 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Coherence and Persistence in Agentic AI for System Optimization
Mar 22, 2026Designing high-performance system heuristics is a creative, iterative process requiring experts to form hypotheses and execute multi-step conceptual shifts. While Large Language Models (LLMs) show promise in automating this loop, they struggle with complex system problems due to two critical failure modes: evolutionary neighborhood bias and the coherence ceiling. Evolutionary methods often remain trapped in local optima by relying on scalar benchmark scores, failing when coordinated multi-step changes are required. Conversely, existing agentic frameworks suffer from context degradation over long horizons or fail to accumulate knowledge across independent runs. We present Engram, an agentic researcher architecture that addresses these limitations by decoupling long-horizon exploration from the constraints of a single context window. Engram organizes exploration into a sequence of agents that iteratively design, test, and analyze mechanisms. At the conclusion of each run, an agent stores code snapshots, logs, and results in a persistent Archive and distills high-level modeling insights into a compact, persistent Research Digest. Subsequent agents then begin with a fresh context window, reading the Research Digest to build on prior discoveries. We find that Engram exhibits superior performance across diverse domains including multi-cloud multicast, LLM inference request routing, and optimizing KV cache reuse in databases with natural language queries.
Glia: A Human-Inspired AI for Automated Systems Design and Optimization
Oct 31, 2025Can an AI autonomously design mechanisms for computer systems on par with the creativity and reasoning of human experts? We present Glia, an AI architecture for networked systems design that uses large language models (LLMs) in a human-inspired, multi-agent workflow. Each agent specializes in reasoning, experimentation, and analysis, collaborating through an evaluation framework that grounds abstract reasoning in empirical feedback. Unlike prior ML-for-systems methods that optimize black-box policies, Glia generates interpretable designs and exposes its reasoning process. When applied to a distributed GPU cluster for LLM inference, it produces new algorithms for request routing, scheduling, and auto-scaling that perform at human-expert levels in significantly less time, while yielding novel insights into workload behavior. Our results suggest that by combining reasoning LLMs with structured experimentation, an AI can produce creative and understandable designs for complex systems problems.
Savaal: Scalable Concept-Driven Question Generation to Enhance Human Learning
Feb 18, 2025
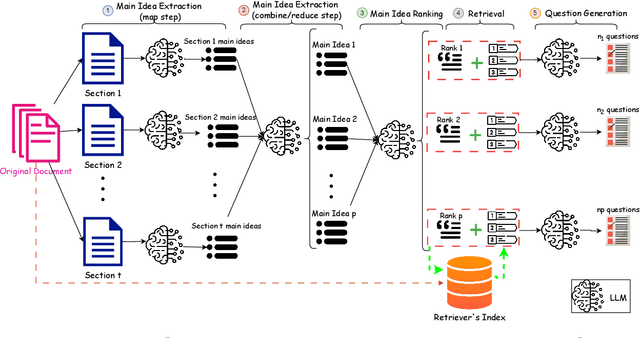


Assessing and enhancing human learning through question-answering is vital, yet automating this process remains challenging. While large language models (LLMs) excel at summarization and query responses, their ability to generate meaningful questions for learners is underexplored. We propose Savaal, a scalable question-generation system with three objectives: (i) scalability, enabling question generation from hundreds of pages of text (ii) depth of understanding, producing questions beyond factual recall to test conceptual reasoning, and (iii) domain-independence, automatically generating questions across diverse knowledge areas. Instead of providing an LLM with large documents as context, Savaal improves results with a three-stage processing pipeline. Our evaluation with 76 human experts on 71 papers and PhD dissertations shows that Savaal generates questions that better test depth of understanding by 6.5X for dissertations and 1.5X for papers compared to a direct-prompting LLM baseline. Notably, as document length increases, Savaal's advantages in higher question quality and lower cost become more pronounced.
DriveTrack: A Benchmark for Long-Range Point Tracking in Real-World Videos
Dec 15, 2023
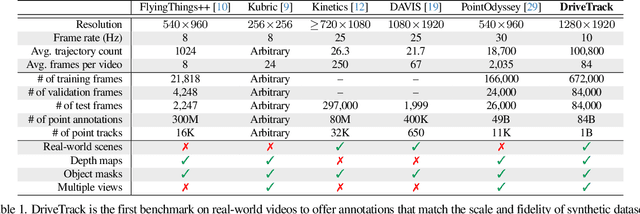

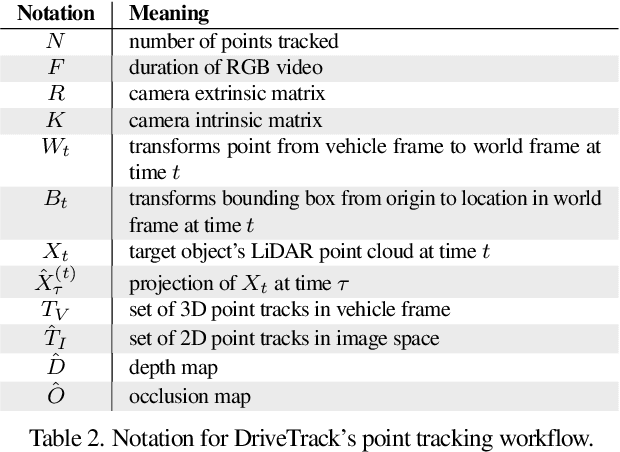
This paper presents DriveTrack, a new benchmark and data generation framework for long-range keypoint tracking in real-world videos. DriveTrack is motivated by the observation that the accuracy of state-of-the-art trackers depends strongly on visual attributes around the selected keypoints, such as texture and lighting. The problem is that these artifacts are especially pronounced in real-world videos, but these trackers are unable to train on such scenes due to a dearth of annotations. DriveTrack bridges this gap by building a framework to automatically annotate point tracks on autonomous driving datasets. We release a dataset consisting of 1 billion point tracks across 24 hours of video, which is seven orders of magnitude greater than prior real-world benchmarks and on par with the scale of synthetic benchmarks. DriveTrack unlocks new use cases for point tracking in real-world videos. First, we show that fine-tuning keypoint trackers on DriveTrack improves accuracy on real-world scenes by up to 7%. Second, we analyze the sensitivity of trackers to visual artifacts in real scenes and motivate the idea of running assistive keypoint selectors alongside trackers.
Updating Street Maps using Changes Detected in Satellite Imagery
Oct 13, 2021
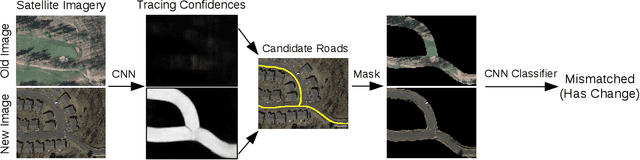


Accurately maintaining digital street maps is labor-intensive. To address this challenge, much work has studied automatically processing geospatial data sources such as GPS trajectories and satellite images to reduce the cost of maintaining digital maps. An end-to-end map update system would first process geospatial data sources to extract insights, and second leverage those insights to update and improve the map. However, prior work largely focuses on the first step of this pipeline: these map extraction methods infer road networks from scratch given geospatial data sources (in effect creating entirely new maps), but do not address the second step of leveraging this extracted information to update the existing digital map data. In this paper, we first explain why current map extraction techniques yield low accuracy when extended to update existing maps. We then propose a novel method that leverages the progression of satellite imagery over time to substantially improve accuracy. Our approach first compares satellite images captured at different times to identify portions of the physical road network that have visibly changed, and then updates the existing map accordingly. We show that our change-based approach reduces map update error rates four-fold.
Throughput-Fairness Tradeoffs in Mobility Platforms
May 25, 2021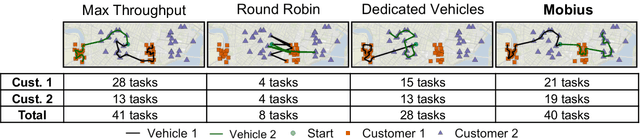
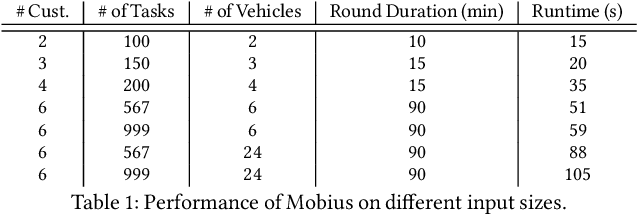
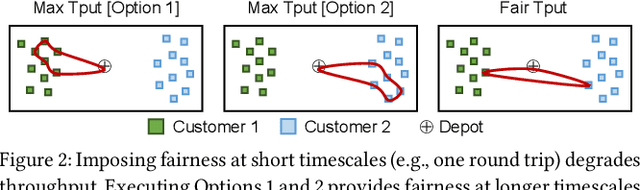
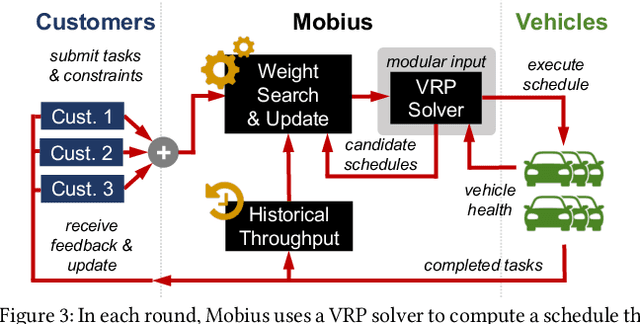
This paper studies the problem of allocating tasks from different customers to vehicles in mobility platforms, which are used for applications like food and package delivery, ridesharing, and mobile sensing. A mobility platform should allocate tasks to vehicles and schedule them in order to optimize both throughput and fairness across customers. However, existing approaches to scheduling tasks in mobility platforms ignore fairness. We introduce Mobius, a system that uses guided optimization to achieve both high throughput and fairness across customers. Mobius supports spatiotemporally diverse and dynamic customer demands. It provides a principled method to navigate inherent tradeoffs between fairness and throughput caused by shared mobility. Our evaluation demonstrates these properties, along with the versatility and scalability of Mobius, using traces gathered from ridesharing and aerial sensing applications. Our ridesharing case study shows that Mobius can schedule more than 16,000 tasks across 40 customers and 200 vehicles in an online manner.
TagMe: GPS-Assisted Automatic Object Annotation in Videos
Mar 24, 2021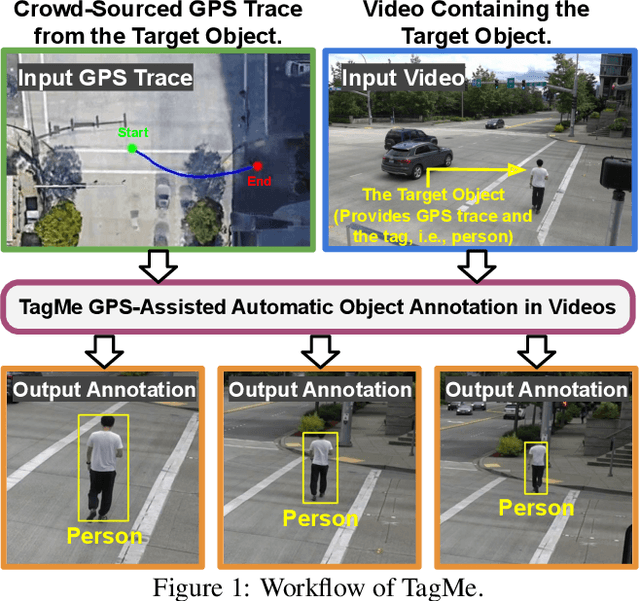

Training high-accuracy object detection models requires large and diverse annotated datasets. However, creating these data-sets is time-consuming and expensive since it relies on human annotators. We design, implement, and evaluate TagMe, a new approach for automatic object annotation in videos that uses GPS data. When the GPS trace of an object is available, TagMe matches the object's motion from GPS trace and the pixels' motions in the video to find the pixels belonging to the object in the video and creates the bounding box annotations of the object. TagMe works using passive data collection and can continuously generate new object annotations from outdoor video streams without any human annotators. We evaluate TagMe on a dataset of 100 video clips. We show TagMe can produce high-quality object annotations in a fully-automatic and low-cost way. Compared with the traditional human-in-the-loop solution, TagMe can produce the same amount of annotations at a much lower cost, e.g., up to 110x.
Sat2Graph: Road Graph Extraction through Graph-Tensor Encoding
Jul 19, 2020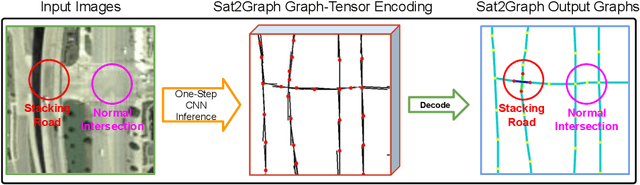
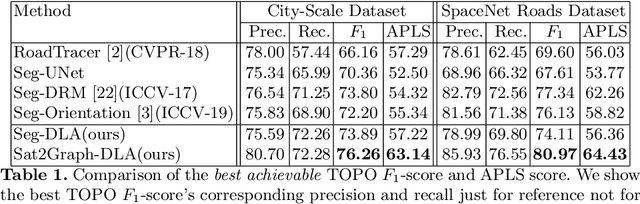
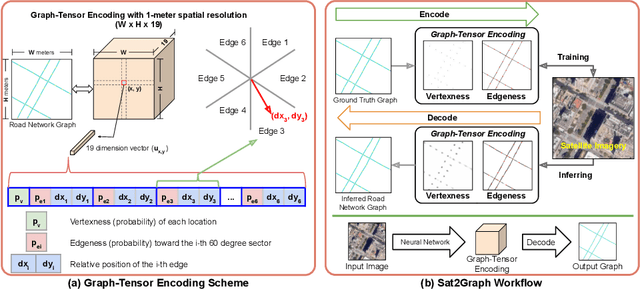

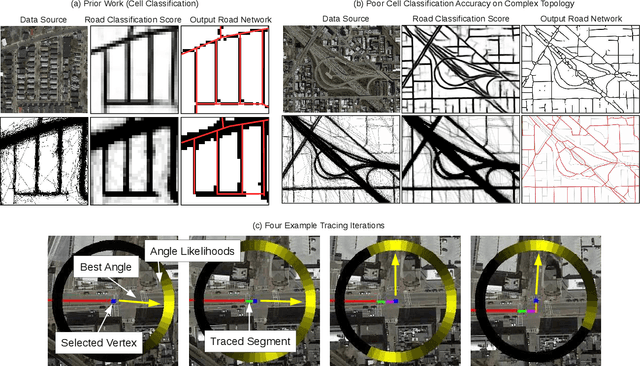
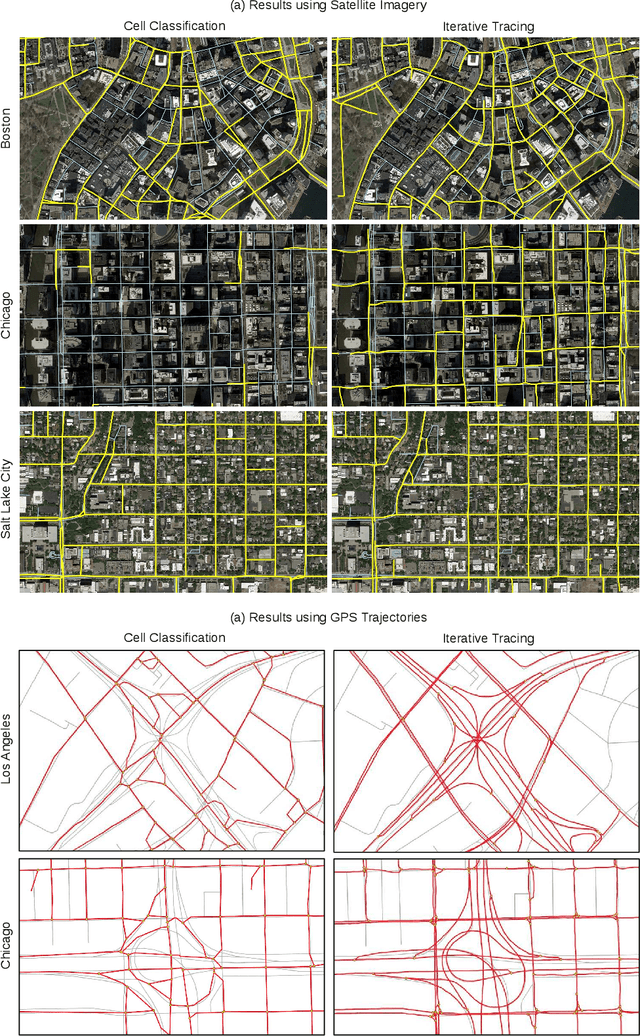
Inferring road graphs from satellite imagery is a challenging computer vision task. Prior solutions fall into two categories: (1) pixel-wise segmentation-based approaches, which predict whether each pixel is on a road, and (2) graph-based approaches, which predict the road graph iteratively. We find that these two approaches have complementary strengths while suffering from their own inherent limitations. In this paper, we propose a new method, Sat2Graph, which combines the advantages of the two prior categories into a unified framework. The key idea in Sat2Graph is a novel encoding scheme, graph-tensor encoding (GTE), which encodes the road graph into a tensor representation. GTE makes it possible to train a simple, non-recurrent, supervised model to predict a rich set of features that capture the graph structure directly from an image. We evaluate Sat2Graph using two large datasets. We find that Sat2Graph surpasses prior methods on two widely used metrics, TOPO and APLS. Furthermore, whereas prior work only infers planar road graphs, our approach is capable of inferring stacked roads (e.g., overpasses), and does so robustly.
RoadTagger: Robust Road Attribute Inference with Graph Neural Networks
Dec 28, 2019
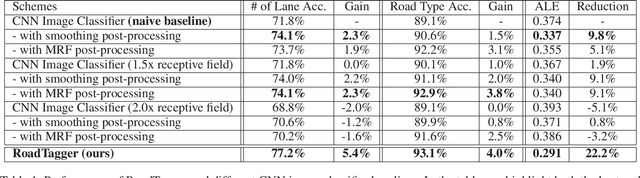
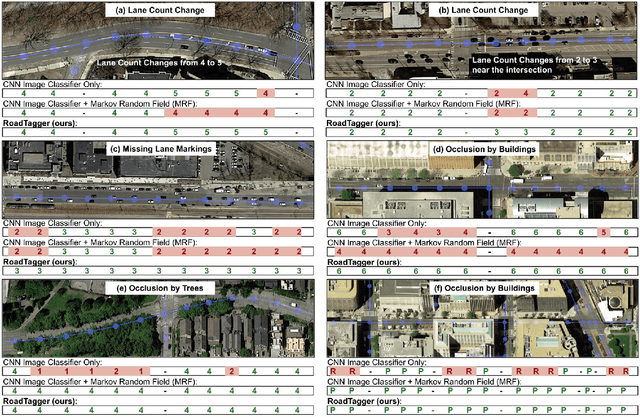
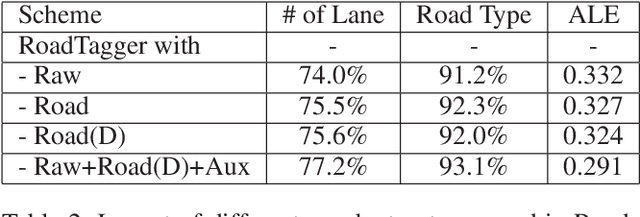
Inferring road attributes such as lane count and road type from satellite imagery is challenging. Often, due to the occlusion in satellite imagery and the spatial correlation of road attributes, a road attribute at one position on a road may only be apparent when considering far-away segments of the road. Thus, to robustly infer road attributes, the model must integrate scattered information and capture the spatial correlation of features along roads. Existing solutions that rely on image classifiers fail to capture this correlation, resulting in poor accuracy. We find this failure is caused by a fundamental limitation -- the limited effective receptive field of image classifiers. To overcome this limitation, we propose RoadTagger, an end-to-end architecture which combines both Convolutional Neural Networks (CNNs) and Graph Neural Networks (GNNs) to infer road attributes. The usage of graph neural networks allows information propagation on the road network graph and eliminates the receptive field limitation of image classifiers. We evaluate RoadTagger on both a large real-world dataset covering 688 km^2 area in 20 U.S. cities and a synthesized micro-dataset. In the evaluation, RoadTagger improves inference accuracy over the CNN image classifier based approaches. RoadTagger also demonstrates strong robustness against different disruptions in the satellite imagery and the ability to learn complicated inductive rules for aggregating scattered information along the road network.
Inferring and Improving Street Maps with Data-Driven Automation
Nov 06, 2019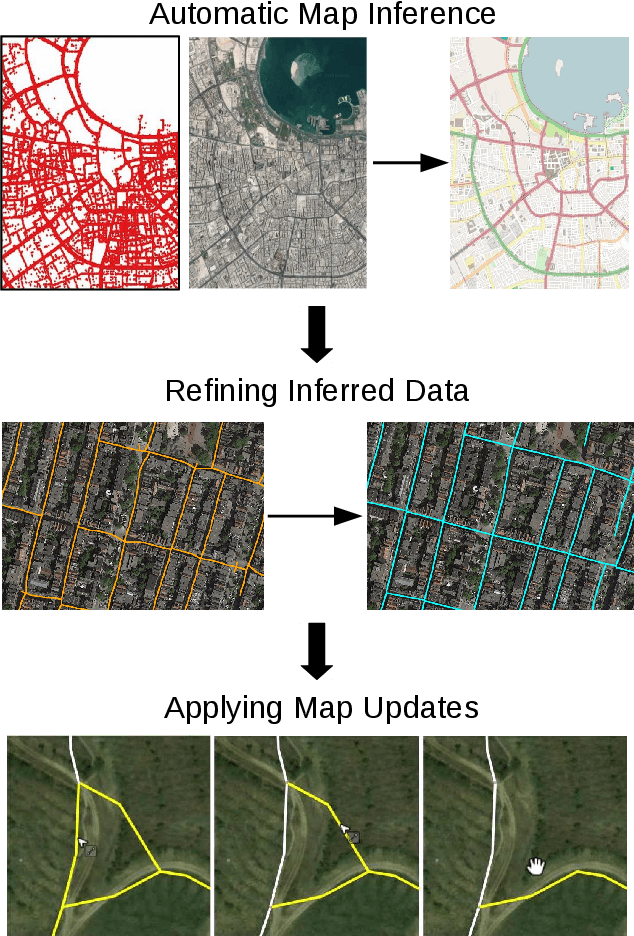
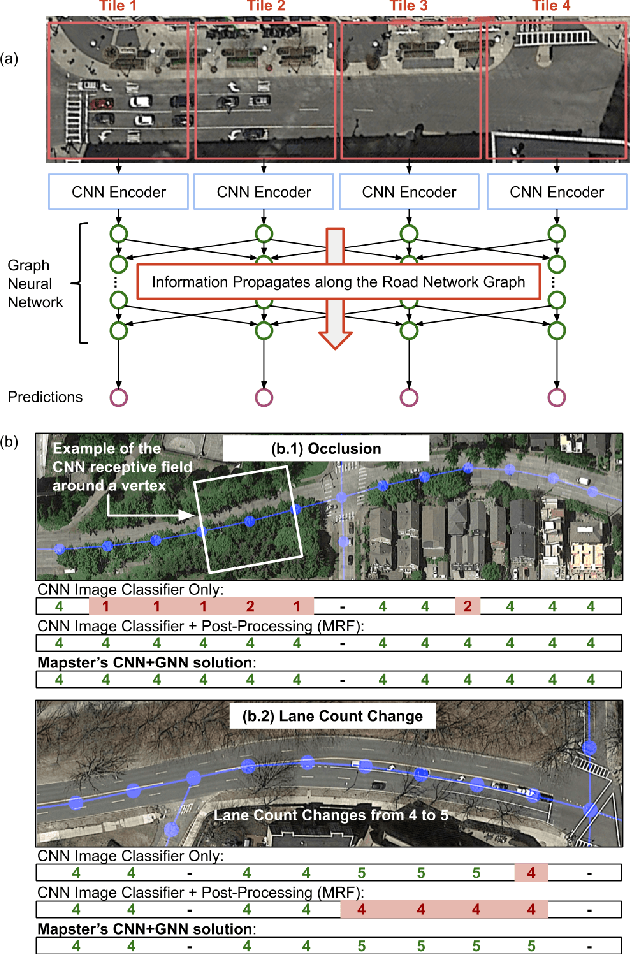
Street maps are a crucial data source that help to inform a wide range of decisions, from navigating a city to disaster relief and urban planning. However, in many parts of the world, street maps are incomplete or lag behind new construction. Editing maps today involves a tedious process of manually tracing and annotating roads, buildings, and other map features. Over the past decade, many automatic map inference systems have been proposed to automatically extract street map data from satellite imagery, aerial imagery, and GPS trajectory datasets. However, automatic map inference has failed to gain traction in practice due to two key limitations: high error rates (low precision), which manifest in noisy inference outputs, and a lack of end-to-end system design to leverage inferred data to update existing street maps. At MIT and QCRI, we have developed a number of algorithms and approaches to address these challenges, which we combined into a new system we call Mapster. Mapster is a human-in-the-loop street map editing system that incorporates three components to robustly accelerate the mapping process over traditional tools and workflows: high-precision automatic map inference, data refinement, and machine-assisted map editing. Through an evaluation on a large-scale dataset including satellite imagery, GPS trajectories, and ground-truth map data in forty cities, we show that Mapster makes automation practical for map editing, and enables the curation of map datasets that are more complete and up-to-date at less cost.