 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Robust Portfolios of Optimization Models using Large Language Models
May 26, 2026Mathematical optimization is a powerful tool for structured decision-making across domains such as resource allocation and planning. Formulating optimization models faithful to reality, though, remains a significant bottleneck as it typically demands both domain expertise and optimization knowledge that are often scarce. Recent advances in large language models (LLMs) promise to bridge this gap, enabling the generation of candidate optimization models from natural language descriptions. However, there is no guarantee that any single LLM-generated model is reliable, and existing approaches that output only one model are therefore risky. In this work, we propose a novel algorithm that generates a portfolio of optimization models, designed to be robust to the limitations of LLMs. Our method exploits the observation that a single LLM can play two distinct roles $\unicode{x2014}$ as a stochastic generator and as a reasoning evaluator $\unicode{x2014}$ and proposes a unified framework that leverages both capabilities in a complementary manner. We provide theoretical guarantees showing that, as long as either the generator or the evaluator is well-aligned with human preferences, the portfolio is guaranteed to contain high-quality candidates, enabling a principled human-in-the-loop process in which a decision-maker can review multiple candidates before committing to one. We further validate our approach empirically, demonstrating strong performance across a range of optimization modeling tasks.
Learning to Decide with AI Assistance under Human-Alignment
May 12, 2026It is widely agreed that when AI models assist decision-makers in high-stakes domains by predicting an outcome of interest, they should communicate the confidence of their predictions. However, empirical evidence suggests that decision-makers often struggle to determine when to trust a prediction based solely on this communicated confidence. In this context, recent theoretical and empirical work suggests a positive correlation between the utility of AI-assisted decision-making and the degree of alignment between the AI confidence and the decision-makers' confidence in their own predictions. Crucially, these findings do not yet elucidate the extent to which this alignment influences the complexity of learning to make optimal decisions through repeated interactions. In this paper, we address this question in the canonical case of binary predictions and binary decisions. We first show that this problem is equivalent to a two-armed online contextual learning problem with full feedback, and establish a lower bound of $Ω(\sqrt{|H| \cdot |B| \cdot T} )$ on the expected regret any learner can attain, where $H$ and $B$ denote the sets of human and AI confidence values. We then demonstrate that, under perfect alignment between AI and human confidence, a learner can attain an expected regret of $O(\sqrt{|H| \cdot T\log T})$ and, when $\sqrt{|H|} = O(\log T)$ and $B$ is countable, a non-trivial generalization of the Dvoretzky-Kiefer-Wolfowitz inequality improves the regret bound to $O(\sqrt{T\log T})$. Taken together, these results reveal that alignment can reduce the complexity of learning to make decisions with AI assistance. Experiments on real data from two different human-subject studies where participants solve simple decision-making tasks assisted by AI models show that our theoretical results are robust to violations of perfect alignment.
Evaluation of Large Language Models via Coupled Token Generation
Feb 03, 2025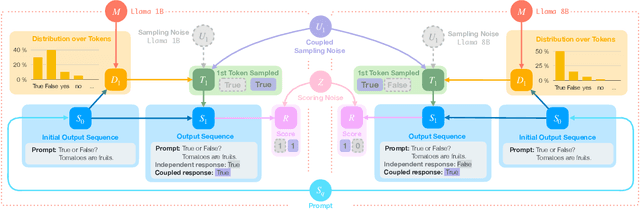
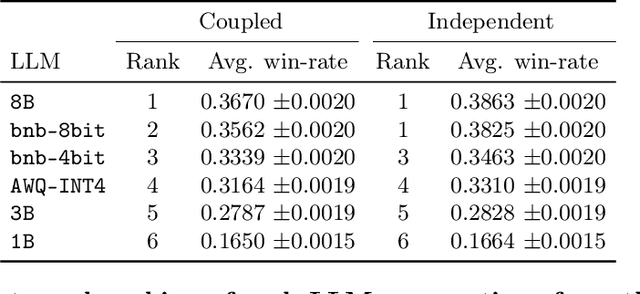
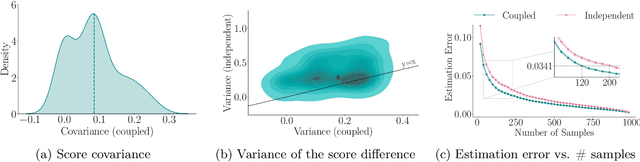
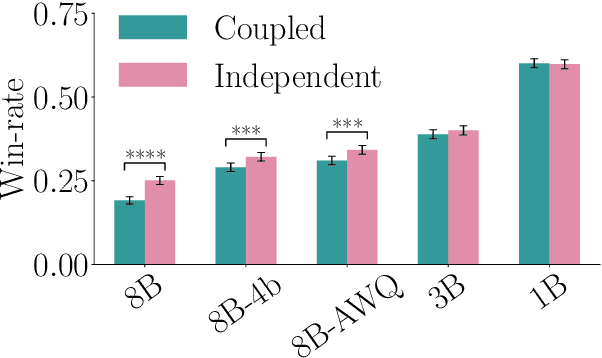
State of the art large language models rely on randomization to respond to a prompt. As an immediate consequence, a model may respond differently to the same prompt if asked multiple times. In this work, we argue that the evaluation and ranking of large language models should control for the randomization underpinning their functioning. Our starting point is the development of a causal model for coupled autoregressive generation, which allows different large language models to sample responses with the same source of randomness. Building upon our causal model, we first show that, on evaluations based on benchmark datasets, coupled autoregressive generation leads to the same conclusions as vanilla autoregressive generation but using provably fewer samples. However, we further show that, on evaluations based on (human) pairwise comparisons, coupled and vanilla autoregressive generation can surprisingly lead to different rankings when comparing more than two models, even with an infinite amount of samples. This suggests that the apparent advantage of a model over others in existing evaluation protocols may not be genuine but rather confounded by the randomness inherent to the generation process. To illustrate and complement our theoretical results, we conduct experiments with several large language models from the Llama family. We find that, across multiple knowledge areas from the popular MMLU benchmark dataset, coupled autoregressive generation requires up to 40% fewer samples to reach the same conclusions as vanilla autoregressive generation. Further, using data from the LMSYS Chatbot Arena platform, we find that the win-rates derived from pairwise comparisons by a strong large language model to prompts differ under coupled and vanilla autoregressive generation.
Counterfactual Token Generation in Large Language Models
Sep 25, 2024



"Sure, I am happy to generate a story for you: Captain Lyra stood at the helm of her trusty ship, the Maelstrom's Fury, gazing out at the endless sea. [...] Lyra's eyes welled up with tears as she realized the bitter truth - she had sacrificed everything for fleeting riches, and lost the love of her crew, her family, and herself." Although this story, generated by a large language model, is captivating, one may wonder -- how would the story have unfolded if the model had chosen "Captain Maeve" as the protagonist instead? We cannot know. State-of-the-art large language models are stateless -- they maintain no internal memory or state. Given a prompt, they generate a sequence of tokens as an output using an autoregressive process. As a consequence, they cannot reason about counterfactual alternatives to tokens they have generated in the past. In this work, our goal is to enhance them with this functionality. To this end, we develop a causal model of token generation that builds upon the Gumbel-Max structural causal model. Our model allows any large language model to perform counterfactual token generation at almost no cost in comparison with vanilla token generation, it is embarrassingly simple to implement, and it does not require any fine-tuning nor prompt engineering. We implement our model on Llama 3 8B-instruct and conduct both qualitative and quantitative analyses of counterfactually generated text. We conclude with a demonstrative application of counterfactual token generation for bias detection, unveiling interesting insights about the model of the world constructed by large language models.
Controlling Counterfactual Harm in Decision Support Systems Based on Prediction Sets
Jun 10, 2024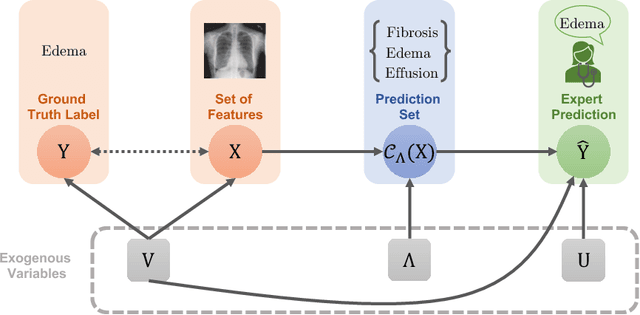
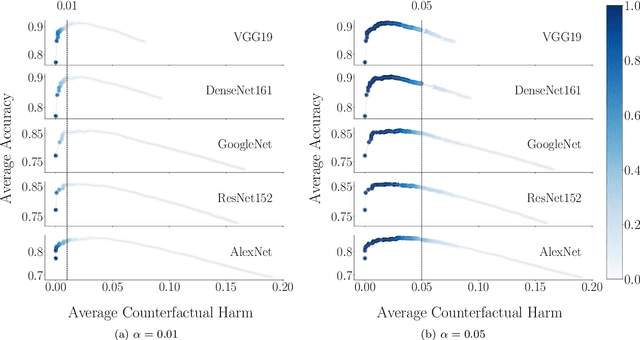
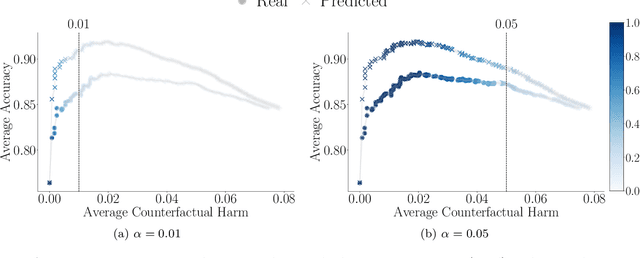
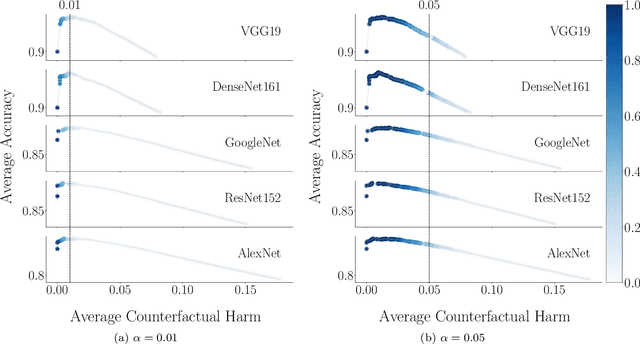
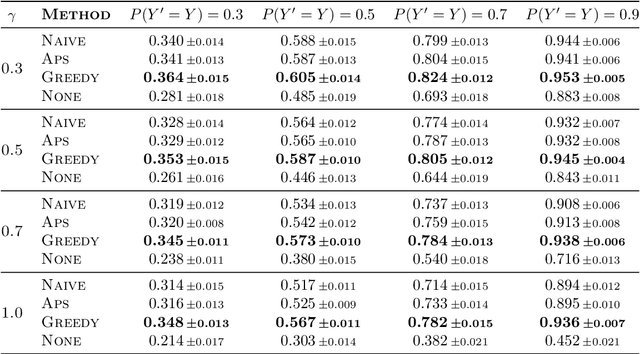
Decision support systems based on prediction sets help humans solve multiclass classification tasks by narrowing down the set of potential label values to a subset of them, namely a prediction set, and asking them to always predict label values from the prediction sets. While this type of systems have been proven to be effective at improving the average accuracy of the predictions made by humans, by restricting human agency, they may cause harm$\unicode{x2014}$a human who has succeeded at predicting the ground-truth label of an instance on their own may have failed had they used these systems. In this paper, our goal is to control how frequently a decision support system based on prediction sets may cause harm, by design. To this end, we start by characterizing the above notion of harm using the theoretical framework of structural causal models. Then, we show that, under a natural, albeit unverifiable, monotonicity assumption, we can estimate how frequently a system may cause harm using only predictions made by humans on their own. Further, we also show that, under a weaker monotonicity assumption, which can be verified experimentally, we can bound how frequently a system may cause harm again using only predictions made by humans on their own. Building upon these assumptions, we introduce a computational framework to design decision support systems based on prediction sets that are guaranteed to cause harm less frequently than a user-specified value using conformal risk control. We validate our framework using real human predictions from two different human subject studies and show that, in decision support systems based on prediction sets, there is a trade-off between accuracy and counterfactual harm.
Towards Human-AI Complementarity with Predictions Sets
May 27, 2024
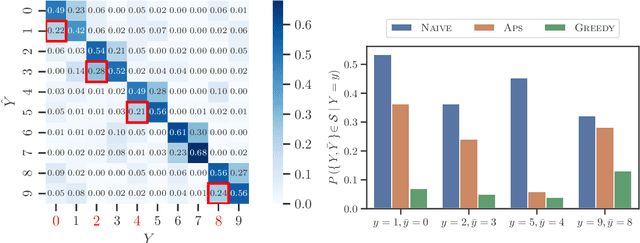

Decision support systems based on prediction sets have proven to be effective at helping human experts solve classification tasks. Rather than providing single-label predictions, these systems provide sets of label predictions constructed using conformal prediction, namely prediction sets, and ask human experts to predict label values from these sets. In this paper, we first show that the prediction sets constructed using conformal prediction are, in general, suboptimal in terms of average accuracy. Then, we show that the problem of finding the optimal prediction sets under which the human experts achieve the highest average accuracy is NP-hard. More strongly, unless P = NP, we show that the problem is hard to approximate to any factor less than the size of the label set. However, we introduce a simple and efficient greedy algorithm that, for a large class of expert models and non-conformity scores, is guaranteed to find prediction sets that provably offer equal or greater performance than those constructed using conformal prediction. Further, using a simulation study with both synthetic and real expert predictions, we demonstrate that, in practice, our greedy algorithm finds near-optimal prediction sets offering greater performance than conformal prediction.
Prediction-Powered Ranking of Large Language Models
Feb 27, 2024Large language models are often ranked according to their level of alignment with human preferences -- a model is better than other models if its outputs are more frequently preferred by humans. One of the most popular ways to elicit human preferences utilizes pairwise comparisons between the outputs provided by different models to the same inputs. However, since gathering pairwise comparisons by humans is costly and time-consuming, it has become a very common practice to gather pairwise comparisons by a strong large language model -- a model strongly aligned with human preferences. Surprisingly, practitioners cannot currently measure the uncertainty that any mismatch between human and model preferences may introduce in the constructed rankings. In this work, we develop a statistical framework to bridge this gap. Given a small set of pairwise comparisons by humans and a large set of pairwise comparisons by a model, our framework provides a rank-set -- a set of possible ranking positions -- for each of the models under comparison. Moreover, it guarantees that, with a probability greater than or equal to a user-specified value, the rank-sets cover the true ranking consistent with (the distribution of) human pairwise preferences. Our framework is computationally efficient, easy to use, and does not make any assumption about the distribution of human preferences nor about the degree of alignment between the pairwise comparisons by the humans and the strong large language model.
Designing Decision Support Systems Using Counterfactual Prediction Sets
Jun 06, 2023

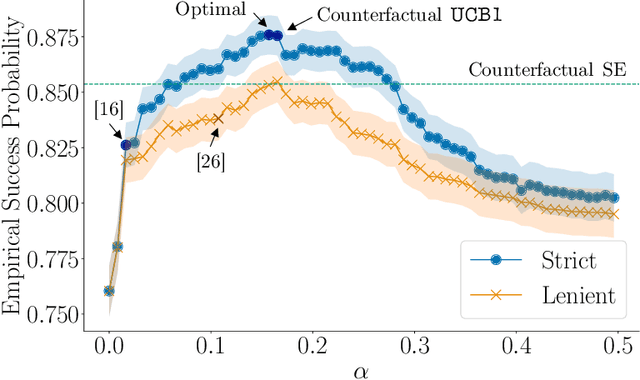

Decision support systems for classification tasks are predominantly designed to predict the value of the ground truth labels. However, since their predictions are not perfect, these systems also need to make human experts understand when and how to use these predictions to update their own predictions. Unfortunately, this has been proven challenging. In this context, it has been recently argued that an alternative type of decision support systems may circumvent this challenge. Rather than providing a single label prediction, these systems provide a set of label prediction values constructed using a conformal predictor, namely a prediction set, and forcefully ask experts to predict a label value from the prediction set. However, the design and evaluation of these systems have so far relied on stylized expert models, questioning their promise. In this paper, we revisit the design of this type of systems from the perspective of online learning and develop a methodology that does not require, nor assumes, an expert model. Our methodology leverages the nested structure of the prediction sets provided by any conformal predictor and a natural counterfactual monotonicity assumption on the experts' predictions over the prediction sets to achieve an exponential improvement in regret in comparison with vanilla bandit algorithms. We conduct a large-scale human subject study ($n = 2{,}751$) to verify our counterfactual monotonicity assumption and compare our methodology to several competitive baselines. The results suggest that decision support systems that limit experts' level of agency may be practical and may offer greater performance than those allowing experts to always exercise their own agency.
Provably Improving Expert Predictions with Conformal Prediction
Jan 31, 2022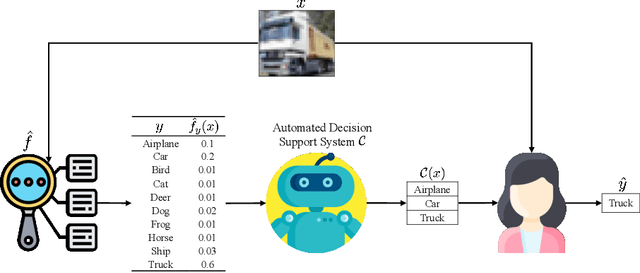
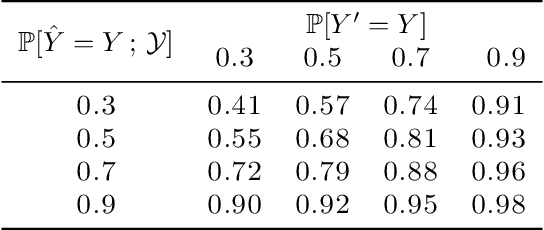
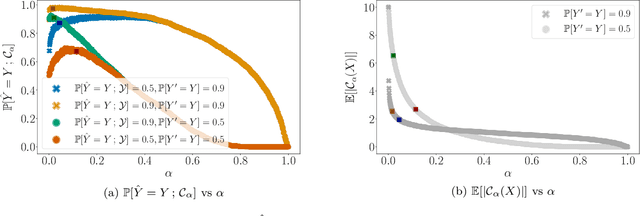

Automated decision support systems promise to help human experts solve tasks more efficiently and accurately. However, existing systems typically require experts to understand when to cede agency to the system or when to exercise their own agency. Moreover, if the experts develop a misplaced trust in the system, their performance may worsen. In this work, we lift the above requirement and develop automated decision support systems that, by design, do not require experts to understand when to trust them to provably improve their performance. To this end, we focus on multiclass classification tasks and consider automated decision support systems that, for each data sample, use a classifier to recommend a subset of labels to a human expert. We first show that, by looking at the design of such systems from the perspective of conformal prediction, we can ensure that the probability that the recommended subset of labels contains the true label matches almost exactly a target probability value. Then, we identify the set of target probability values under which the human expert is provably better off predicting a label among those in the recommended subset and develop an efficient practical method to find a near-optimal target probability value. Experiments on synthetic and real data demonstrate that our system can help the experts make more accurate predictions and is robust to the accuracy of the classifier it relies on.
Reinforcement Learning Under Algorithmic Triage
Sep 23, 2021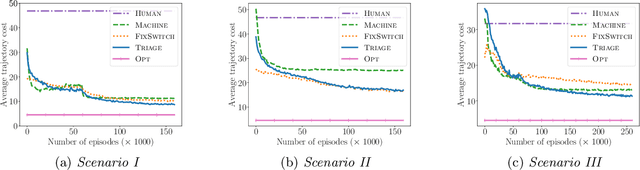
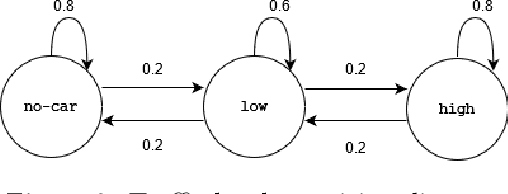
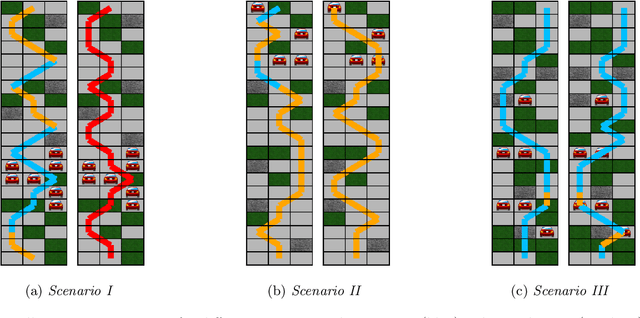
Methods to learn under algorithmic triage have predominantly focused on supervised learning settings where each decision, or prediction, is independent of each other. Under algorithmic triage, a supervised learning model predicts a fraction of the instances and humans predict the remaining ones. In this work, we take a first step towards developing reinforcement learning models that are optimized to operate under algorithmic triage. To this end, we look at the problem through the framework of options and develop a two-stage actor-critic method to learn reinforcement learning models under triage. The first stage performs offline, off-policy training using human data gathered in an environment where the human has operated on their own. The second stage performs on-policy training to account for the impact that switching may have on the human policy, which may be difficult to anticipate from the above human data. Extensive simulation experiments in a synthetic car driving task show that the machine models and the triage policies trained using our two-stage method effectively complement human policies and outperform those provided by several competitive baselines.