 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Multi-Object Tracking with Cross-Input Consistency
Nov 10, 2021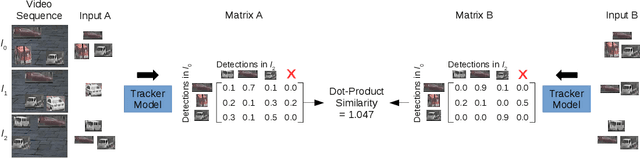
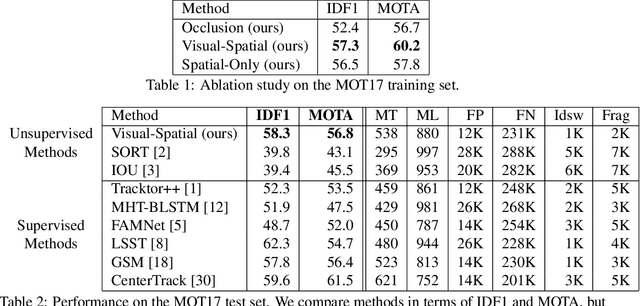
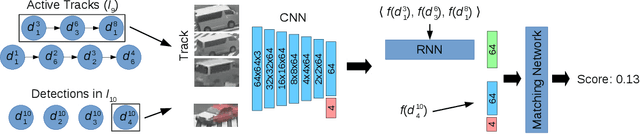
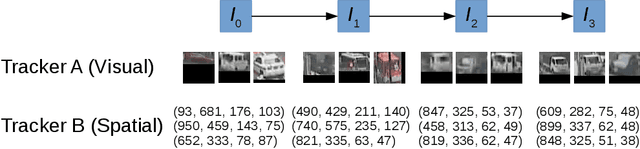
In this paper, we propose a self-supervised learning procedure for training a robust multi-object tracking (MOT) model given only unlabeled video. While several self-supervisory learning signals have been proposed in prior work on single-object tracking, such as color propagation and cycle-consistency, these signals cannot be directly applied for training RNN models, which are needed to achieve accurate MOT: they yield degenerate models that, for instance, always match new detections to tracks with the closest initial detections. We propose a novel self-supervisory signal that we call cross-input consistency: we construct two distinct inputs for the same sequence of video, by hiding different information about the sequence in each input. We then compute tracks in that sequence by applying an RNN model independently on each input, and train the model to produce consistent tracks across the two inputs. We evaluate our unsupervised method on MOT17 and KITTI -- remarkably, we find that, despite training only on unlabeled video, our unsupervised approach outperforms four supervised methods published in the last 1--2 years, including Tracktor++, FAMNet, GSM, and mmMOT.
Updating Street Maps using Changes Detected in Satellite Imagery
Oct 13, 2021
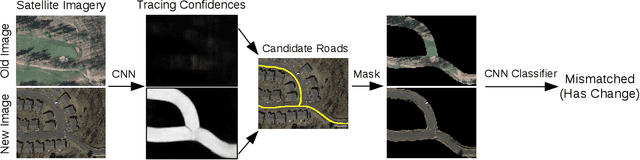


Accurately maintaining digital street maps is labor-intensive. To address this challenge, much work has studied automatically processing geospatial data sources such as GPS trajectories and satellite images to reduce the cost of maintaining digital maps. An end-to-end map update system would first process geospatial data sources to extract insights, and second leverage those insights to update and improve the map. However, prior work largely focuses on the first step of this pipeline: these map extraction methods infer road networks from scratch given geospatial data sources (in effect creating entirely new maps), but do not address the second step of leveraging this extracted information to update the existing digital map data. In this paper, we first explain why current map extraction techniques yield low accuracy when extended to update existing maps. We then propose a novel method that leverages the progression of satellite imagery over time to substantially improve accuracy. Our approach first compares satellite images captured at different times to identify portions of the physical road network that have visibly changed, and then updates the existing map accordingly. We show that our change-based approach reduces map update error rates four-fold.
TagMe: GPS-Assisted Automatic Object Annotation in Videos
Mar 24, 2021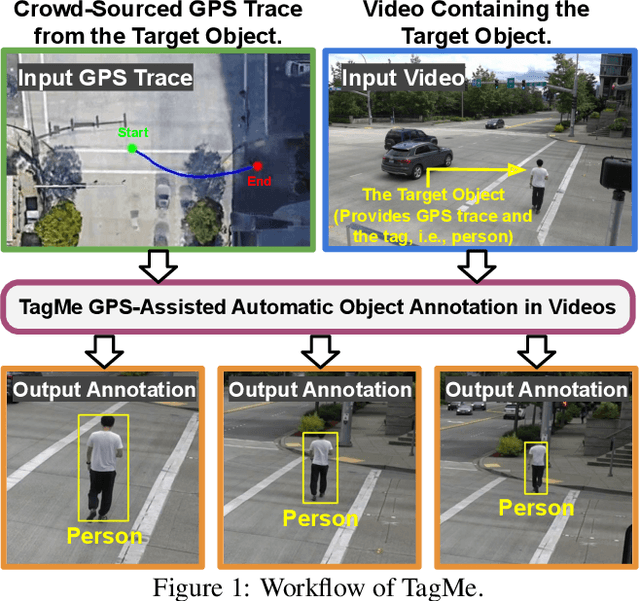
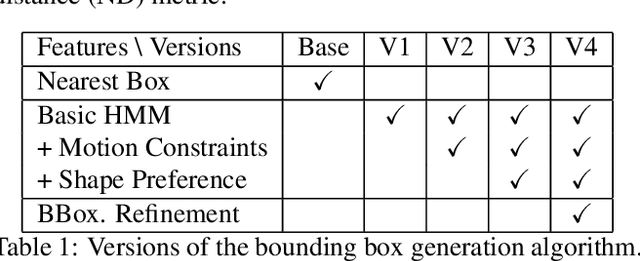

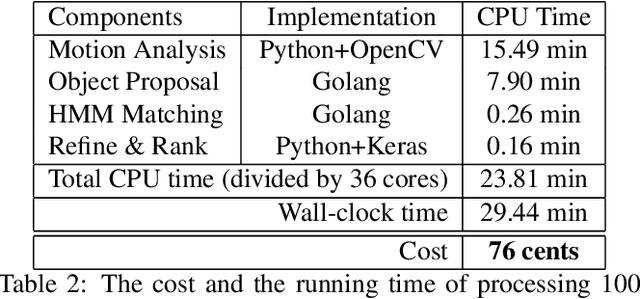
Training high-accuracy object detection models requires large and diverse annotated datasets. However, creating these data-sets is time-consuming and expensive since it relies on human annotators. We design, implement, and evaluate TagMe, a new approach for automatic object annotation in videos that uses GPS data. When the GPS trace of an object is available, TagMe matches the object's motion from GPS trace and the pixels' motions in the video to find the pixels belonging to the object in the video and creates the bounding box annotations of the object. TagMe works using passive data collection and can continuously generate new object annotations from outdoor video streams without any human annotators. We evaluate TagMe on a dataset of 100 video clips. We show TagMe can produce high-quality object annotations in a fully-automatic and low-cost way. Compared with the traditional human-in-the-loop solution, TagMe can produce the same amount of annotations at a much lower cost, e.g., up to 110x.
Sat2Graph: Road Graph Extraction through Graph-Tensor Encoding
Jul 19, 2020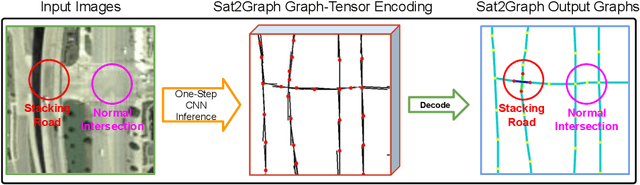
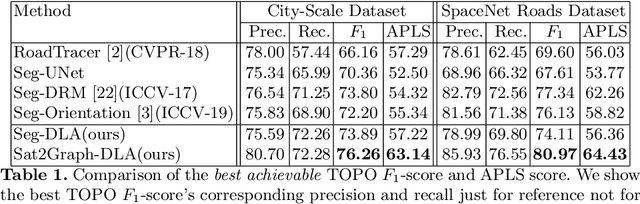
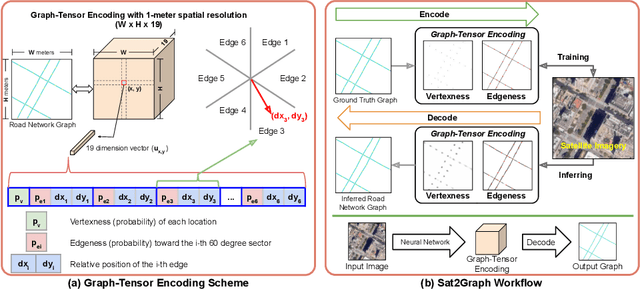

Inferring road graphs from satellite imagery is a challenging computer vision task. Prior solutions fall into two categories: (1) pixel-wise segmentation-based approaches, which predict whether each pixel is on a road, and (2) graph-based approaches, which predict the road graph iteratively. We find that these two approaches have complementary strengths while suffering from their own inherent limitations. In this paper, we propose a new method, Sat2Graph, which combines the advantages of the two prior categories into a unified framework. The key idea in Sat2Graph is a novel encoding scheme, graph-tensor encoding (GTE), which encodes the road graph into a tensor representation. GTE makes it possible to train a simple, non-recurrent, supervised model to predict a rich set of features that capture the graph structure directly from an image. We evaluate Sat2Graph using two large datasets. We find that Sat2Graph surpasses prior methods on two widely used metrics, TOPO and APLS. Furthermore, whereas prior work only infers planar road graphs, our approach is capable of inferring stacked roads (e.g., overpasses), and does so robustly.
RoadTagger: Robust Road Attribute Inference with Graph Neural Networks
Dec 28, 2019
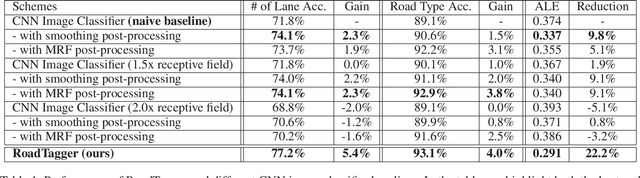
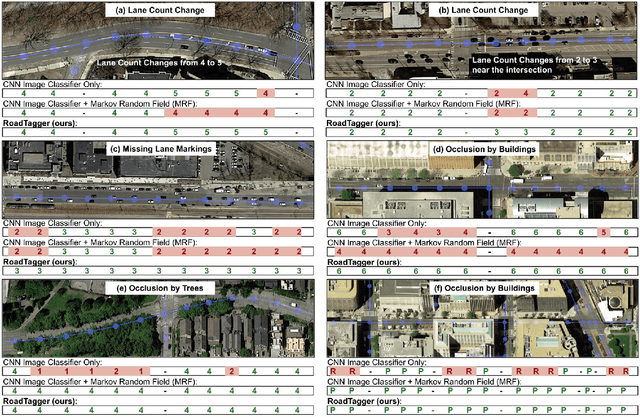
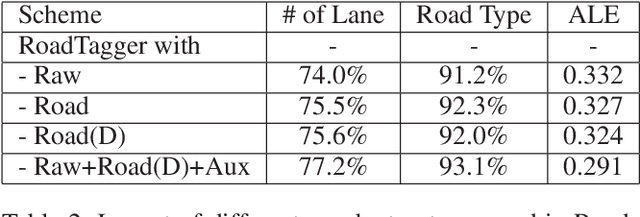
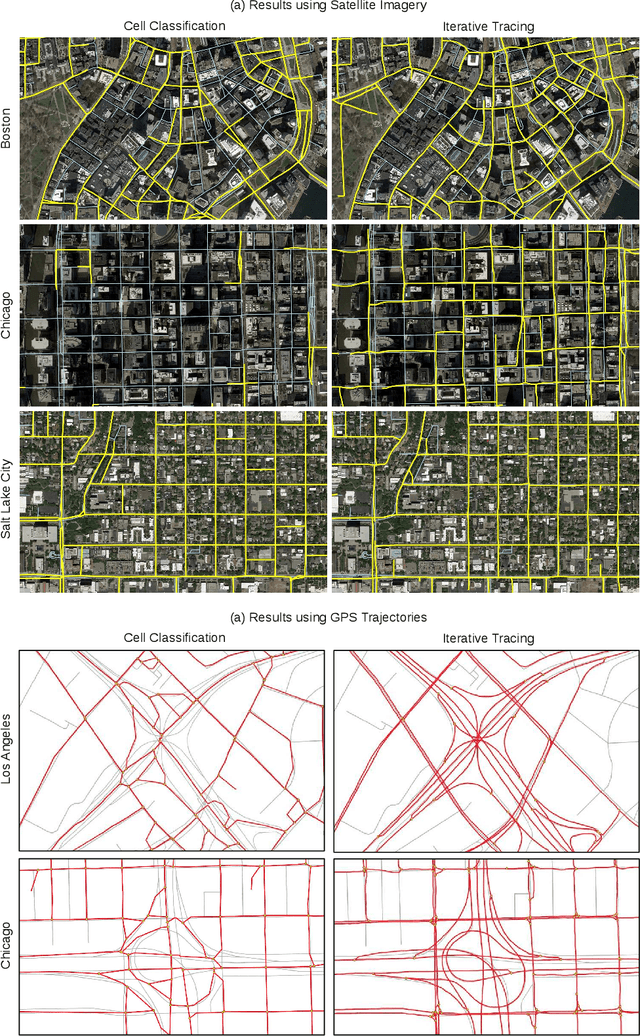
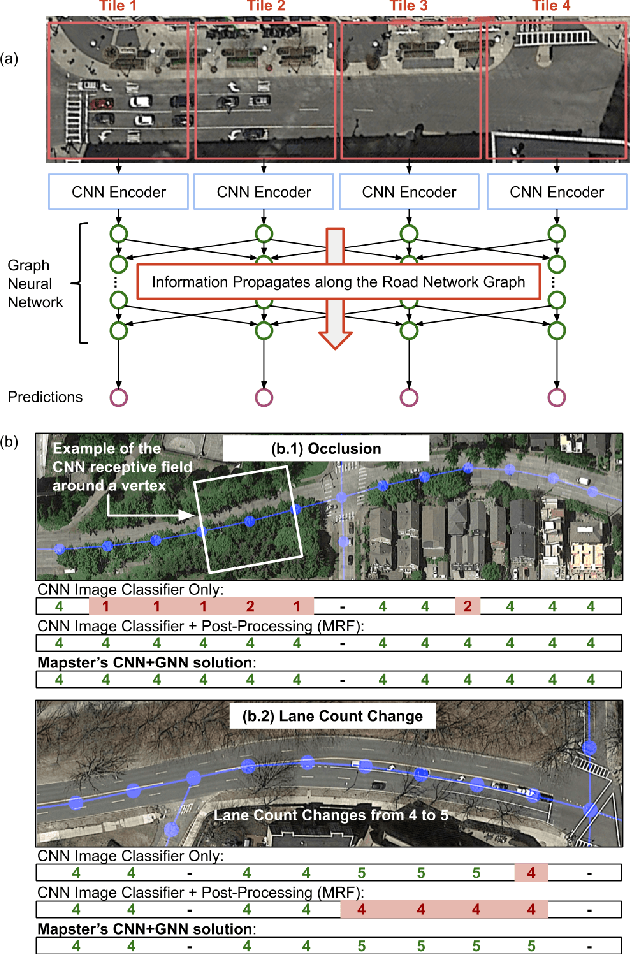
Inferring road attributes such as lane count and road type from satellite imagery is challenging. Often, due to the occlusion in satellite imagery and the spatial correlation of road attributes, a road attribute at one position on a road may only be apparent when considering far-away segments of the road. Thus, to robustly infer road attributes, the model must integrate scattered information and capture the spatial correlation of features along roads. Existing solutions that rely on image classifiers fail to capture this correlation, resulting in poor accuracy. We find this failure is caused by a fundamental limitation -- the limited effective receptive field of image classifiers. To overcome this limitation, we propose RoadTagger, an end-to-end architecture which combines both Convolutional Neural Networks (CNNs) and Graph Neural Networks (GNNs) to infer road attributes. The usage of graph neural networks allows information propagation on the road network graph and eliminates the receptive field limitation of image classifiers. We evaluate RoadTagger on both a large real-world dataset covering 688 km^2 area in 20 U.S. cities and a synthesized micro-dataset. In the evaluation, RoadTagger improves inference accuracy over the CNN image classifier based approaches. RoadTagger also demonstrates strong robustness against different disruptions in the satellite imagery and the ability to learn complicated inductive rules for aggregating scattered information along the road network.
Inferring and Improving Street Maps with Data-Driven Automation
Nov 06, 2019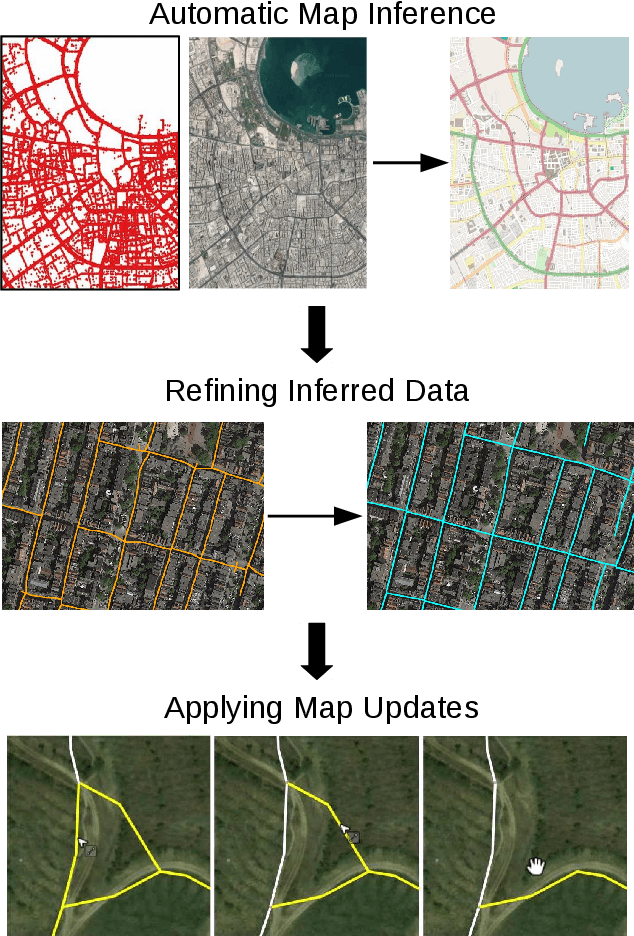
Street maps are a crucial data source that help to inform a wide range of decisions, from navigating a city to disaster relief and urban planning. However, in many parts of the world, street maps are incomplete or lag behind new construction. Editing maps today involves a tedious process of manually tracing and annotating roads, buildings, and other map features. Over the past decade, many automatic map inference systems have been proposed to automatically extract street map data from satellite imagery, aerial imagery, and GPS trajectory datasets. However, automatic map inference has failed to gain traction in practice due to two key limitations: high error rates (low precision), which manifest in noisy inference outputs, and a lack of end-to-end system design to leverage inferred data to update existing street maps. At MIT and QCRI, we have developed a number of algorithms and approaches to address these challenges, which we combined into a new system we call Mapster. Mapster is a human-in-the-loop street map editing system that incorporates three components to robustly accelerate the mapping process over traditional tools and workflows: high-precision automatic map inference, data refinement, and machine-assisted map editing. Through an evaluation on a large-scale dataset including satellite imagery, GPS trajectories, and ground-truth map data in forty cities, we show that Mapster makes automation practical for map editing, and enables the curation of map datasets that are more complete and up-to-date at less cost.
Machine-Assisted Map Editing
Jun 17, 2019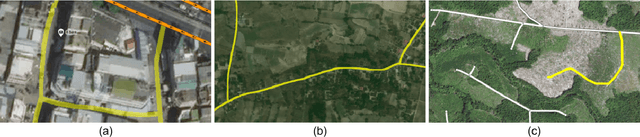
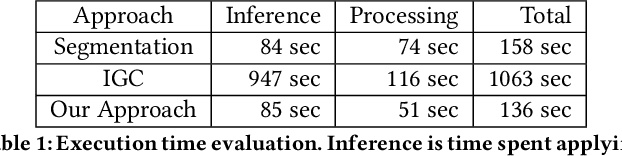


Mapping road networks today is labor-intensive. As a result, road maps have poor coverage outside urban centers in many countries. Systems to automatically infer road network graphs from aerial imagery and GPS trajectories have been proposed to improve coverage of road maps. However, because of high error rates, these systems have not been adopted by mapping communities. We propose machine-assisted map editing, where automatic map inference is integrated into existing, human-centric map editing workflows. To realize this, we build Machine-Assisted iD (MAiD), where we extend the web-based OpenStreetMap editor, iD, with machine-assistance functionality. We complement MAiD with a novel approach for inferring road topology from aerial imagery that combines the speed of prior segmentation approaches with the accuracy of prior iterative graph construction methods. We design MAiD to tackle the addition of major, arterial roads in regions where existing maps have poor coverage, and the incremental improvement of coverage in regions where major roads are already mapped. We conduct two user studies and find that, when participants are given a fixed time to map roads, they are able to add as much as 3.5x more roads with MAiD.
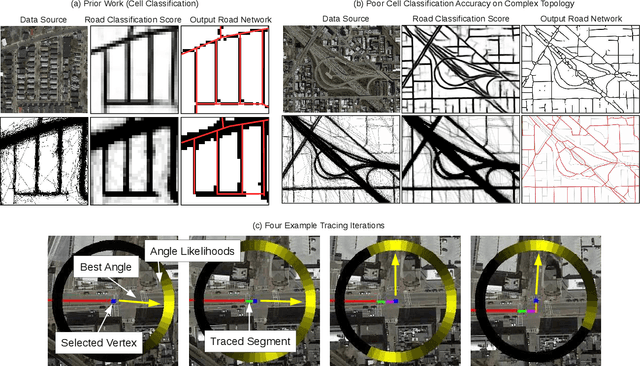
RoadTracer: Automatic Extraction of Road Networks from Aerial Images
Apr 26, 2018



Mapping road networks is currently both expensive and labor-intensive. High-resolution aerial imagery provides a promising avenue to automatically infer a road network. Prior work uses convolutional neural networks (CNNs) to detect which pixels belong to a road (segmentation), and then uses complex post-processing heuristics to infer graph connectivity. We show that these segmentation methods have high error rates because noisy CNN outputs are difficult to correct. We propose RoadTracer, a new method to automatically construct accurate road network maps from aerial images. RoadTracer uses an iterative search process guided by a CNN-based decision function to derive the road network graph directly from the output of the CNN. We compare our approach with a segmentation method on fifteen cities, and find that at a 5% error rate, RoadTracer correctly captures 45% more junctions across these cities.