 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy After $\langle \texttt{/Think} \rangle$ for reasoning model early exiting
Sep 30, 2025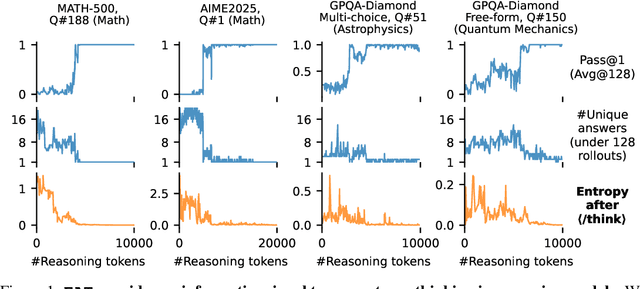

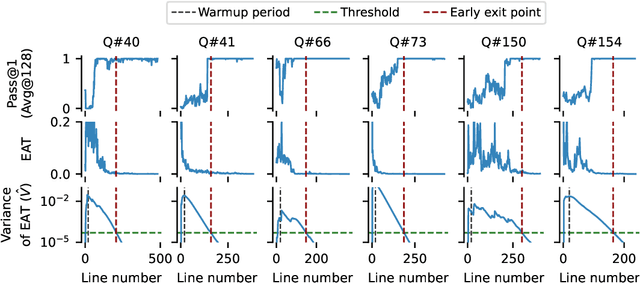
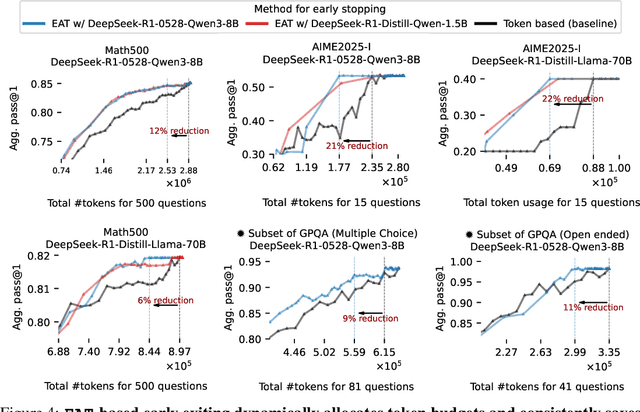
Large reasoning models show improved performance with longer chains of thought. However, recent work has highlighted (qualitatively) their tendency to overthink, continuing to revise answers even after reaching the correct solution. We quantitatively confirm this inefficiency by tracking Pass@1 for answers averaged over a large number of rollouts and find that the model often begins to always produce the correct answer early in the reasoning, making extra reasoning a waste of tokens. To detect and prevent overthinking, we propose a simple and inexpensive novel signal -- Entropy After </Think> (EAT) -- for monitoring and deciding whether to exit reasoning early. By appending a stop thinking token (</think>) and monitoring the entropy of the following token as the model reasons, we obtain a trajectory that decreases and stabilizes when Pass@1 plateaus; thresholding its variance under an exponential moving average yields a practical stopping rule. Importantly, our approach enables adaptively allocating compute based on the EAT trajectory, allowing us to spend compute in a more efficient way compared with fixing the token budget for all questions. Empirically, on MATH500 and AIME2025, EAT reduces token usage by 13 - 21% without harming accuracy, and it remains effective in black box settings where logits from the reasoning model are not accessible, and EAT is computed with proxy models.
Off-Policy Evaluation for Large Action Spaces via Policy Convolution
Oct 24, 2023Developing accurate off-policy estimators is crucial for both evaluating and optimizing for new policies. The main challenge in off-policy estimation is the distribution shift between the logging policy that generates data and the target policy that we aim to evaluate. Typically, techniques for correcting distribution shift involve some form of importance sampling. This approach results in unbiased value estimation but often comes with the trade-off of high variance, even in the simpler case of one-step contextual bandits. Furthermore, importance sampling relies on the common support assumption, which becomes impractical when the action space is large. To address these challenges, we introduce the Policy Convolution (PC) family of estimators. These methods leverage latent structure within actions -- made available through action embeddings -- to strategically convolve the logging and target policies. This convolution introduces a unique bias-variance trade-off, which can be controlled by adjusting the amount of convolution. Our experiments on synthetic and benchmark datasets demonstrate remarkable mean squared error (MSE) improvements when using PC, especially when either the action space or policy mismatch becomes large, with gains of up to 5 - 6 orders of magnitude over existing estimators.
Oracle-Efficient Pessimism: Offline Policy Optimization in Contextual Bandits
Jun 13, 2023



We consider policy optimization in contextual bandits, where one is given a fixed dataset of logged interactions. While pessimistic regularizers are typically used to mitigate distribution shift, prior implementations thereof are not computationally efficient. We present the first oracle-efficient algorithm for pessimistic policy optimization: it reduces to supervised learning, leading to broad applicability. We also obtain best-effort statistical guarantees analogous to those for pessimistic approaches in prior work. We instantiate our approach for both discrete and continuous actions. We perform extensive experiments in both settings, showing advantage over unregularized policy optimization across a wide range of configurations.
Fairness in the First Stage of Two-Stage Recommender Systems
Jun 02, 2022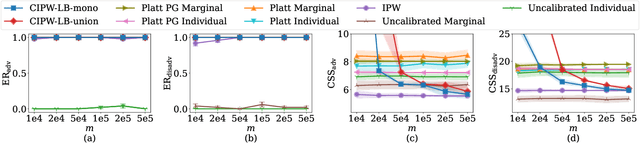


Many large-scale recommender systems consist of two stages, where the first stage focuses on efficiently generating a small subset of promising candidates from a huge pool of items for the second-stage model to curate final recommendations from. In this paper, we investigate how to ensure group fairness to the items in this two-stage paradigm. In particular, we find that existing first-stage recommenders might select an irrecoverably unfair set of candidates such that there is no hope for the second-stage recommender to deliver fair recommendations. To this end, we propose two threshold-policy selection rules that, given any relevance model of queries and items and a point-wise lower confidence bound on the expected number of relevant items for each policy, find near-optimal sets of candidates that contain enough relevant items in expectation from each group of items. To instantiate the rules, we demonstrate how to derive such confidence bounds from potentially partial and biased user feedback data, which are abundant in many large-scale recommender systems. In addition, we provide both finite-sample and asymptotic analysis of how close the two threshold selection rules are to the optimal thresholds. Beyond this theoretical analysis, we show empirically that these two rules can consistently select enough relevant items from each group while minimizing the size of the candidate sets for a wide range of settings.
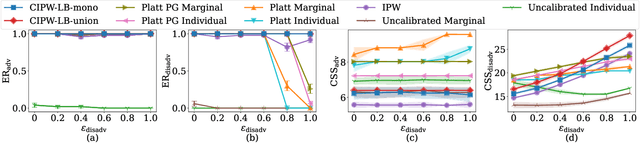
Improving Screening Processes via Calibrated Subset Selection
Feb 02, 2022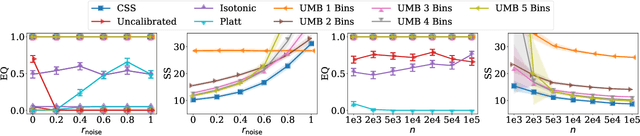

Many selection processes such as finding patients qualifying for a medical trial or retrieval pipelines in search engines consist of multiple stages, where an initial screening stage focuses the resources on shortlisting the most promising candidates. In this paper, we investigate what guarantees a screening classifier can provide, independently of whether it is constructed manually or trained. We find that current solutions do not enjoy distribution-free theoretical guarantees -- we show that, in general, even for a perfectly calibrated classifier, there always exist specific pools of candidates for which its shortlist is suboptimal. Then, we develop a distribution-free screening algorithm -- called Calibrated Subset Selection (CSS) -- that, given any classifier and some amount of calibration data, finds near-optimal shortlists of candidates that contain a desired number of qualified candidates in expectation. Moreover, we show that a variant of our algorithm that calibrates a given classifier multiple times across specific groups can create shortlists with provable diversity guarantees. Experiments on US Census survey data validate our theoretical results and show that the shortlists provided by our algorithm are superior to those provided by several competitive baselines.
Provably Improving Expert Predictions with Conformal Prediction
Jan 31, 2022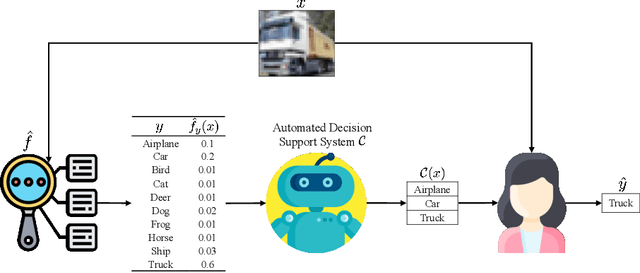
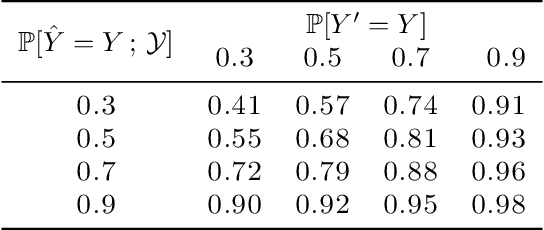

Automated decision support systems promise to help human experts solve tasks more efficiently and accurately. However, existing systems typically require experts to understand when to cede agency to the system or when to exercise their own agency. Moreover, if the experts develop a misplaced trust in the system, their performance may worsen. In this work, we lift the above requirement and develop automated decision support systems that, by design, do not require experts to understand when to trust them to provably improve their performance. To this end, we focus on multiclass classification tasks and consider automated decision support systems that, for each data sample, use a classifier to recommend a subset of labels to a human expert. We first show that, by looking at the design of such systems from the perspective of conformal prediction, we can ensure that the probability that the recommended subset of labels contains the true label matches almost exactly a target probability value. Then, we identify the set of target probability values under which the human expert is provably better off predicting a label among those in the recommended subset and develop an efficient practical method to find a near-optimal target probability value. Experiments on synthetic and real data demonstrate that our system can help the experts make more accurate predictions and is robust to the accuracy of the classifier it relies on.
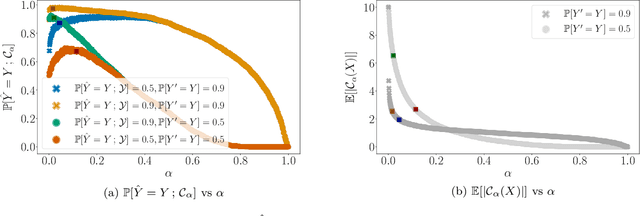
Fairness of Exposure in Stochastic Bandits
Mar 03, 2021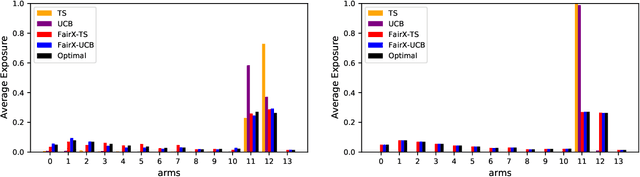
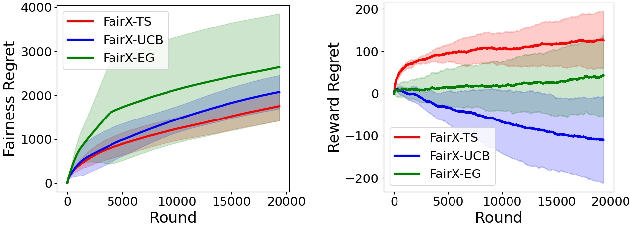
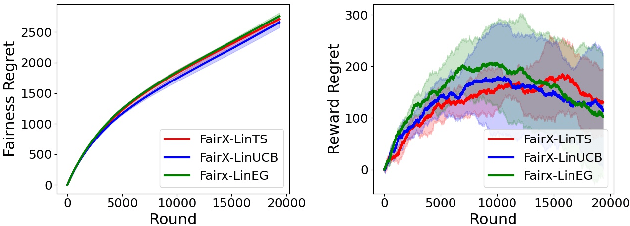

Contextual bandit algorithms have become widely used for recommendation in online systems (e.g. marketplaces, music streaming, news), where they now wield substantial influence on which items get exposed to the users. This raises questions of fairness to the items -- and to the sellers, artists, and writers that benefit from this exposure. We argue that the conventional bandit formulation can lead to an undesirable and unfair winner-takes-all allocation of exposure. To remedy this problem, we propose a new bandit objective that guarantees merit-based fairness of exposure to the items while optimizing utility to the users. We formulate fairness regret and reward regret in this setting, and present algorithms for both stochastic multi-armed bandits and stochastic linear bandits. We prove that the algorithms achieve sub-linear fairness regret and reward regret. Beyond the theoretical analysis, we also provide empirical evidence that these algorithms can fairly allocate exposure to different arms effectively.
Fairness and Diversity for Rankings in Two-Sided Markets
Oct 04, 2020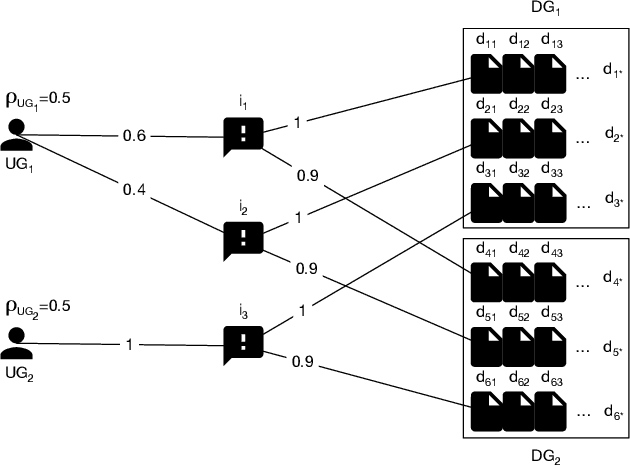


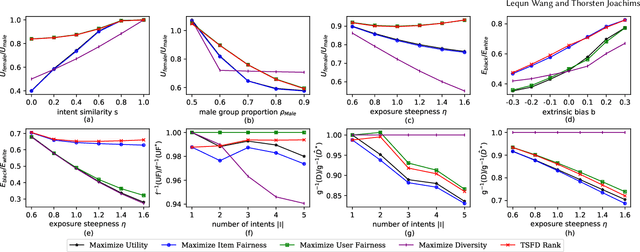
Ranking items by their probability of relevance has long been the goal of conventional ranking systems. While this maximizes traditional criteria of ranking performance, there is a growing understanding that it is an oversimplification in online platforms that serve not only a diverse user population, but also the producers of the items. In particular, ranking algorithms are expected to be fair in how they serve all groups of users -- not just the majority group -- and they also need to be fair in how they divide exposure among the items. These fairness considerations can partially be met by adding diversity to the rankings, as done in several recent works, but we show in this paper that user fairness, item fairness and diversity are fundamentally different concepts. In particular, we find that algorithms that consider only one of the three desiderata can fail to satisfy and even harm the other two. To overcome this shortcoming, we present the first ranking algorithm that explicitly enforces all three desiderata. The algorithm optimizes user and item fairness as a convex optimization problem which can be solved optimally. From its solution, a ranking policy can be derived via a new Birkhoff-von Neumann decomposition algorithm that optimizes diversity. Beyond the theoretical analysis, we provide a comprehensive empirical evaluation on a new benchmark dataset to show the effectiveness of the proposed ranking algorithm on controlling the three desiderata and the interplay between them.
Integrated Triaging for Fast Reading Comprehension
Sep 28, 2019
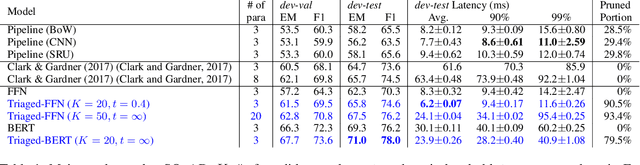
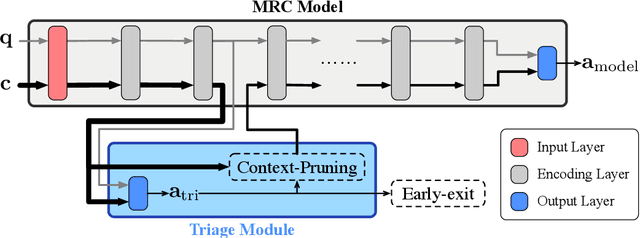
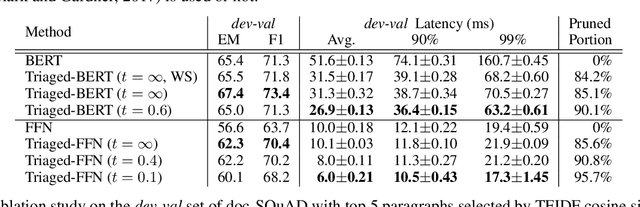
Although according to several benchmarks automatic machine reading comprehension (MRC) systems have recently reached super-human performance, less attention has been paid to their computational efficiency. However, efficiency is of crucial importance for training and deployment in real world applications. This paper introduces Integrated Triaging, a framework that prunes almost all context in early layers of a network, leaving the remaining (deep) layers to scan only a tiny fraction of the full corpus. This pruning drastically increases the efficiency of MRC models and further prevents the later layers from overfitting to prevalent short paragraphs in the training set. Our framework is extremely flexible and naturally applicable to a wide variety of models. Our experiment on doc-SQuAD and TriviaQA tasks demonstrates its effectiveness in consistently improving both speed and quality of several diverse MRC models.
FastFusionNet: New State-of-the-Art for DAWNBench SQuAD
Mar 02, 2019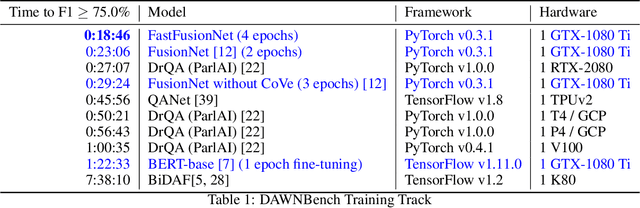
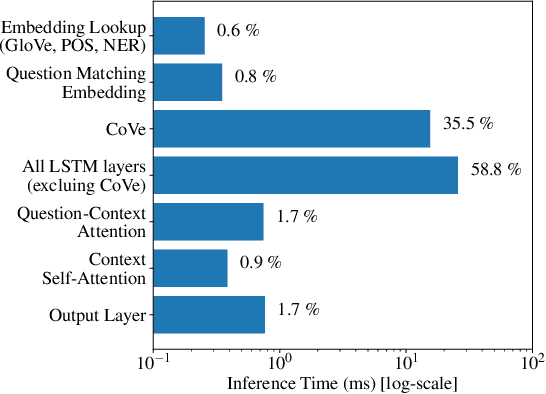
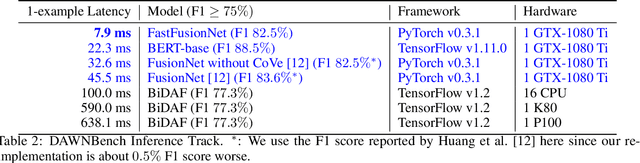
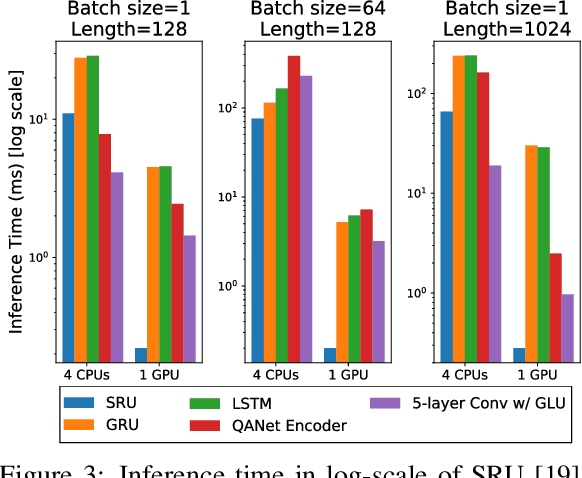
In this technical report, we introduce FastFusionNet, an efficient variant of FusionNet [12]. FusionNet is a high performing reading comprehension architecture, which was designed primarily for maximum retrieval accuracy with less regard towards computational requirements. For FastFusionNets we remove the expensive CoVe layers [21] and substitute the BiLSTMs with far more efficient SRU layers [19]. The resulting architecture obtains state-of-the-art results on DAWNBench [5] while achieving the lowest training and inference time on SQuAD [25] to-date. The code is available at https://github.com/felixgwu/FastFusionNet.