 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Multicenter Nancy Index Scoring in Ulcerative Colitis Using Foundation Models
Apr 26, 2026Histologic assessment of ulcerative colitis (UC) activity is an important endpoint in clinical trials and routine care, but manual grading with indices such as the Nancy histological index (NHI) is time-consuming and prone to observer variability. While computational pathology methods can automate scoring, many approaches depend on dense region-level annotations, which are costly to obtain, particularly in heterogeneous, multicenter cohorts. We propose a weakly supervised multiple instance learning (MIL) approach for whole-slide images that learns from case- and slide-level NHI labels, leveraging foundation models. Our method targets clinically relevant endpoints, including neutrophilic activity and derived Nancy-low/high groupings, enabling full five-grade NHI prediction. On a multicenter dataset of H&E-stained colon biopsies from three hospitals (2019-2025), we evaluate multiple foundation model encoders and aggregation strategies. We find that foundation model choice and resolution substantially affect performance, with Virchow2 providing the most consistent gains, and that a simple ensembling rule improves five-grade NHI prediction compared to a hierarchical gating baseline. Overall, our results demonstrate that weakly supervised MIL with modern foundation-model representations can provide robust, interpretable UC histology activity assessment in realistic multicenter settings.
LSP-DETR: Efficient and Scalable Nuclei Segmentation in Whole Slide Images
Jan 06, 2026Precise and scalable instance segmentation of cell nuclei is essential for computational pathology, yet gigapixel Whole-Slide Images pose major computational challenges. Existing approaches rely on patch-based processing and costly post-processing for instance separation, sacrificing context and efficiency. We introduce LSP-DETR (Local Star Polygon DEtection TRansformer), a fully end-to-end framework that uses a lightweight transformer with linear complexity to process substantially larger images without additional computational cost. Nuclei are represented as star-convex polygons, and a novel radial distance loss function allows the segmentation of overlapping nuclei to emerge naturally, without requiring explicit overlap annotations or handcrafted post-processing. Evaluations on PanNuke and MoNuSeg show strong generalization across tissues and state-of-the-art efficiency, with LSP-DETR being over five times faster than the next-fastest leading method. Code and models are available at https://github.com/RationAI/lsp-detr.
Beyond Occlusion: In Search for Near Real-Time Explainability of CNN-Based Prostate Cancer Classification
Dec 19, 2025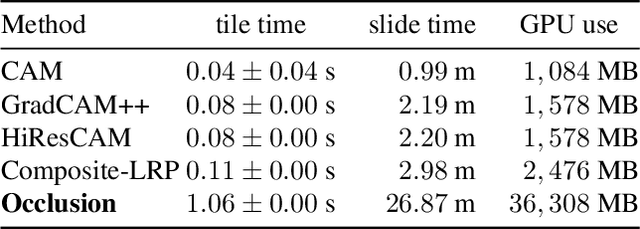
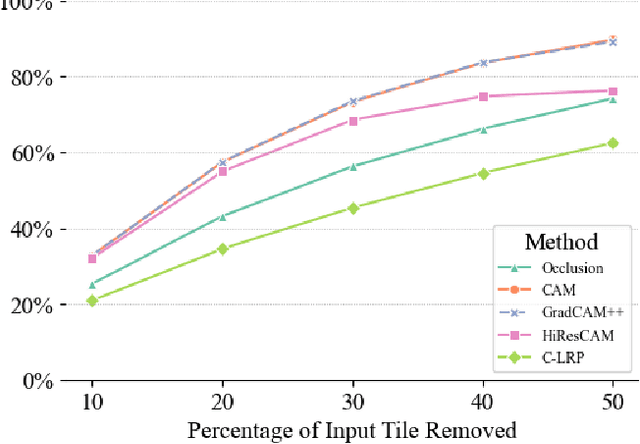
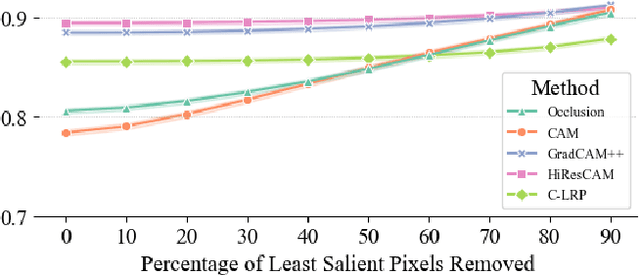
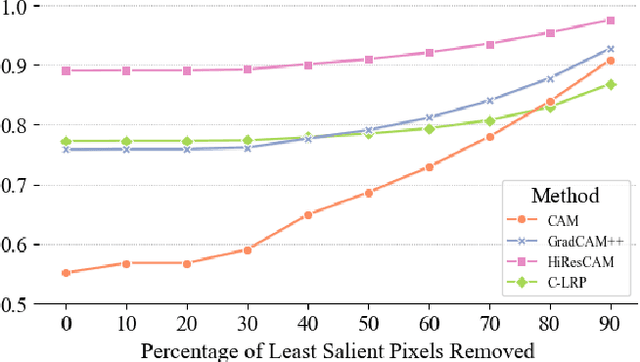
Deep neural networks are starting to show their worth in critical applications such as assisted cancer diagnosis. However, for their outputs to get accepted in practice, the results they provide should be explainable in a way easily understood by pathologists. A well-known and widely used explanation technique is occlusion, which, however, can take a long time to compute, thus slowing the development and interaction with pathologists. In this work, we set out to find a faster replacement for occlusion in a successful system for detecting prostate cancer. Since there is no established framework for comparing the performance of various explanation methods, we first identified suitable comparison criteria and selected corresponding metrics. Based on the results, we were able to choose a different explanation method, which cut the previously required explanation time at least by a factor of 10, without any negative impact on the quality of outputs. This speedup enables rapid iteration in model development and debugging and brings us closer to adopting AI-assisted prostate cancer detection in clinical settings. We propose that our approach to finding the replacement for occlusion can be used to evaluate candidate methods in other related applications.
Explaining Digital Pathology Models via Clustering Activations
Nov 18, 2025We present a clustering-based explainability technique for digital pathology models based on convolutional neural networks. Unlike commonly used methods based on saliency maps, such as occlusion, GradCAM, or relevance propagation, which highlight regions that contribute the most to the prediction for a single slide, our method shows the global behaviour of the model under consideration, while also providing more fine-grained information. The result clusters can be visualised not only to understand the model, but also to increase confidence in its operation, leading to faster adoption in clinical practice. We also evaluate the performance of our technique on an existing model for detecting prostate cancer, demonstrating its usefulness.
Learning Algorithms for Verification of Markov Decision Processes
Mar 20, 2024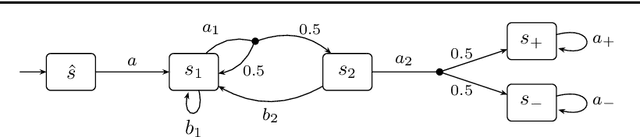
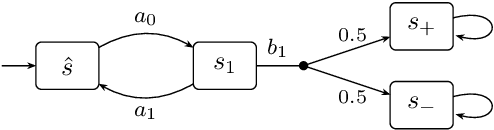
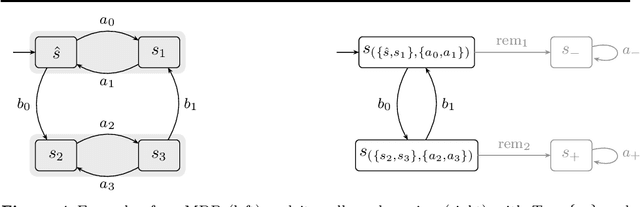

We present a general framework for applying learning algorithms and heuristical guidance to the verification of Markov decision processes (MDPs). The primary goal of our techniques is to improve performance by avoiding an exhaustive exploration of the state space, instead focussing on particularly relevant areas of the system, guided by heuristics. Our work builds on the previous results of Br{\'{a}}zdil et al., significantly extending it as well as refining several details and fixing errors. The presented framework focuses on probabilistic reachability, which is a core problem in verification, and is instantiated in two distinct scenarios. The first assumes that full knowledge of the MDP is available, in particular precise transition probabilities. It performs a heuristic-driven partial exploration of the model, yielding precise lower and upper bounds on the required probability. The second tackles the case where we may only sample the MDP without knowing the exact transition dynamics. Here, we obtain probabilistic guarantees, again in terms of both the lower and upper bounds, which provides efficient stopping criteria for the approximation. In particular, the latter is an extension of statistical model-checking (SMC) for unbounded properties in MDPs. In contrast to other related approaches, we do not restrict our attention to time-bounded (finite-horizon) or discounted properties, nor assume any particular structural properties of the MDP.
Synthesizing Efficient Solutions for Patrolling Problems in the Internet Environment
May 10, 2018

We propose an algorithm for constructing efficient patrolling strategies in the Internet environment, where the protected targets are nodes connected to the network and the patrollers are software agents capable of detecting/preventing undesirable activities on the nodes. The algorithm is based on a novel compositional principle designed for a special class of strategies, and it can quickly construct (sub)optimal solutions even if the number of targets reaches hundreds of millions.
Stochastic Shortest Path with Energy Constraints in POMDPs
May 11, 2016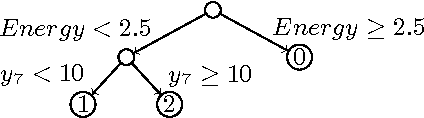
We consider partially observable Markov decision processes (POMDPs) with a set of target states and positive integer costs associated with every transition. The traditional optimization objective (stochastic shortest path) asks to minimize the expected total cost until the target set is reached. We extend the traditional framework of POMDPs to model energy consumption, which represents a hard constraint. The energy levels may increase and decrease with transitions, and the hard constraint requires that the energy level must remain positive in all steps till the target is reached. First, we present a novel algorithm for solving POMDPs with energy levels, developing on existing POMDP solvers and using RTDP as its main method. Our second contribution is related to policy representation. For larger POMDP instances the policies computed by existing solvers are too large to be understandable. We present an automated procedure based on machine learning techniques that automatically extracts important decisions of the policy allowing us to compute succinct human readable policies. Finally, we show experimentally that our algorithm performs well and computes succinct policies on a number of POMDP instances from the literature that were naturally enhanced with energy levels.
MultiGain: A controller synthesis tool for MDPs with multiple mean-payoff objectives
Jan 13, 2015


We present MultiGain, a tool to synthesize strategies for Markov decision processes (MDPs) with multiple mean-payoff objectives. Our models are described in PRISM, and our tool uses the existing interface and simulator of PRISM. Our tool extends PRISM by adding novel algorithms for multiple mean-payoff objectives, and also provides features such as (i)~generating strategies and exploring them for simulation, and checking them with respect to other properties; and (ii)~generating an approximate Pareto curve for two mean-payoff objectives. In addition, we present a new practical algorithm for the analysis of MDPs with multiple mean-payoff objectives under memoryless strategies.