 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Reachability: Guaranteeing Asymptotic Optimality
May 23, 2026Reinforcement learning (RL) for reachability specifications is fundamental in sequential decision-making, yet theoretical guarantees remain less explored. A recent work achieves asymptotic convergence to optimal policies. However, this approach provides limited insight into convergence dynamics. In this work, we present an alternative approach that provides deeper theoretical insights into convergence. Our approach builds on PAC learning with assumptions. PAC learning guarantees near-optimal policies with high confidence in finite time but requires knowing internal MDP parameters like minimum transition probability. We argue that while these parameters are unknown in RL, they can be iteratively refined and estimated with increasing accuracy. By iteratively satisfying PAC conditions, we show that exact optimality can be achieved in the limit. Empirical evaluations on standard benchmarks validate our theoretical insights into convergence dynamics.
Automated Approach for Solving Infinite-state Polynomial Reachability Games
May 11, 2026Reachability games are two-player games played on a graph, where the objective of $\texttt{REACH}$ player is to reach the target set whereas the objective of $\texttt{SAFE}$ player is to stay away from the target set. Reachability games have important applications in artificial intelligence and reactive synthesis, and many of these applications give rise to infinite-state reachability games. In this paper, we study turn-based reachability games on infinite-state graphs defined over valuations of a finite set of real variables. We consider the problem of determining the existence of and computing a winning strategy for $\texttt{REACH}$ player. Our contributions are twofold. First, we propose ranking certificates for reachability games, a sound and complete proof rule for proving that $\texttt{REACH}$ player has a winning strategy from the specified initial state. Second, we consider polynomial reachability games, where transitions and objectives are described by polynomial constraints over real variables, and propose a fully automated algorithm for computing a winning strategy for $\texttt{REACH}$ player together with a formal correctness witness in the form of a ranking certificate. The algorithm is sound, semi-complete, and runs in sub-exponential time. Our experiments demonstrate the ability of our method to solve challenging examples from the literature that were out of the reach of existing methods. Specifically, for the classical Cinderella-Stepmother game, we are able to compute an optimal winning strategy for an arbitrary precision parameter for the first time.
Strongly Polynomial Time Complexity of Policy Iteration for $L_\infty$ Robust MDPs
Jan 30, 2026Markov decision processes (MDPs) are a fundamental model in sequential decision making. Robust MDPs (RMDPs) extend this framework by allowing uncertainty in transition probabilities and optimizing against the worst-case realization of that uncertainty. In particular, $(s, a)$-rectangular RMDPs with $L_\infty$ uncertainty sets form a fundamental and expressive model: they subsume classical MDPs and turn-based stochastic games. We consider this model with discounted payoffs. The existence of polynomial and strongly-polynomial time algorithms is a fundamental problem for these optimization models. For MDPs, linear programming yields polynomial-time algorithms for any arbitrary discount factor, and the seminal work of Ye established strongly--polynomial time for a fixed discount factor. The generalization of such results to RMDPs has remained an important open problem. In this work, we show that a robust policy iteration algorithm runs in strongly-polynomial time for $(s, a)$-rectangular $L_\infty$ RMDPs with a constant (fixed) discount factor, resolving an important algorithmic question.
Lower Bound on Howard Policy Iteration for Deterministic Markov Decision Processes
Jun 13, 2025



Deterministic Markov Decision Processes (DMDPs) are a mathematical framework for decision-making where the outcomes and future possible actions are deterministically determined by the current action taken. DMDPs can be viewed as a finite directed weighted graph, where in each step, the controller chooses an outgoing edge. An objective is a measurable function on runs (or infinite trajectories) of the DMDP, and the value for an objective is the maximal cumulative reward (or weight) that the controller can guarantee. We consider the classical mean-payoff (aka limit-average) objective, which is a basic and fundamental objective. Howard's policy iteration algorithm is a popular method for solving DMDPs with mean-payoff objectives. Although Howard's algorithm performs well in practice, as experimental studies suggested, the best known upper bound is exponential and the current known lower bound is as follows: For the input size $I$, the algorithm requires $\tilde{\Omega}(\sqrt{I})$ iterations, where $\tilde{\Omega}$ hides the poly-logarithmic factors, i.e., the current lower bound on iterations is sub-linear with respect to the input size. Our main result is an improved lower bound for this fundamental algorithm where we show that for the input size $I$, the algorithm requires $\tilde{\Omega}(I)$ iterations.
Value Iteration with Guessing for Markov Chains and Markov Decision Processes
May 10, 2025Two standard models for probabilistic systems are Markov chains (MCs) and Markov decision processes (MDPs). Classic objectives for such probabilistic models for control and planning problems are reachability and stochastic shortest path. The widely studied algorithmic approach for these problems is the Value Iteration (VI) algorithm which iteratively applies local updates called Bellman updates. There are many practical approaches for VI in the literature but they all require exponentially many Bellman updates for MCs in the worst case. A preprocessing step is an algorithm that is discrete, graph-theoretical, and requires linear space. An important open question is whether, after a polynomial-time preprocessing, VI can be achieved with sub-exponentially many Bellman updates. In this work, we present a new approach for VI based on guessing values. Our theoretical contributions are twofold. First, for MCs, we present an almost-linear-time preprocessing algorithm after which, along with guessing values, VI requires only subexponentially many Bellman updates. Second, we present an improved analysis of the speed of convergence of VI for MDPs. Finally, we present a practical algorithm for MDPs based on our new approach. Experimental results show that our approach provides a considerable improvement over existing VI-based approaches on several benchmark examples from the literature.
Qualitative Analysis of $ω$-Regular Objectives on Robust MDPs
May 07, 2025



Robust Markov Decision Processes (RMDPs) generalize classical MDPs that consider uncertainties in transition probabilities by defining a set of possible transition functions. An objective is a set of runs (or infinite trajectories) of the RMDP, and the value for an objective is the maximal probability that the agent can guarantee against the adversarial environment. We consider (a) reachability objectives, where given a target set of states, the goal is to eventually arrive at one of them; and (b) parity objectives, which are a canonical representation for $\omega$-regular objectives. The qualitative analysis problem asks whether the objective can be ensured with probability 1. In this work, we study the qualitative problem for reachability and parity objectives on RMDPs without making any assumption over the structures of the RMDPs, e.g., unichain or aperiodic. Our contributions are twofold. We first present efficient algorithms with oracle access to uncertainty sets that solve qualitative problems of reachability and parity objectives. We then report experimental results demonstrating the effectiveness of our oracle-based approach on classical RMDP examples from the literature scaling up to thousands of states.
Quantified Linear and Polynomial Arithmetic Satisfiability via Template-based Skolemization
Dec 18, 2024The problem of checking satisfiability of linear real arithmetic (LRA) and non-linear real arithmetic (NRA) formulas has broad applications, in particular, they are at the heart of logic-related applications such as logic for artificial intelligence, program analysis, etc. While there has been much work on checking satisfiability of unquantified LRA and NRA formulas, the problem of checking satisfiability of quantified LRA and NRA formulas remains a significant challenge. The main bottleneck in the existing methods is a computationally expensive quantifier elimination step. In this work, we propose a novel method for efficient quantifier elimination in quantified LRA and NRA formulas. We propose a template-based Skolemization approach, where we automatically synthesize linear/polynomial Skolem functions in order to eliminate quantifiers in the formula. The key technical ingredients in our approach are Positivstellens\"atze theorems from algebraic geometry, which allow for an efficient manipulation of polynomial inequalities. Our method offers a range of appealing theoretical properties combined with a strong practical performance. On the theory side, our method is sound, semi-complete, and runs in subexponential time and polynomial space, as opposed to existing sound and complete quantifier elimination methods that run in doubly-exponential time and at least exponential space. On the practical side, our experiments show superior performance compared to state-of-the-art SMT solvers in terms of the number of solved instances and runtime, both on LRA and on NRA benchmarks.
Linear Equations with Min and Max Operators: Computational Complexity
Dec 16, 2024We consider a class of optimization problems defined by a system of linear equations with min and max operators. This class of optimization problems has been studied under restrictive conditions, such as, (C1) the halting or stability condition; (C2) the non-negative coefficients condition; (C3) the sum up to 1 condition; and (C4) the only min or only max oerator condition. Several seminal results in the literature focus on special cases. For example, turn-based stochastic games correspond to conditions C2 and C3; and Markov decision process to conditions C2, C3, and C4. However, the systematic computational complexity study of all the cases has not been explored, which we address in this work. Some highlights of our results are: with conditions C2 and C4, and with conditions C3 and C4, the problem is NP-complete, whereas with condition C1 only, the problem is in UP intersects coUP. Finally, we establish the computational complexity of the decision problem of checking the respective conditions.
Certified Policy Verification and Synthesis for MDPs under Distributional Reach-avoidance Properties
May 07, 2024



Markov Decision Processes (MDPs) are a classical model for decision making in the presence of uncertainty. Often they are viewed as state transformers with planning objectives defined with respect to paths over MDP states. An increasingly popular alternative is to view them as distribution transformers, giving rise to a sequence of probability distributions over MDP states. For instance, reachability and safety properties in modeling robot swarms or chemical reaction networks are naturally defined in terms of probability distributions over states. Verifying such distributional properties is known to be hard and often beyond the reach of classical state-based verification techniques. In this work, we consider the problems of certified policy (i.e. controller) verification and synthesis in MDPs under distributional reach-avoidance specifications. By certified we mean that, along with a policy, we also aim to synthesize a (checkable) certificate ensuring that the MDP indeed satisfies the property. Thus, given the target set of distributions and an unsafe set of distributions over MDP states, our goal is to either synthesize a certificate for a given policy or synthesize a policy along with a certificate, proving that the target distribution can be reached while avoiding unsafe distributions. To solve this problem, we introduce the novel notion of distributional reach-avoid certificates and present automated procedures for (1) synthesizing a certificate for a given policy, and (2) synthesizing a policy together with the certificate, both providing formal guarantees on certificate correctness. Our experimental evaluation demonstrates the ability of our method to solve several non-trivial examples, including a multi-agent robot-swarm model, to synthesize certified policies and to certify existing policies.
Learning Algorithms for Verification of Markov Decision Processes
Mar 20, 2024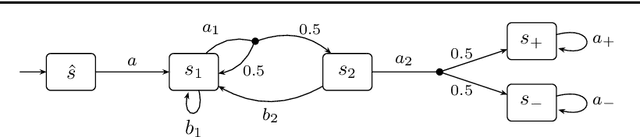
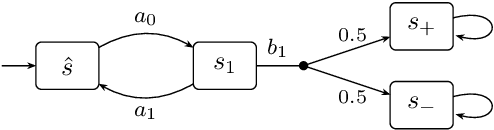
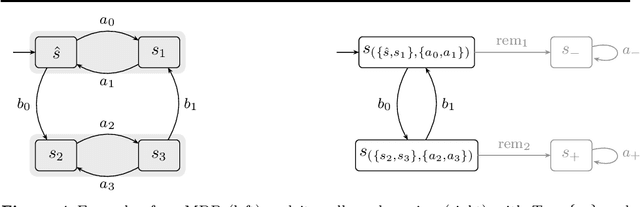

We present a general framework for applying learning algorithms and heuristical guidance to the verification of Markov decision processes (MDPs). The primary goal of our techniques is to improve performance by avoiding an exhaustive exploration of the state space, instead focussing on particularly relevant areas of the system, guided by heuristics. Our work builds on the previous results of Br{\'{a}}zdil et al., significantly extending it as well as refining several details and fixing errors. The presented framework focuses on probabilistic reachability, which is a core problem in verification, and is instantiated in two distinct scenarios. The first assumes that full knowledge of the MDP is available, in particular precise transition probabilities. It performs a heuristic-driven partial exploration of the model, yielding precise lower and upper bounds on the required probability. The second tackles the case where we may only sample the MDP without knowing the exact transition dynamics. Here, we obtain probabilistic guarantees, again in terms of both the lower and upper bounds, which provides efficient stopping criteria for the approximation. In particular, the latter is an extension of statistical model-checking (SMC) for unbounded properties in MDPs. In contrast to other related approaches, we do not restrict our attention to time-bounded (finite-horizon) or discounted properties, nor assume any particular structural properties of the MDP.