 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTagMe: GPS-Assisted Automatic Object Annotation in Videos
Paper and Code
Mar 24, 2021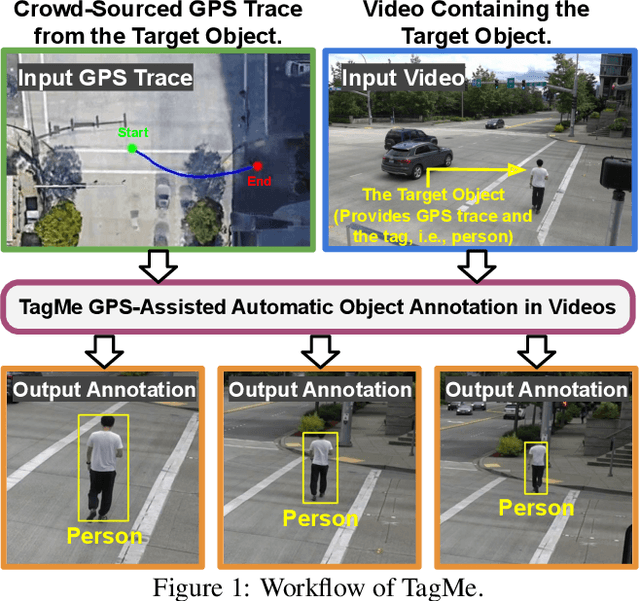

Training high-accuracy object detection models requires large and diverse annotated datasets. However, creating these data-sets is time-consuming and expensive since it relies on human annotators. We design, implement, and evaluate TagMe, a new approach for automatic object annotation in videos that uses GPS data. When the GPS trace of an object is available, TagMe matches the object's motion from GPS trace and the pixels' motions in the video to find the pixels belonging to the object in the video and creates the bounding box annotations of the object. TagMe works using passive data collection and can continuously generate new object annotations from outdoor video streams without any human annotators. We evaluate TagMe on a dataset of 100 video clips. We show TagMe can produce high-quality object annotations in a fully-automatic and low-cost way. Compared with the traditional human-in-the-loop solution, TagMe can produce the same amount of annotations at a much lower cost, e.g., up to 110x.