 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlia: A Human-Inspired AI for Automated Systems Design and Optimization
Oct 31, 2025Can an AI autonomously design mechanisms for computer systems on par with the creativity and reasoning of human experts? We present Glia, an AI architecture for networked systems design that uses large language models (LLMs) in a human-inspired, multi-agent workflow. Each agent specializes in reasoning, experimentation, and analysis, collaborating through an evaluation framework that grounds abstract reasoning in empirical feedback. Unlike prior ML-for-systems methods that optimize black-box policies, Glia generates interpretable designs and exposes its reasoning process. When applied to a distributed GPU cluster for LLM inference, it produces new algorithms for request routing, scheduling, and auto-scaling that perform at human-expert levels in significantly less time, while yielding novel insights into workload behavior. Our results suggest that by combining reasoning LLMs with structured experimentation, an AI can produce creative and understandable designs for complex systems problems.
Savaal: Scalable Concept-Driven Question Generation to Enhance Human Learning
Feb 18, 2025
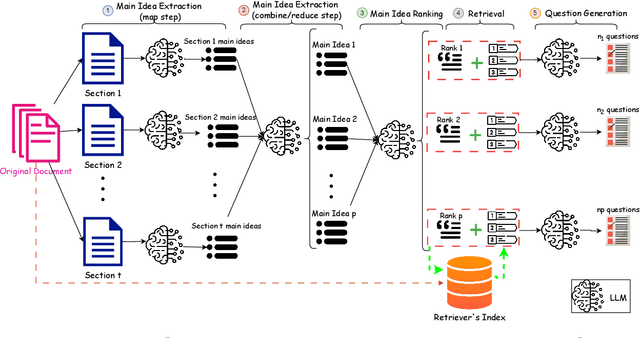


Assessing and enhancing human learning through question-answering is vital, yet automating this process remains challenging. While large language models (LLMs) excel at summarization and query responses, their ability to generate meaningful questions for learners is underexplored. We propose Savaal, a scalable question-generation system with three objectives: (i) scalability, enabling question generation from hundreds of pages of text (ii) depth of understanding, producing questions beyond factual recall to test conceptual reasoning, and (iii) domain-independence, automatically generating questions across diverse knowledge areas. Instead of providing an LLM with large documents as context, Savaal improves results with a three-stage processing pipeline. Our evaluation with 76 human experts on 71 papers and PhD dissertations shows that Savaal generates questions that better test depth of understanding by 6.5X for dissertations and 1.5X for papers compared to a direct-prompting LLM baseline. Notably, as document length increases, Savaal's advantages in higher question quality and lower cost become more pronounced.
Vision Models Can Be Efficiently Specialized via Few-Shot Task-Aware Compression
Mar 25, 2023Recent vision architectures and self-supervised training methods enable vision models that are extremely accurate and general, but come with massive parameter and computational costs. In practical settings, such as camera traps, users have limited resources, and may fine-tune a pretrained model on (often limited) data from a small set of specific categories of interest. These users may wish to make use of modern, highly-accurate models, but are often computationally constrained. To address this, we ask: can we quickly compress large generalist models into accurate and efficient specialists? For this, we propose a simple and versatile technique called Few-Shot Task-Aware Compression (TACO). Given a large vision model that is pretrained to be accurate on a broad task, such as classification over ImageNet-22K, TACO produces a smaller model that is accurate on specialized tasks, such as classification across vehicle types or animal species. Crucially, TACO works in few-shot fashion, i.e. only a few task-specific samples are used, and the procedure has low computational overheads. We validate TACO on highly-accurate ResNet, ViT/DeiT, and ConvNeXt models, originally trained on ImageNet, LAION, or iNaturalist, which we specialize and compress to a diverse set of "downstream" subtasks. TACO can reduce the number of non-zero parameters in existing models by up to 20x relative to the original models, leading to inference speedups of up to 3$\times$, while remaining accuracy-competitive with the uncompressed models on the specialized tasks.
LPF-Defense: 3D Adversarial Defense based on Frequency Analysis
Feb 23, 2022



Although 3D point cloud classification has recently been widely deployed in different application scenarios, it is still very vulnerable to adversarial attacks. This increases the importance of robust training of 3D models in the face of adversarial attacks. Based on our analysis on the performance of existing adversarial attacks, more adversarial perturbations are found in the mid and high-frequency components of input data. Therefore, by suppressing the high-frequency content in the training phase, the models robustness against adversarial examples is improved. Experiments showed that the proposed defense method decreases the success rate of six attacks on PointNet, PointNet++ ,, and DGCNN models. In particular, improvements are achieved with an average increase of classification accuracy by 3.8 % on drop100 attack and 4.26 % on drop200 attack compared to the state-of-the-art methods. The method also improves models accuracy on the original dataset compared to other available methods.
Pre-Trained Language Transformers are Universal Image Classifiers
Jan 25, 2022Facial images disclose many hidden personal traits such as age, gender, race, health, emotion, and psychology. Understanding these traits will help to classify the people in different attributes. In this paper, we have presented a novel method for classifying images using a pretrained transformer model. We apply the pretrained transformer for the binary classification of facial images in criminal and non-criminal classes. The pretrained transformer of GPT-2 is trained to generate text and then fine-tuned to classify facial images. During the finetuning process with images, most of the layers of GT-2 are frozen during backpropagation and the model is frozen pretrained transformer (FPT). The FPT acts as a universal image classifier, and this paper shows the application of FPT on facial images. We also use our FPT on encrypted images for classification. Our FPT shows high accuracy on both raw facial images and encrypted images. We hypothesize the meta-learning capacity FPT gained because of its large size and trained on a large size with theory and experiments. The GPT-2 trained to generate a single word token at a time, through the autoregressive process, forced to heavy-tail distribution. Then the FPT uses the heavy-tail property as its meta-learning capacity for classifying images. Our work shows one way to avoid bias during the machine classification of images.The FPT encodes worldly knowledge because of the pretraining of one text, which it uses during the classification. The statistical error of classification is reduced because of the added context gained from the text.Our paper shows the ethical dimension of using encrypted data for classification.Criminal images are sensitive to share across the boundary but encrypted largely evades ethical concern.FPT showing good classification accuracy on encrypted images shows promise for further research on privacy-preserving machine learning.
Counterfactual Temporal Point Processes
Nov 15, 2021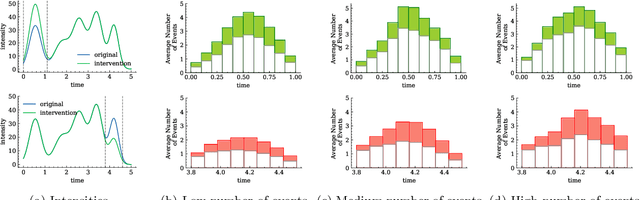


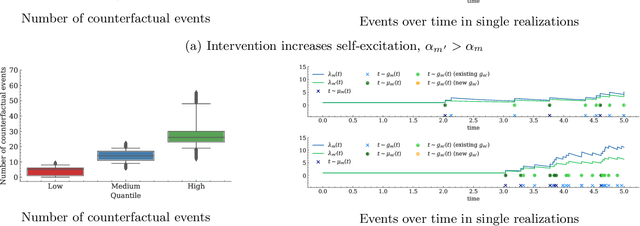
Machine learning models based on temporal point processes are the state of the art in a wide variety of applications involving discrete events in continuous time. However, these models lack the ability to answer counterfactual questions, which are increasingly relevant as these models are being used to inform targeted interventions. In this work, our goal is to fill this gap. To this end, we first develop a causal model of thinning for temporal point processes that builds upon the Gumbel-Max structural causal model. This model satisfies a desirable counterfactual monotonicity condition, which is sufficient to identify counterfactual dynamics in the process of thinning. Then, given an observed realization of a temporal point process with a given intensity function, we develop a sampling algorithm that uses the above causal model of thinning and the superposition theorem to simulate counterfactual realizations of the temporal point process under a given alternative intensity function. Simulation experiments using synthetic and real epidemiological data show that the counterfactual realizations provided by our algorithm may give valuable insights to enhance targeted interventions.
Pretrained Language Models are Symbolic Mathematics Solvers too!
Oct 07, 2021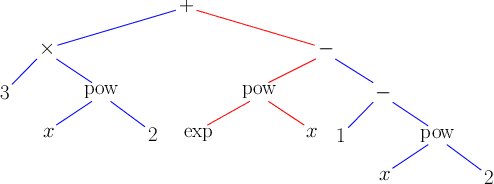

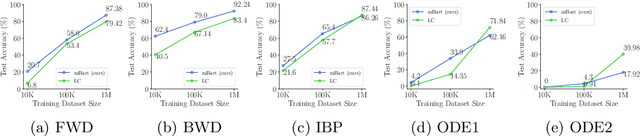
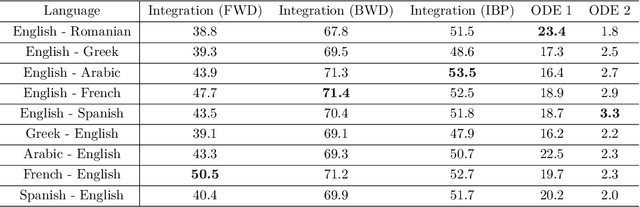
Solving symbolic mathematics has always been of in the arena of human ingenuity that needs compositional reasoning and recurrence. However, recent studies have shown that large-scale language models such as transformers are universal and surprisingly can be trained as a sequence-to-sequence task to solve complex mathematical equations. These large transformer models need humongous amounts of training data to generalize to unseen symbolic mathematics problems. In this paper, we present a sample efficient way of solving the symbolic tasks by first pretraining the transformer model with language translation and then fine-tuning the pretrained transformer model to solve the downstream task of symbolic mathematics. We achieve comparable accuracy on the integration task with our pretrained model while using around $1.5$ orders of magnitude less number of training samples with respect to the state-of-the-art deep learning for symbolic mathematics. The test accuracy on differential equation tasks is considerably lower comparing with integration as they need higher order recursions that are not present in language translations. We pretrain our model with different pairs of language translations. Our results show language bias in solving symbolic mathematics tasks. Finally, we study the robustness of the fine-tuned model on symbolic math tasks against distribution shift, and our approach generalizes better in distribution shift scenarios for the function integration.