 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAB: Continuous Adaptive Blending Estimator for Policy Evaluation and Learning
Paper and Code
Nov 19, 2018


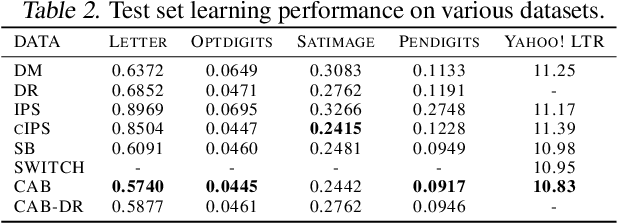
The ability to perform offline A/B-testing and off-policy learning using logged contextual bandit feedback is highly desirable in a broad range of applications, including recommender systems, search engines, ad placement, and personalized health care. Both offline A/B-testing and off-policy learning require a counterfactual estimator that evaluates how some new policy would have performed, if it had been used instead of the logging policy. This paper proposes a new counterfactual estimator - called Continuous Adaptive Blending (CAB) - for this policy evaluation problem that combines regression and weighting approaches for an effective bias/variance trade-off. It can be substantially less biased than clipped Inverse Propensity Score weighting and the Direct Method, and it can have less variance compared with Doubly Robust and IPS estimators. Experimental results show that CAB provides excellent and reliable estimation accuracy compared to other blended estimators, and - unlike the SWITCH estimator - is sub-differentiable such that it can be used for learning.