 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness in the First Stage of Two-Stage Recommender Systems
Paper and Code
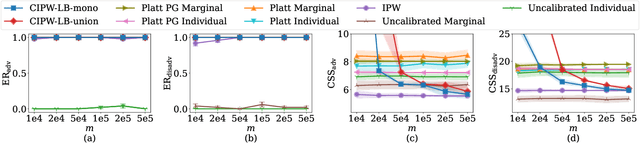
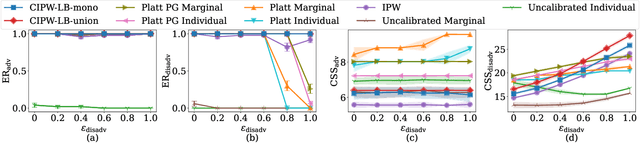


Many large-scale recommender systems consist of two stages, where the first stage focuses on efficiently generating a small subset of promising candidates from a huge pool of items for the second-stage model to curate final recommendations from. In this paper, we investigate how to ensure group fairness to the items in this two-stage paradigm. In particular, we find that existing first-stage recommenders might select an irrecoverably unfair set of candidates such that there is no hope for the second-stage recommender to deliver fair recommendations. To this end, we propose two threshold-policy selection rules that, given any relevance model of queries and items and a point-wise lower confidence bound on the expected number of relevant items for each policy, find near-optimal sets of candidates that contain enough relevant items in expectation from each group of items. To instantiate the rules, we demonstrate how to derive such confidence bounds from potentially partial and biased user feedback data, which are abundant in many large-scale recommender systems. In addition, we provide both finite-sample and asymptotic analysis of how close the two threshold selection rules are to the optimal thresholds. Beyond this theoretical analysis, we show empirically that these two rules can consistently select enough relevant items from each group while minimizing the size of the candidate sets for a wide range of settings.