to predict the value of the ground truth labels. However, since their predictions are not perfect, these systems also need to make human experts understand when and how to use these predictions to update their own predictions. Unfortunately, this has been proven challenging. In this context, it has been recently argued that an alternative type of decision support systems may circumvent this challenge. Rather than providing a single label prediction, these systems provide a set of label prediction values constructed using a conformal predictor, namely a prediction set, and forcefully ask experts to predict a label value from the prediction set. However, the design and evaluation of these systems have so far relied on stylized expert models, questioning their promise. In this paper, we revisit the design of this type of systems from the perspective of online learning and develop a methodology that does not require, nor assumes, an expert model. Our methodology leverages the nested structure of the prediction sets provided by any conformal predictor and a natural counterfactual monotonicity assumption on the experts' predictions over the prediction sets to achieve an exponential improvement in regret in comparison with vanilla bandit algorithms. We conduct a large-scale human subject study ($n = 2{,}751$) to verify our counterfactual monotonicity assumption and compare our methodology to several competitive baselines. The results suggest that decision support systems that limit experts' level of agency may be practical and may offer greater performance than those allowing experts to always exercise their own agency.
Human-Aligned Calibration for AI-Assisted Decision Making
May 31, 2023



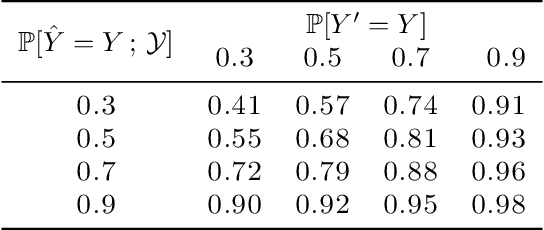
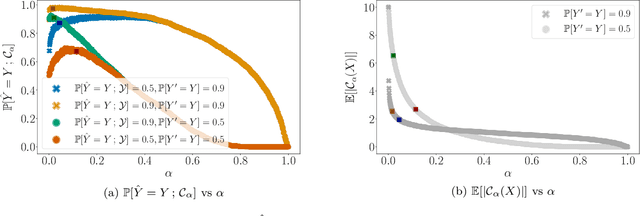
Whenever a binary classifier is used to provide decision support, it typically provides both a label prediction and a confidence value. Then, the decision maker is supposed to use the confidence value to calibrate how much to trust the prediction. In this context, it has been often argued that the confidence value should correspond to a well calibrated estimate of the probability that the predicted label matches the ground truth label. However, multiple lines of empirical evidence suggest that decision makers have difficulties at developing a good sense on when to trust a prediction using these confidence values. In this paper, our goal is first to understand why and then investigate how to construct more useful confidence values. We first argue that, for a broad class of utility functions, there exist data distributions for which a rational decision maker is, in general, unlikely to discover the optimal decision policy using the above confidence values -- an optimal decision maker would need to sometimes place more (less) trust on predictions with lower (higher) confidence values. However, we then show that, if the confidence values satisfy a natural alignment property with respect to the decision maker's confidence on her own predictions, there always exists an optimal decision policy under which the level of trust the decision maker would need to place on predictions is monotone on the confidence values, facilitating its discoverability. Further, we show that multicalibration with respect to the decision maker's confidence on her own predictions is a sufficient condition for alignment. Experiments on four different AI-assisted decision making tasks where a classifier provides decision support to real human experts validate our theoretical results and suggest that alignment may lead to better decisions.
On the Within-Group Discrimination of Screening Classifiers
Jan 31, 2023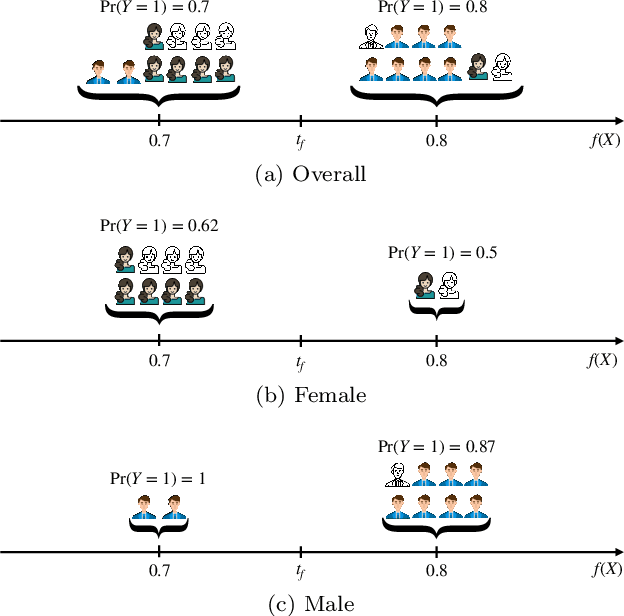
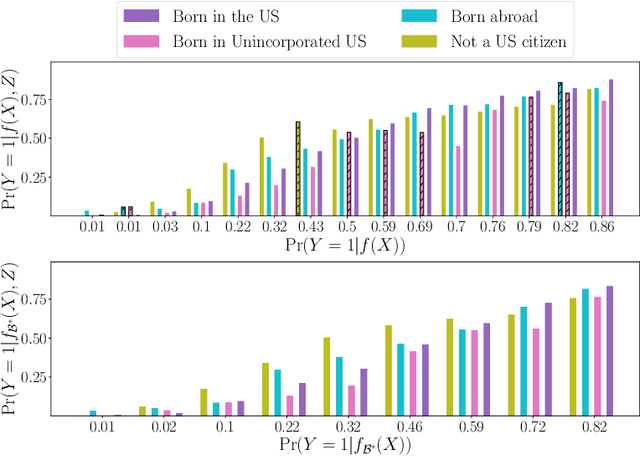
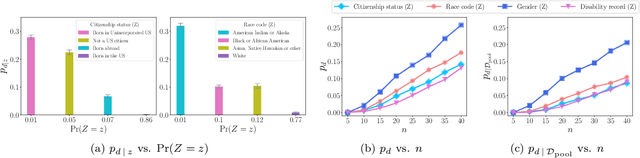
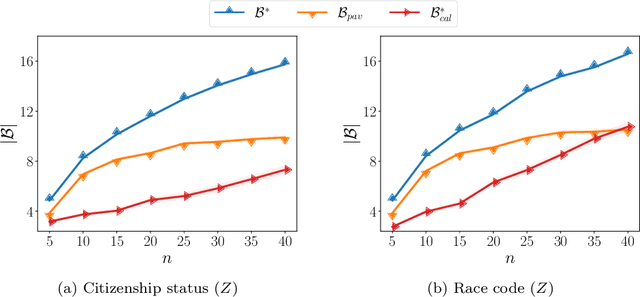
Screening classifiers are increasingly used to identify qualified candidates in a variety of selection processes. In this context, it has been recently shown that, if a classifier is calibrated, one can identify the smallest set of candidates which contains, in expectation, a desired number of qualified candidates using a threshold decision rule. This lends support to focusing on calibration as the only requirement for screening classifiers. In this paper, we argue that screening policies that use calibrated classifiers may suffer from an understudied type of within-group discrimination -- they may discriminate against qualified members within demographic groups of interest. Further, we argue that this type of discrimination can be avoided if classifiers satisfy within-group monotonicity, a natural monotonicity property within each of the groups. Then, we introduce an efficient post-processing algorithm based on dynamic programming to minimally modify a given calibrated classifier so that its probability estimates satisfy within-group monotonicity. We validate our algorithm using US Census survey data and show that within-group monotonicity can be often achieved at a small cost in terms of prediction granularity and shortlist size.
Counterfactual Inference of Second Opinions
Mar 16, 2022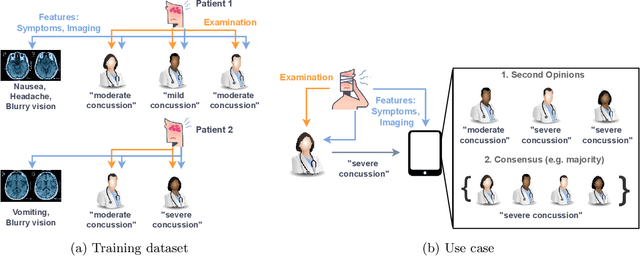

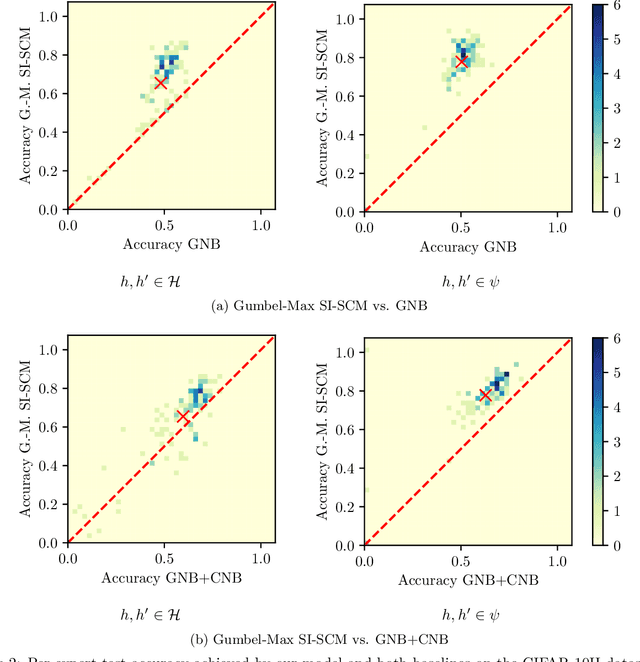
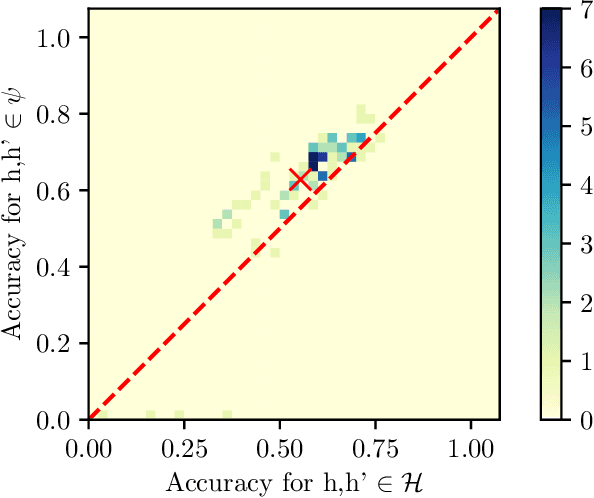
Automated decision support systems that are able to infer second opinions from experts can potentially facilitate a more efficient allocation of resources; they can help decide when and from whom to seek a second opinion. In this paper, we look at the design of this type of support systems from the perspective of counterfactual inference. We focus on a multiclass classification setting and first show that, if experts make predictions on their own, the underlying causal mechanism generating their predictions needs to satisfy a desirable set invariant property. Further, we show that, for any causal mechanism satisfying this property, there exists an equivalent mechanism where the predictions by each expert are generated by independent sub-mechanisms governed by a common noise. This motivates the design of a set invariant Gumbel-Max structural causal model where the structure of the noise governing the sub-mechanisms underpinning the model depends on an intuitive notion of similarity between experts which can be estimated from data. Experiments on both synthetic and real data show that our model can be used to infer second opinions more accurately than its non-causal counterpart.
Improving Screening Processes via Calibrated Subset Selection
Feb 02, 2022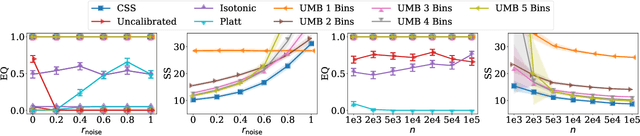

Many selection processes such as finding patients qualifying for a medical trial or retrieval pipelines in search engines consist of multiple stages, where an initial screening stage focuses the resources on shortlisting the most promising candidates. In this paper, we investigate what guarantees a screening classifier can provide, independently of whether it is constructed manually or trained. We find that current solutions do not enjoy distribution-free theoretical guarantees -- we show that, in general, even for a perfectly calibrated classifier, there always exist specific pools of candidates for which its shortlist is suboptimal. Then, we develop a distribution-free screening algorithm -- called Calibrated Subset Selection (CSS) -- that, given any classifier and some amount of calibration data, finds near-optimal shortlists of candidates that contain a desired number of qualified candidates in expectation. Moreover, we show that a variant of our algorithm that calibrates a given classifier multiple times across specific groups can create shortlists with provable diversity guarantees. Experiments on US Census survey data validate our theoretical results and show that the shortlists provided by our algorithm are superior to those provided by several competitive baselines.
Provably Improving Expert Predictions with Conformal Prediction
Jan 31, 2022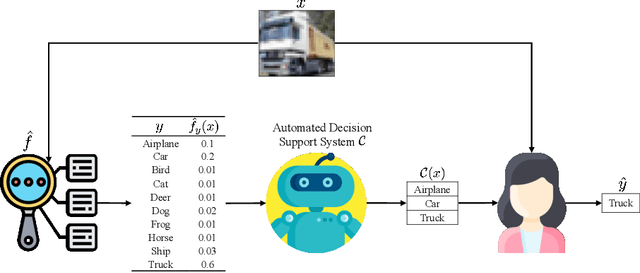

Automated decision support systems promise to help human experts solve tasks more efficiently and accurately. However, existing systems typically require experts to understand when to cede agency to the system or when to exercise their own agency. Moreover, if the experts develop a misplaced trust in the system, their performance may worsen. In this work, we lift the above requirement and develop automated decision support systems that, by design, do not require experts to understand when to trust them to provably improve their performance. To this end, we focus on multiclass classification tasks and consider automated decision support systems that, for each data sample, use a classifier to recommend a subset of labels to a human expert. We first show that, by looking at the design of such systems from the perspective of conformal prediction, we can ensure that the probability that the recommended subset of labels contains the true label matches almost exactly a target probability value. Then, we identify the set of target probability values under which the human expert is provably better off predicting a label among those in the recommended subset and develop an efficient practical method to find a near-optimal target probability value. Experiments on synthetic and real data demonstrate that our system can help the experts make more accurate predictions and is robust to the accuracy of the classifier it relies on.
Counterfactual Temporal Point Processes
Nov 15, 2021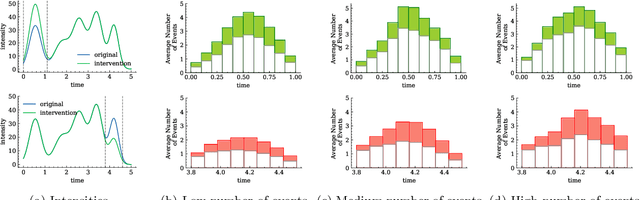


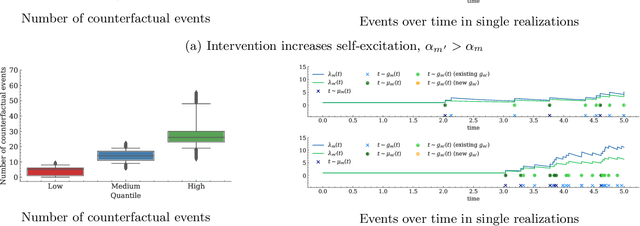
Machine learning models based on temporal point processes are the state of the art in a wide variety of applications involving discrete events in continuous time. However, these models lack the ability to answer counterfactual questions, which are increasingly relevant as these models are being used to inform targeted interventions. In this work, our goal is to fill this gap. To this end, we first develop a causal model of thinning for temporal point processes that builds upon the Gumbel-Max structural causal model. This model satisfies a desirable counterfactual monotonicity condition, which is sufficient to identify counterfactual dynamics in the process of thinning. Then, given an observed realization of a temporal point process with a given intensity function, we develop a sampling algorithm that uses the above causal model of thinning and the superposition theorem to simulate counterfactual realizations of the temporal point process under a given alternative intensity function. Simulation experiments using synthetic and real epidemiological data show that the counterfactual realizations provided by our algorithm may give valuable insights to enhance targeted interventions.