 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Under Algorithmic Triage
Sep 23, 2021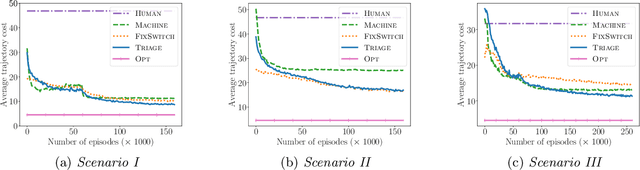
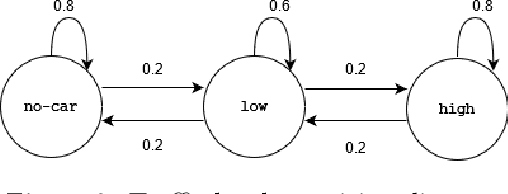
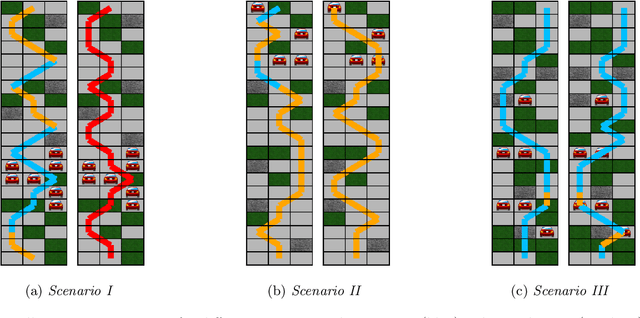
Methods to learn under algorithmic triage have predominantly focused on supervised learning settings where each decision, or prediction, is independent of each other. Under algorithmic triage, a supervised learning model predicts a fraction of the instances and humans predict the remaining ones. In this work, we take a first step towards developing reinforcement learning models that are optimized to operate under algorithmic triage. To this end, we look at the problem through the framework of options and develop a two-stage actor-critic method to learn reinforcement learning models under triage. The first stage performs offline, off-policy training using human data gathered in an environment where the human has operated on their own. The second stage performs on-policy training to account for the impact that switching may have on the human policy, which may be difficult to anticipate from the above human data. Extensive simulation experiments in a synthetic car driving task show that the machine models and the triage policies trained using our two-stage method effectively complement human policies and outperform those provided by several competitive baselines.
Learning to Switch Between Machines and Humans
Feb 11, 2020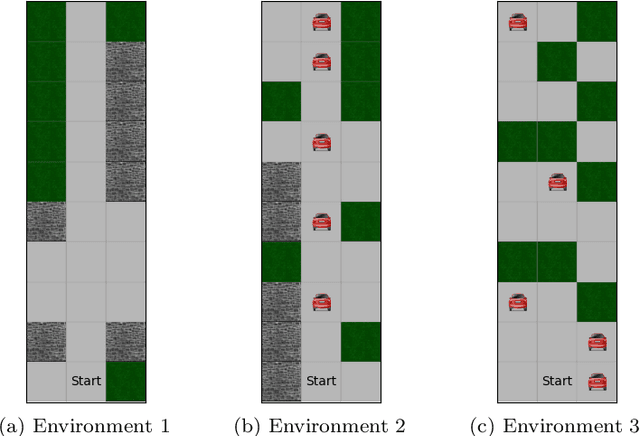
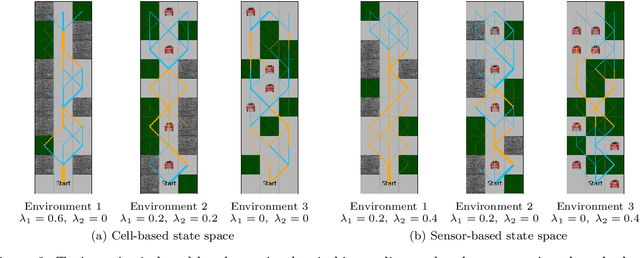
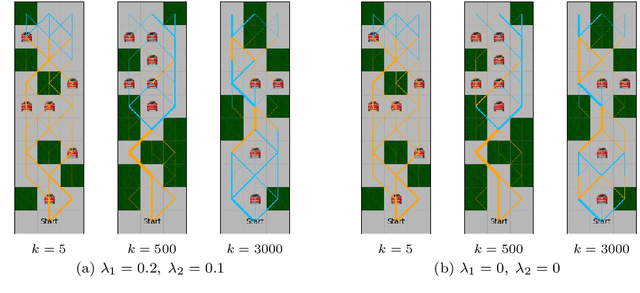
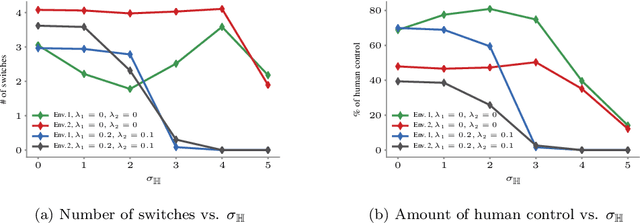
Reinforcement learning algorithms have been mostly developed and evaluated under the assumption that they will operate in a fully autonomous manner---they will take all actions. However, in safety critical applications, full autonomy faces a variety of technical, societal and legal challenges, which have precluded the use of reinforcement learning policies in real-world systems. In this work, our goal is to develop algorithms that, by learning to switch control between machines and humans, allow existing reinforcement learning policies to operate under different automation levels. More specifically, we first formally define the learning to switch problem using finite horizon Markov decision processes. Then, we show that, if the human policy is known, we can find the optimal switching policy directly by solving a set of recursive equations using backwards induction. However, in practice, the human policy is often unknown. To overcome this, we develop an algorithm that uses upper confidence bounds on the human policy to find a sequence of switching policies whose total regret with respect to the optimal switching policy is sublinear. Simulation experiments on two important tasks in autonomous driving---lane keeping and obstacle avoidance---demonstrate the effectiveness of the proposed algorithms and illustrate our theoretical findings.