 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Switch Between Machines and Humans
Paper and Code
Feb 11, 2020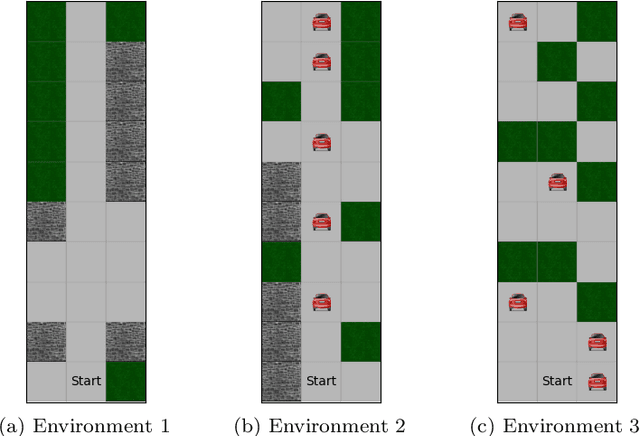
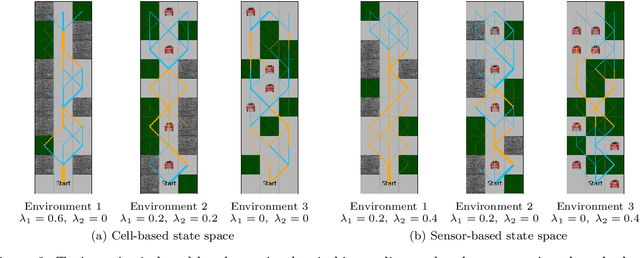
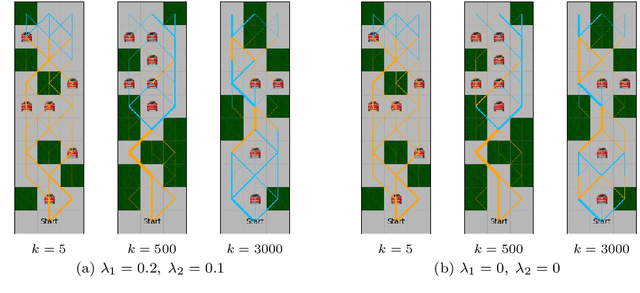
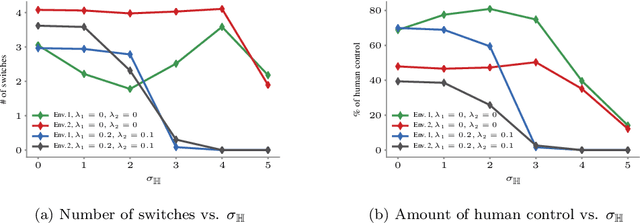
Reinforcement learning algorithms have been mostly developed and evaluated under the assumption that they will operate in a fully autonomous manner---they will take all actions. However, in safety critical applications, full autonomy faces a variety of technical, societal and legal challenges, which have precluded the use of reinforcement learning policies in real-world systems. In this work, our goal is to develop algorithms that, by learning to switch control between machines and humans, allow existing reinforcement learning policies to operate under different automation levels. More specifically, we first formally define the learning to switch problem using finite horizon Markov decision processes. Then, we show that, if the human policy is known, we can find the optimal switching policy directly by solving a set of recursive equations using backwards induction. However, in practice, the human policy is often unknown. To overcome this, we develop an algorithm that uses upper confidence bounds on the human policy to find a sequence of switching policies whose total regret with respect to the optimal switching policy is sublinear. Simulation experiments on two important tasks in autonomous driving---lane keeping and obstacle avoidance---demonstrate the effectiveness of the proposed algorithms and illustrate our theoretical findings.