 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Algorithms for Verification of Markov Decision Processes
Mar 20, 2024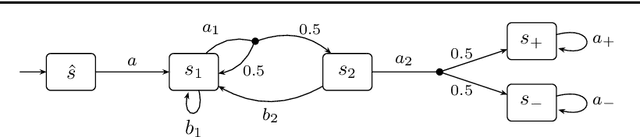
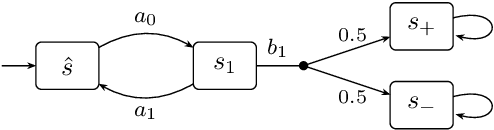
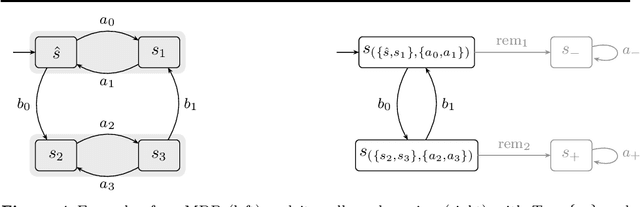

We present a general framework for applying learning algorithms and heuristical guidance to the verification of Markov decision processes (MDPs). The primary goal of our techniques is to improve performance by avoiding an exhaustive exploration of the state space, instead focussing on particularly relevant areas of the system, guided by heuristics. Our work builds on the previous results of Br{\'{a}}zdil et al., significantly extending it as well as refining several details and fixing errors. The presented framework focuses on probabilistic reachability, which is a core problem in verification, and is instantiated in two distinct scenarios. The first assumes that full knowledge of the MDP is available, in particular precise transition probabilities. It performs a heuristic-driven partial exploration of the model, yielding precise lower and upper bounds on the required probability. The second tackles the case where we may only sample the MDP without knowing the exact transition dynamics. Here, we obtain probabilistic guarantees, again in terms of both the lower and upper bounds, which provides efficient stopping criteria for the approximation. In particular, the latter is an extension of statistical model-checking (SMC) for unbounded properties in MDPs. In contrast to other related approaches, we do not restrict our attention to time-bounded (finite-horizon) or discounted properties, nor assume any particular structural properties of the MDP.
MultiGain: A controller synthesis tool for MDPs with multiple mean-payoff objectives
Jan 13, 2015


We present MultiGain, a tool to synthesize strategies for Markov decision processes (MDPs) with multiple mean-payoff objectives. Our models are described in PRISM, and our tool uses the existing interface and simulator of PRISM. Our tool extends PRISM by adding novel algorithms for multiple mean-payoff objectives, and also provides features such as (i)~generating strategies and exploring them for simulation, and checking them with respect to other properties; and (ii)~generating an approximate Pareto curve for two mean-payoff objectives. In addition, we present a new practical algorithm for the analysis of MDPs with multiple mean-payoff objectives under memoryless strategies.