 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring multi-calibration
Jun 12, 2025A suitable scalar metric can help measure multi-calibration, defined as follows. When the expected values of observed responses are equal to corresponding predicted probabilities, the probabilistic predictions are known as "perfectly calibrated." When the predicted probabilities are perfectly calibrated simultaneously across several subpopulations, the probabilistic predictions are known as "perfectly multi-calibrated." In practice, predicted probabilities are seldom perfectly multi-calibrated, so a statistic measuring the distance from perfect multi-calibration is informative. A recently proposed metric for calibration, based on the classical Kuiper statistic, is a natural basis for a new metric of multi-calibration and avoids well-known problems of metrics based on binning or kernel density estimation. The newly proposed metric weights the contributions of different subpopulations in proportion to their signal-to-noise ratios; data analyses' ablations demonstrate that the metric becomes noisy when omitting the signal-to-noise ratios from the metric. Numerical examples on benchmark data sets illustrate the new metric.
Is Your LLM Overcharging You? Tokenization, Transparency, and Incentives
May 27, 2025State-of-the-art large language models require specialized hardware and substantial energy to operate. As a consequence, cloud-based services that provide access to large language models have become very popular. In these services, the price users pay for an output provided by a model depends on the number of tokens the model uses to generate it -- they pay a fixed price per token. In this work, we show that this pricing mechanism creates a financial incentive for providers to strategize and misreport the (number of) tokens a model used to generate an output, and users cannot prove, or even know, whether a provider is overcharging them. However, we also show that, if an unfaithful provider is obliged to be transparent about the generative process used by the model, misreporting optimally without raising suspicion is hard. Nevertheless, as a proof-of-concept, we introduce an efficient heuristic algorithm that allows providers to significantly overcharge users without raising suspicion, highlighting the vulnerability of users under the current pay-per-token pricing mechanism. Further, to completely eliminate the financial incentive to strategize, we introduce a simple incentive-compatible token pricing mechanism. Under this mechanism, the price users pay for an output provided by a model depends on the number of characters of the output -- they pay a fixed price per character. Along the way, to illustrate and complement our theoretical results, we conduct experiments with several large language models from the $\texttt{Llama}$, $\texttt{Gemma}$ and $\texttt{Ministral}$ families, and input prompts from the LMSYS Chatbot Arena platform.
Root Cause Analysis of Outliers with Missing Structural Knowledge
Jun 07, 2024Recent work conceptualized root cause analysis (RCA) of anomalies via quantitative contribution analysis using causal counterfactuals in structural causal models (SCMs). The framework comes with three practical challenges: (1) it requires the causal directed acyclic graph (DAG), together with an SCM, (2) it is statistically ill-posed since it probes regression models in regions of low probability density, (3) it relies on Shapley values which are computationally expensive to find. In this paper, we propose simplified, efficient methods of root cause analysis when the task is to identify a unique root cause instead of quantitative contribution analysis. Our proposed methods run in linear order of SCM nodes and they require only the causal DAG without counterfactuals. Furthermore, for those use cases where the causal DAG is unknown, we justify the heuristic of identifying root causes as the variables with the highest anomaly score.
Towards Human-AI Complementarity with Predictions Sets
May 27, 2024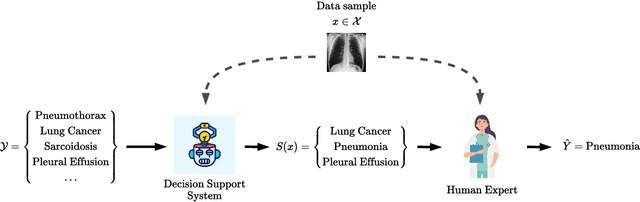
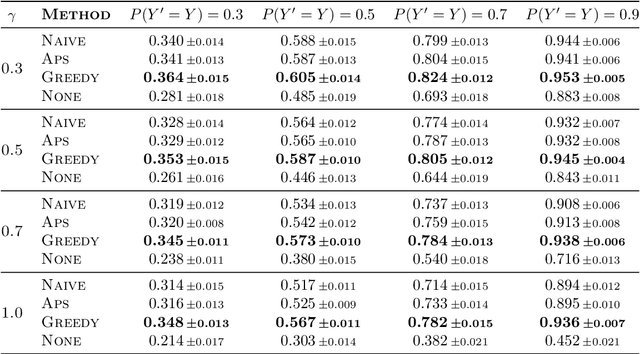
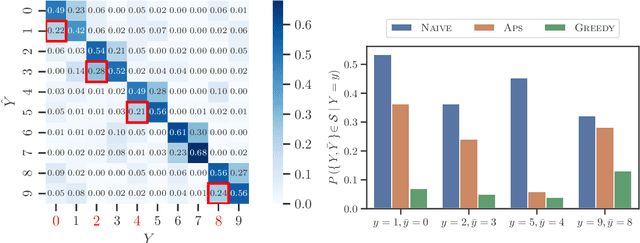

Decision support systems based on prediction sets have proven to be effective at helping human experts solve classification tasks. Rather than providing single-label predictions, these systems provide sets of label predictions constructed using conformal prediction, namely prediction sets, and ask human experts to predict label values from these sets. In this paper, we first show that the prediction sets constructed using conformal prediction are, in general, suboptimal in terms of average accuracy. Then, we show that the problem of finding the optimal prediction sets under which the human experts achieve the highest average accuracy is NP-hard. More strongly, unless P = NP, we show that the problem is hard to approximate to any factor less than the size of the label set. However, we introduce a simple and efficient greedy algorithm that, for a large class of expert models and non-conformity scores, is guaranteed to find prediction sets that provably offer equal or greater performance than those constructed using conformal prediction. Further, using a simulation study with both synthetic and real expert predictions, we demonstrate that, in practice, our greedy algorithm finds near-optimal prediction sets offering greater performance than conformal prediction.
On the Within-Group Discrimination of Screening Classifiers
Jan 31, 2023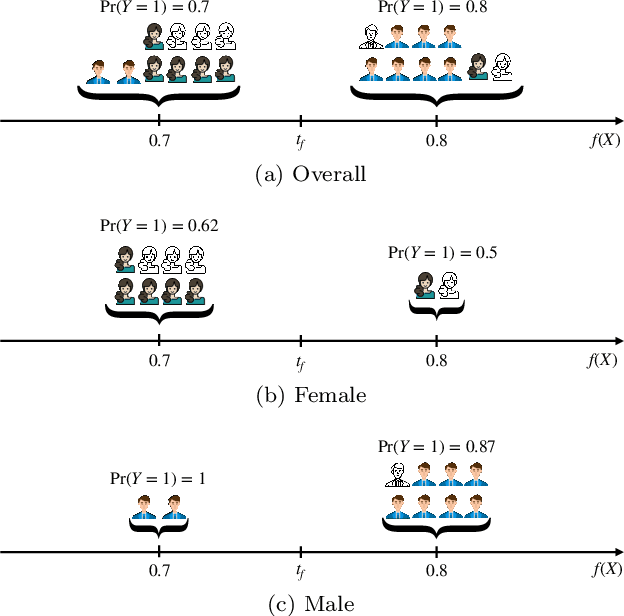
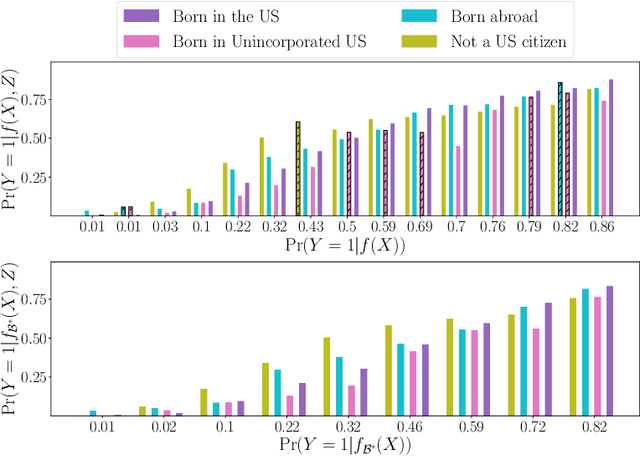
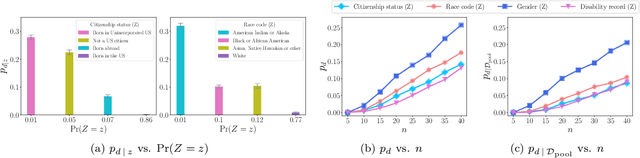
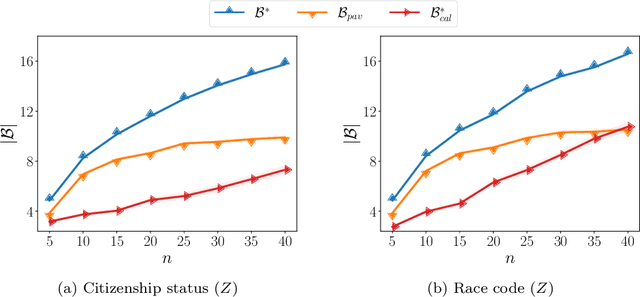
Screening classifiers are increasingly used to identify qualified candidates in a variety of selection processes. In this context, it has been recently shown that, if a classifier is calibrated, one can identify the smallest set of candidates which contains, in expectation, a desired number of qualified candidates using a threshold decision rule. This lends support to focusing on calibration as the only requirement for screening classifiers. In this paper, we argue that screening policies that use calibrated classifiers may suffer from an understudied type of within-group discrimination -- they may discriminate against qualified members within demographic groups of interest. Further, we argue that this type of discrimination can be avoided if classifiers satisfy within-group monotonicity, a natural monotonicity property within each of the groups. Then, we introduce an efficient post-processing algorithm based on dynamic programming to minimally modify a given calibrated classifier so that its probability estimates satisfy within-group monotonicity. We validate our algorithm using US Census survey data and show that within-group monotonicity can be often achieved at a small cost in terms of prediction granularity and shortlist size.
Provably Improving Expert Predictions with Conformal Prediction
Jan 31, 2022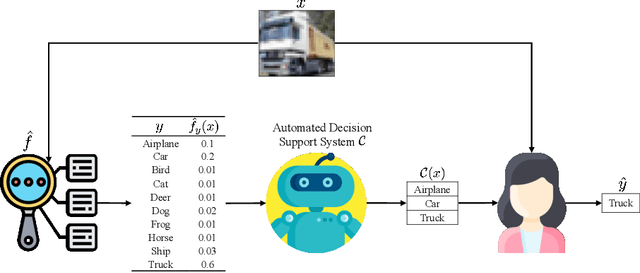
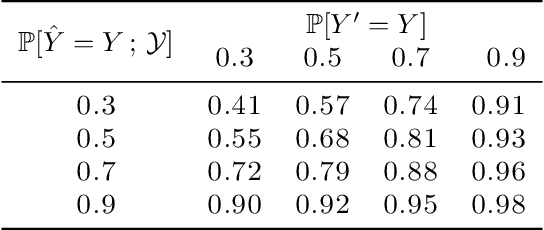
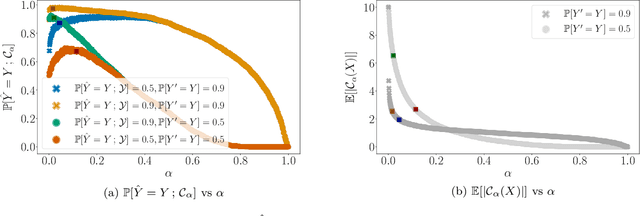

Automated decision support systems promise to help human experts solve tasks more efficiently and accurately. However, existing systems typically require experts to understand when to cede agency to the system or when to exercise their own agency. Moreover, if the experts develop a misplaced trust in the system, their performance may worsen. In this work, we lift the above requirement and develop automated decision support systems that, by design, do not require experts to understand when to trust them to provably improve their performance. To this end, we focus on multiclass classification tasks and consider automated decision support systems that, for each data sample, use a classifier to recommend a subset of labels to a human expert. We first show that, by looking at the design of such systems from the perspective of conformal prediction, we can ensure that the probability that the recommended subset of labels contains the true label matches almost exactly a target probability value. Then, we identify the set of target probability values under which the human expert is provably better off predicting a label among those in the recommended subset and develop an efficient practical method to find a near-optimal target probability value. Experiments on synthetic and real data demonstrate that our system can help the experts make more accurate predictions and is robust to the accuracy of the classifier it relies on.
Differentiable Learning Under Triage
Mar 16, 2021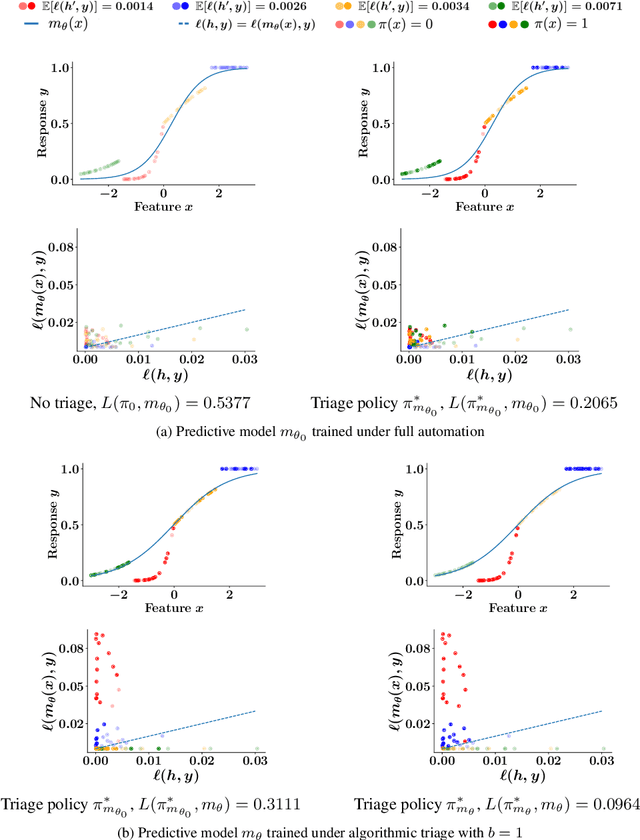
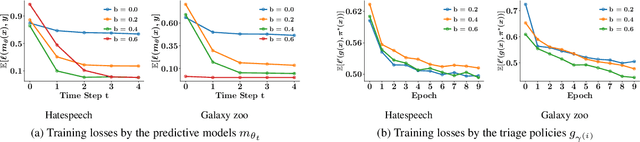
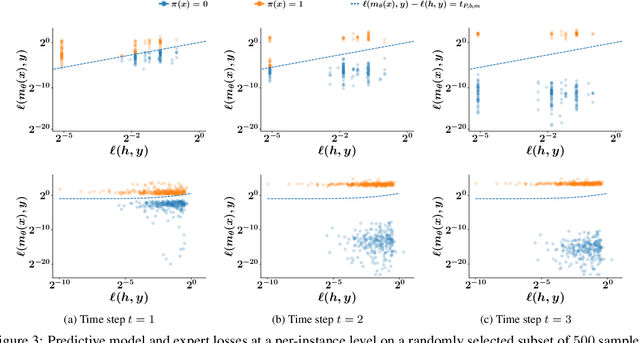
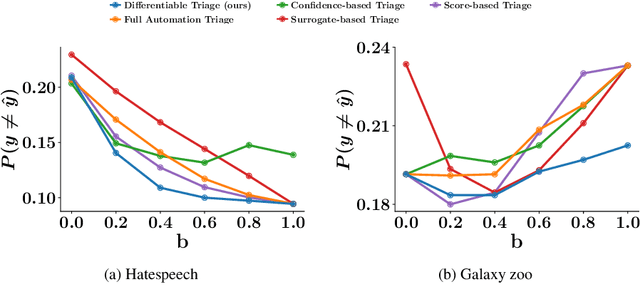
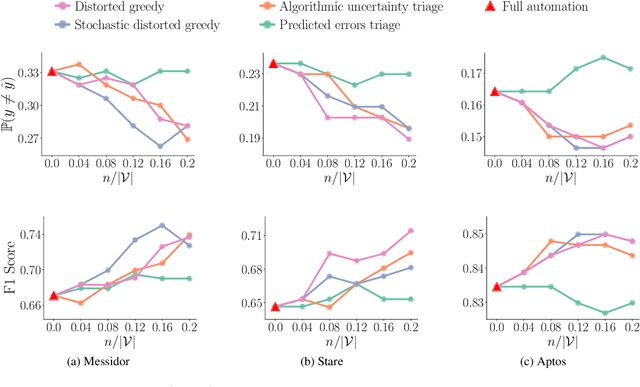
Multiple lines of evidence suggest that predictive models may benefit from algorithmic triage. Under algorithmic triage, a predictive model does not predict all instances but instead defers some of them to human experts. However, the interplay between the prediction accuracy of the model and the human experts under algorithmic triage is not well understood. In this work, we start by formally characterizing under which circumstances a predictive model may benefit from algorithmic triage. In doing so, we also demonstrate that models trained for full automation may be suboptimal under triage. Then, given any model and desired level of triage, we show that the optimal triage policy is a deterministic threshold rule in which triage decisions are derived deterministically by thresholding the difference between the model and human errors on a per-instance level. Building upon these results, we introduce a practical gradient-based algorithm that is guaranteed to find a sequence of triage policies and predictive models of increasing performance. Experiments on a wide variety of supervised learning tasks using synthetic and real data from two important applications -- content moderation and scientific discovery -- illustrate our theoretical results and show that the models and triage policies provided by our gradient-based algorithm outperform those provided by several competitive baselines.
Classification Under Human Assistance
Jun 21, 2020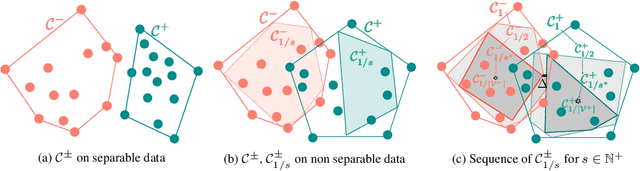
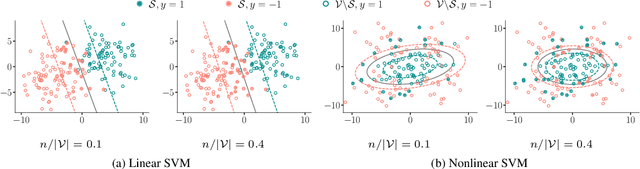
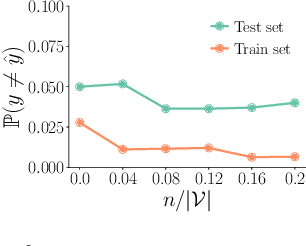
Most supervised learning models are trained for full automation. However, their predictions are sometimes worse than those by human experts on some specific instances. Motivated by this empirical observation, our goal is to design classifiers that are optimized to operate under different automation levels. More specifically, we focus on convex margin-based classifiers and first show that the problem is NP-hard. Then, we further show that, for support vector machines, the corresponding objective function can be expressed as the difference of two functions f = g - c, where g is monotone, non-negative and {\gamma}-weakly submodular, and c is non-negative and modular. This representation allows a recently introduced deterministic greedy algorithm, as well as a more efficient randomized variant of the algorithm, to enjoy approximation guarantees at solving the problem. Experiments on synthetic and real-world data from several applications in medical diagnosis illustrate our theoretical findings and demonstrate that, under human assistance, supervised learning models trained to operate under different automation levels can outperform those trained for full automation as well as humans operating alone.
Computational Approaches for Stochastic Shortest Path on Succinct MDPs
Jul 17, 2018
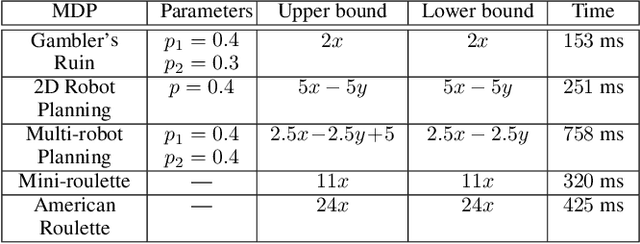
We consider the stochastic shortest path (SSP) problem for succinct Markov decision processes (MDPs), where the MDP consists of a set of variables, and a set of nondeterministic rules that update the variables. First, we show that several examples from the AI literature can be modeled as succinct MDPs. Then we present computational approaches for upper and lower bounds for the SSP problem: (a)~for computing upper bounds, our method is polynomial-time in the implicit description of the MDP; (b)~for lower bounds, we present a polynomial-time (in the size of the implicit description) reduction to quadratic programming. Our approach is applicable even to infinite-state MDPs. Finally, we present experimental results to demonstrate the effectiveness of our approach on several classical examples from the AI literature.