 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Triaging for Fast Reading Comprehension
Paper and Code

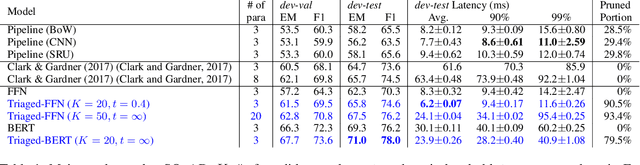
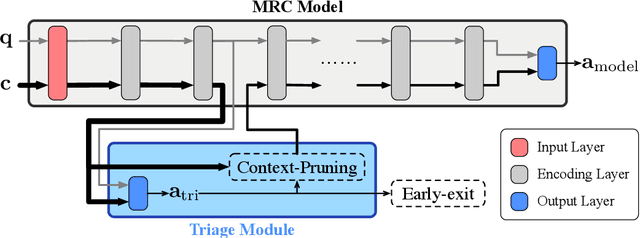
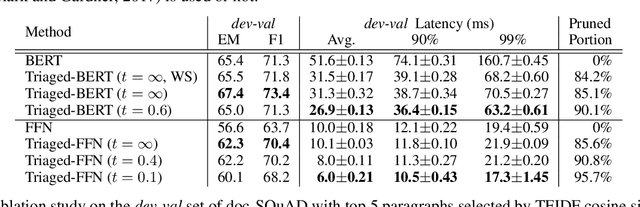
Although according to several benchmarks automatic machine reading comprehension (MRC) systems have recently reached super-human performance, less attention has been paid to their computational efficiency. However, efficiency is of crucial importance for training and deployment in real world applications. This paper introduces Integrated Triaging, a framework that prunes almost all context in early layers of a network, leaving the remaining (deep) layers to scan only a tiny fraction of the full corpus. This pruning drastically increases the efficiency of MRC models and further prevents the later layers from overfitting to prevalent short paragraphs in the training set. Our framework is extremely flexible and naturally applicable to a wide variety of models. Our experiment on doc-SQuAD and TriviaQA tasks demonstrates its effectiveness in consistently improving both speed and quality of several diverse MRC models.