 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Trained Language Transformers are Universal Image Classifiers
Jan 25, 2022Facial images disclose many hidden personal traits such as age, gender, race, health, emotion, and psychology. Understanding these traits will help to classify the people in different attributes. In this paper, we have presented a novel method for classifying images using a pretrained transformer model. We apply the pretrained transformer for the binary classification of facial images in criminal and non-criminal classes. The pretrained transformer of GPT-2 is trained to generate text and then fine-tuned to classify facial images. During the finetuning process with images, most of the layers of GT-2 are frozen during backpropagation and the model is frozen pretrained transformer (FPT). The FPT acts as a universal image classifier, and this paper shows the application of FPT on facial images. We also use our FPT on encrypted images for classification. Our FPT shows high accuracy on both raw facial images and encrypted images. We hypothesize the meta-learning capacity FPT gained because of its large size and trained on a large size with theory and experiments. The GPT-2 trained to generate a single word token at a time, through the autoregressive process, forced to heavy-tail distribution. Then the FPT uses the heavy-tail property as its meta-learning capacity for classifying images. Our work shows one way to avoid bias during the machine classification of images.The FPT encodes worldly knowledge because of the pretraining of one text, which it uses during the classification. The statistical error of classification is reduced because of the added context gained from the text.Our paper shows the ethical dimension of using encrypted data for classification.Criminal images are sensitive to share across the boundary but encrypted largely evades ethical concern.FPT showing good classification accuracy on encrypted images shows promise for further research on privacy-preserving machine learning.
Pretrained Language Models are Symbolic Mathematics Solvers too!
Oct 07, 2021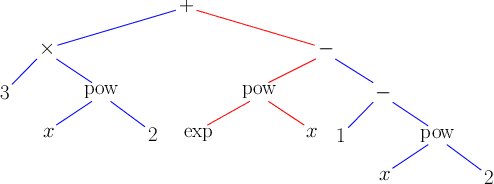

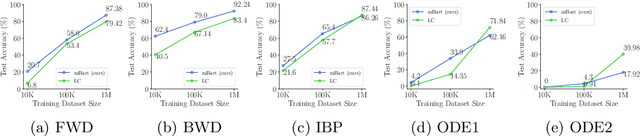
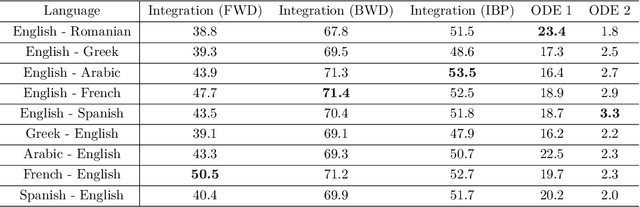
Solving symbolic mathematics has always been of in the arena of human ingenuity that needs compositional reasoning and recurrence. However, recent studies have shown that large-scale language models such as transformers are universal and surprisingly can be trained as a sequence-to-sequence task to solve complex mathematical equations. These large transformer models need humongous amounts of training data to generalize to unseen symbolic mathematics problems. In this paper, we present a sample efficient way of solving the symbolic tasks by first pretraining the transformer model with language translation and then fine-tuning the pretrained transformer model to solve the downstream task of symbolic mathematics. We achieve comparable accuracy on the integration task with our pretrained model while using around $1.5$ orders of magnitude less number of training samples with respect to the state-of-the-art deep learning for symbolic mathematics. The test accuracy on differential equation tasks is considerably lower comparing with integration as they need higher order recursions that are not present in language translations. We pretrain our model with different pairs of language translations. Our results show language bias in solving symbolic mathematics tasks. Finally, we study the robustness of the fine-tuned model on symbolic math tasks against distribution shift, and our approach generalizes better in distribution shift scenarios for the function integration.