 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness of Exposure in Stochastic Bandits
Paper and Code
Mar 03, 2021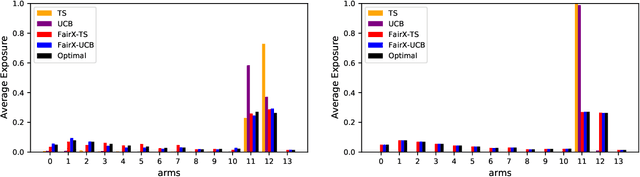
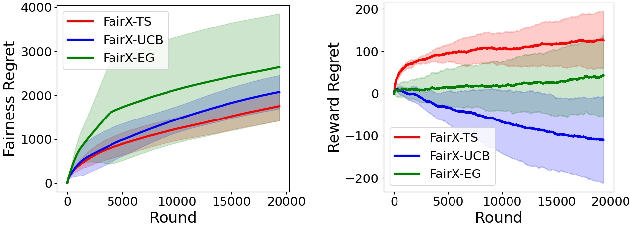
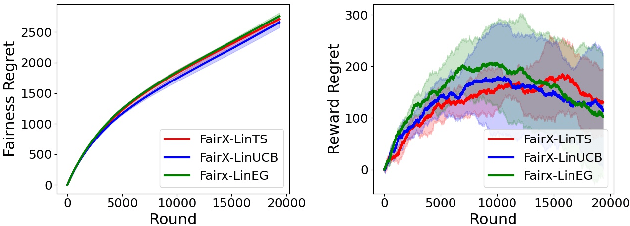

Contextual bandit algorithms have become widely used for recommendation in online systems (e.g. marketplaces, music streaming, news), where they now wield substantial influence on which items get exposed to the users. This raises questions of fairness to the items -- and to the sellers, artists, and writers that benefit from this exposure. We argue that the conventional bandit formulation can lead to an undesirable and unfair winner-takes-all allocation of exposure. To remedy this problem, we propose a new bandit objective that guarantees merit-based fairness of exposure to the items while optimizing utility to the users. We formulate fairness regret and reward regret in this setting, and present algorithms for both stochastic multi-armed bandits and stochastic linear bandits. We prove that the algorithms achieve sub-linear fairness regret and reward regret. Beyond the theoretical analysis, we also provide empirical evidence that these algorithms can fairly allocate exposure to different arms effectively.