 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Augmentation: Leveraging Inter-Instance Relation in Self-Supervised Representation Learning
Oct 25, 2025This paper introduces a novel approach that integrates graph theory into self-supervised representation learning. Traditional methods focus on intra-instance variations generated by applying augmentations. However, they often overlook important inter-instance relationships. While our method retains the intra-instance property, it further captures inter-instance relationships by constructing k-nearest neighbor (KNN) graphs for both teacher and student streams during pretraining. In these graphs, nodes represent samples along with their latent representations. Edges encode the similarity between instances. Following pretraining, a representation refinement phase is performed. In this phase, Graph Neural Networks (GNNs) propagate messages not only among immediate neighbors but also across multiple hops, thereby enabling broader contextual integration. Experimental results on CIFAR-10, ImageNet-100, and ImageNet-1K demonstrate accuracy improvements of 7.3%, 3.2%, and 1.0%, respectively, over state-of-the-art methods. These results highlight the effectiveness of the proposed graph based mechanism. The code is publicly available at https://github.com/alijavidani/SSL-GraphNNCLR.
* Accepted in IEEE Signal Processing Letters, 2025
VeriFact: Verifying Facts in LLM-Generated Clinical Text with Electronic Health Records
Jan 28, 2025Methods to ensure factual accuracy of text generated by large language models (LLM) in clinical medicine are lacking. VeriFact is an artificial intelligence system that combines retrieval-augmented generation and LLM-as-a-Judge to verify whether LLM-generated text is factually supported by a patient's medical history based on their electronic health record (EHR). To evaluate this system, we introduce VeriFact-BHC, a new dataset that decomposes Brief Hospital Course narratives from discharge summaries into a set of simple statements with clinician annotations for whether each statement is supported by the patient's EHR clinical notes. Whereas highest agreement between clinicians was 88.5%, VeriFact achieves up to 92.7% agreement when compared to a denoised and adjudicated average human clinican ground truth, suggesting that VeriFact exceeds the average clinician's ability to fact-check text against a patient's medical record. VeriFact may accelerate the development of LLM-based EHR applications by removing current evaluation bottlenecks.
LG-Self: Local-Global Self-Supervised Visual Representation Learning
Nov 07, 2023Self-supervised representation learning methods mainly focus on image-level instance discrimination. This study explores the potential benefits of incorporating patch-level discrimination into existing methods to enhance the quality of learned representations by simultaneously looking at local and global visual features. Towards this idea, we present a straightforward yet effective patch-matching algorithm that can find the corresponding patches across the augmented views of an image. The augmented views are subsequently fed into a self-supervised learning framework employing Vision Transformer (ViT) as its backbone. The result is the generation of both image-level and patch-level representations. Leveraging the proposed patch-matching algorithm, the model minimizes the representation distance between not only the CLS tokens but also the corresponding patches. As a result, the model gains a more comprehensive understanding of both the entirety of the image as well as its finer details. We pretrain the proposed method on small, medium, and large-scale datasets. It is shown that our approach could outperform state-of-the-art image-level representation learning methods on both image classification and downstream tasks. Keywords: Self-Supervised Learning; Visual Representations; Local-Global Representation Learning; Patch-Wise Representation Learning; Vision Transformer (ViT)
Designing a Sequential Recommendation System for Heterogeneous Interactions Using Transformers
Apr 30, 2022
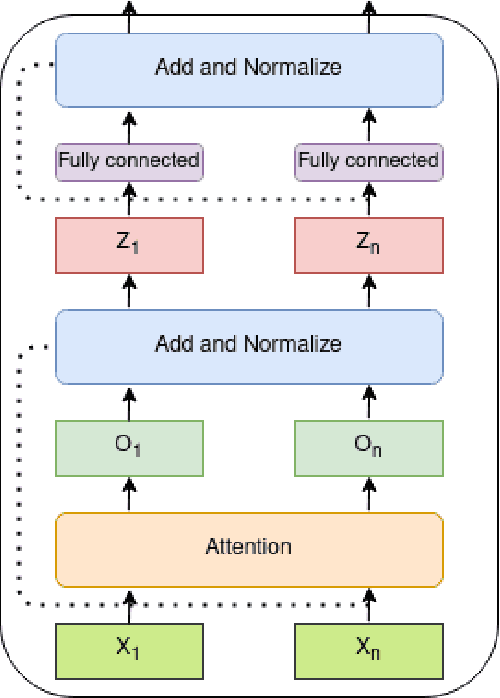


While many production-ready and robust algorithms are available for the task of recommendation systems, many of these systems do not take the order of user's consumption into account. The order of consumption can be very useful and matters in many scenarios. One such scenario is an educational content recommendation, where users generally follow a progressive path towards more advanced courses. Researchers have used RNNs to build sequential recommendation systems and other models that deal with sequences. Sequential Recommendation systems try to predict the next event for the user by reading their history. With the massive success of Transformers in Natural Language Processing and their usage of Attention Mechanism to better deal with sequences, there have been attempts to use this family of models as a base for a new generation of sequential recommendation systems. In this work, by converting each user's interactions with items into a series of events and basing our architecture on Transformers, we try to enable the use of such a model that takes different types of events into account. Furthermore, by recognizing that some events have to occur before some other types of events take place, we try to modify the architecture to reflect this dependency relationship and enhance the model's performance.
Updating Street Maps using Changes Detected in Satellite Imagery
Oct 13, 2021
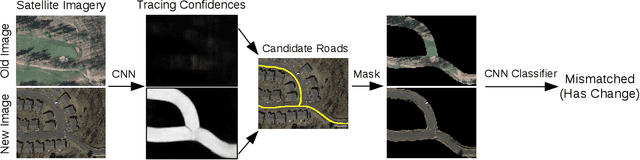


Accurately maintaining digital street maps is labor-intensive. To address this challenge, much work has studied automatically processing geospatial data sources such as GPS trajectories and satellite images to reduce the cost of maintaining digital maps. An end-to-end map update system would first process geospatial data sources to extract insights, and second leverage those insights to update and improve the map. However, prior work largely focuses on the first step of this pipeline: these map extraction methods infer road networks from scratch given geospatial data sources (in effect creating entirely new maps), but do not address the second step of leveraging this extracted information to update the existing digital map data. In this paper, we first explain why current map extraction techniques yield low accuracy when extended to update existing maps. We then propose a novel method that leverages the progression of satellite imagery over time to substantially improve accuracy. Our approach first compares satellite images captured at different times to identify portions of the physical road network that have visibly changed, and then updates the existing map accordingly. We show that our change-based approach reduces map update error rates four-fold.
An Improved Hybrid Recommender System: Integrating Document Context-Based and Behavior-Based Methods
Sep 12, 2021
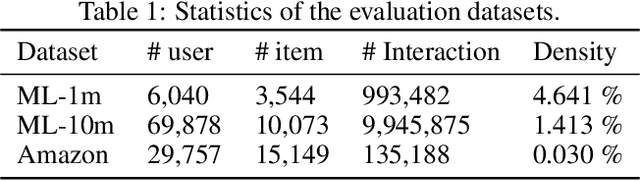
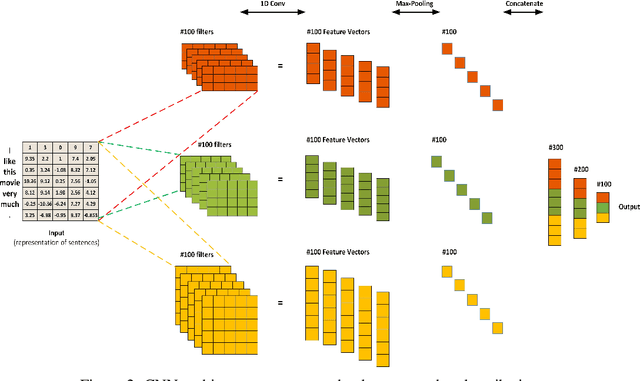
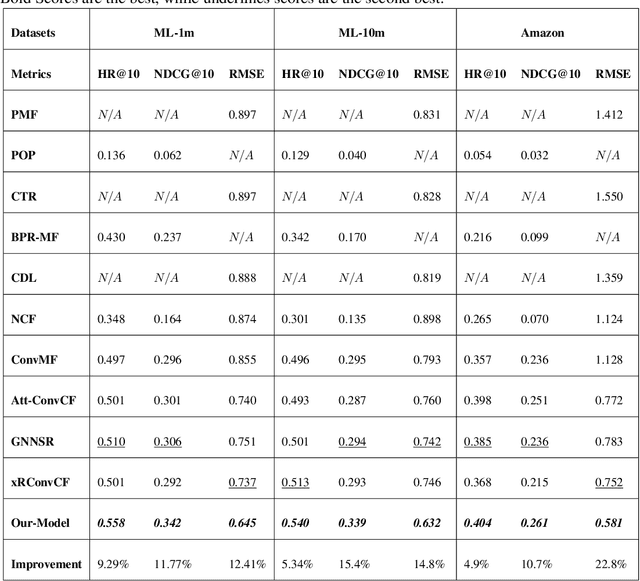
One of the main challenges in recommender systems is data sparsity which leads to high variance. Several attempts have been made to improve the bias-variance trade-off using auxiliary information. In particular, document modeling-based methods have improved the model's accuracy by using textual data such as reviews, abstracts, and storylines when the user-to-item rating matrix is sparse. However, such models are insufficient to learn optimal representation for users and items. User-based and item-based collaborative filtering, owing to their efficiency and interpretability, have been long used for building recommender systems. They create a profile for each user and item respectively as their historically interacted items and the users who interacted with the target item. This work combines these two approaches with document context-aware recommender systems by considering users' opinions on these items. Another advantage of our model is that it supports online personalization. If a user has new interactions, it needs to refresh the user and item history representation vectors instead of updating model parameters. The proposed algorithm is implemented and tested on three real-world datasets that demonstrate our model's effectiveness over the baseline methods.
RoadTagger: Robust Road Attribute Inference with Graph Neural Networks
Dec 28, 2019
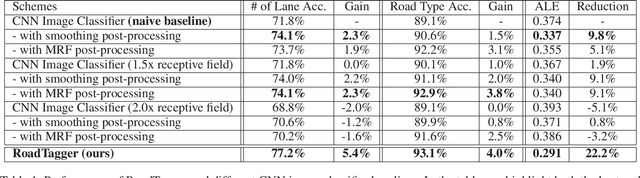
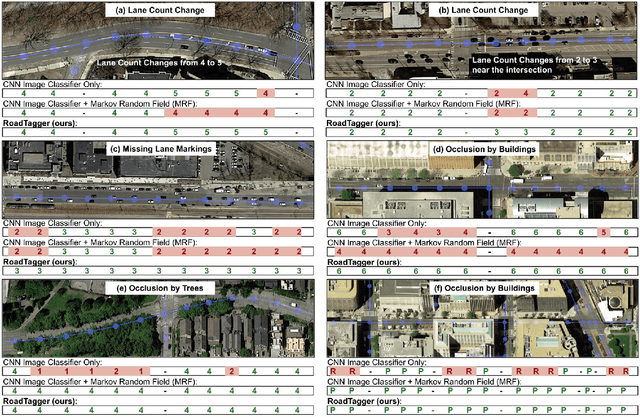
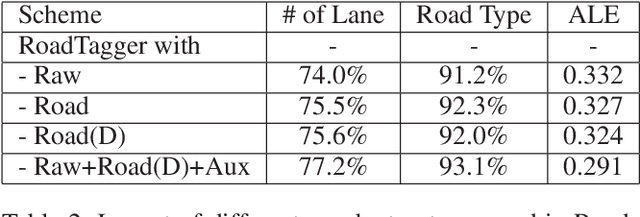
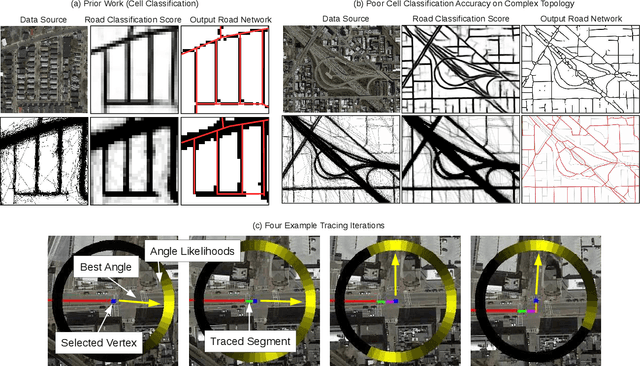
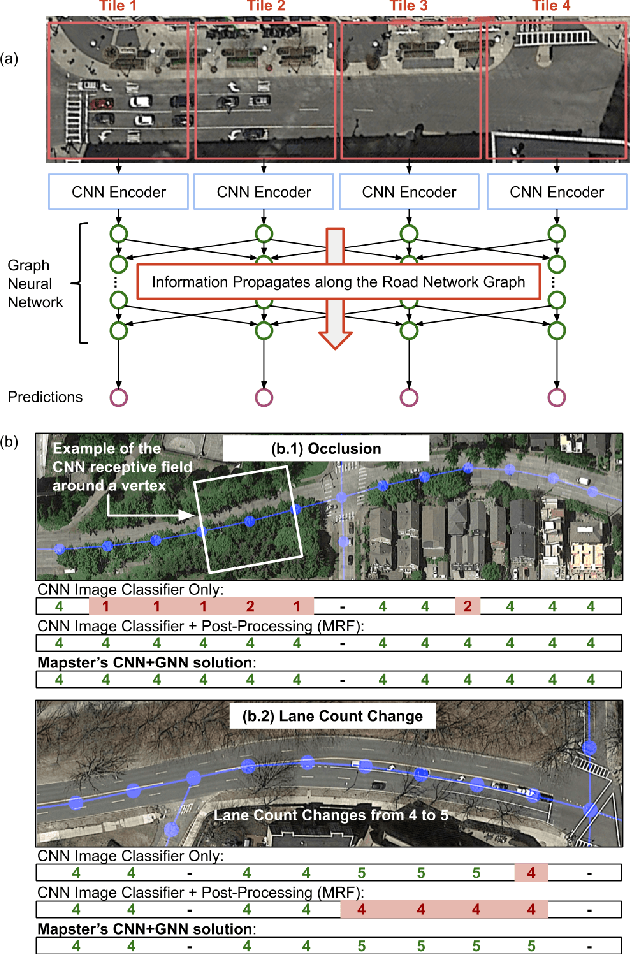
Inferring road attributes such as lane count and road type from satellite imagery is challenging. Often, due to the occlusion in satellite imagery and the spatial correlation of road attributes, a road attribute at one position on a road may only be apparent when considering far-away segments of the road. Thus, to robustly infer road attributes, the model must integrate scattered information and capture the spatial correlation of features along roads. Existing solutions that rely on image classifiers fail to capture this correlation, resulting in poor accuracy. We find this failure is caused by a fundamental limitation -- the limited effective receptive field of image classifiers. To overcome this limitation, we propose RoadTagger, an end-to-end architecture which combines both Convolutional Neural Networks (CNNs) and Graph Neural Networks (GNNs) to infer road attributes. The usage of graph neural networks allows information propagation on the road network graph and eliminates the receptive field limitation of image classifiers. We evaluate RoadTagger on both a large real-world dataset covering 688 km^2 area in 20 U.S. cities and a synthesized micro-dataset. In the evaluation, RoadTagger improves inference accuracy over the CNN image classifier based approaches. RoadTagger also demonstrates strong robustness against different disruptions in the satellite imagery and the ability to learn complicated inductive rules for aggregating scattered information along the road network.
Inferring and Improving Street Maps with Data-Driven Automation
Nov 06, 2019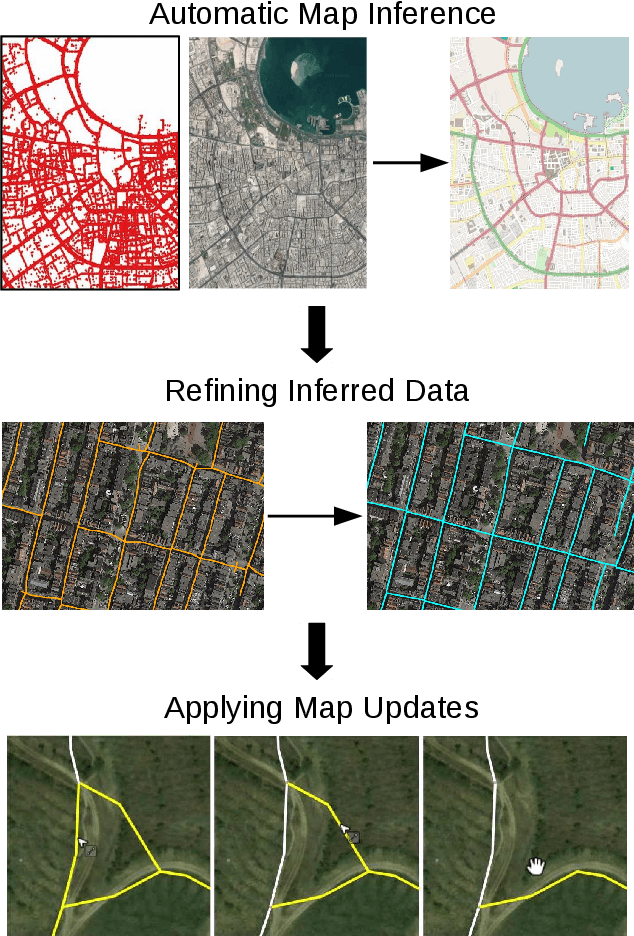
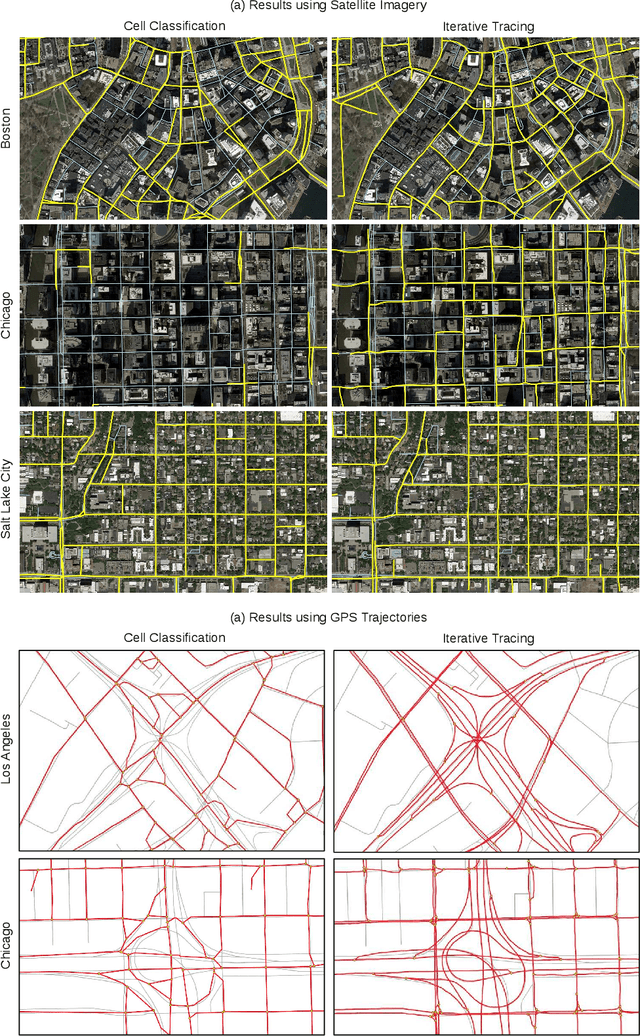
Street maps are a crucial data source that help to inform a wide range of decisions, from navigating a city to disaster relief and urban planning. However, in many parts of the world, street maps are incomplete or lag behind new construction. Editing maps today involves a tedious process of manually tracing and annotating roads, buildings, and other map features. Over the past decade, many automatic map inference systems have been proposed to automatically extract street map data from satellite imagery, aerial imagery, and GPS trajectory datasets. However, automatic map inference has failed to gain traction in practice due to two key limitations: high error rates (low precision), which manifest in noisy inference outputs, and a lack of end-to-end system design to leverage inferred data to update existing street maps. At MIT and QCRI, we have developed a number of algorithms and approaches to address these challenges, which we combined into a new system we call Mapster. Mapster is a human-in-the-loop street map editing system that incorporates three components to robustly accelerate the mapping process over traditional tools and workflows: high-precision automatic map inference, data refinement, and machine-assisted map editing. Through an evaluation on a large-scale dataset including satellite imagery, GPS trajectories, and ground-truth map data in forty cities, we show that Mapster makes automation practical for map editing, and enables the curation of map datasets that are more complete and up-to-date at less cost.
Assisted Excitation of Activations: A Learning Technique to Improve Object Detectors
Jun 12, 2019
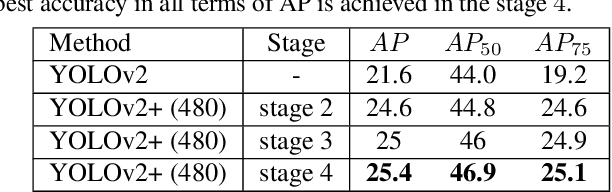


We present a simple and effective learning technique that significantly improves mAP of YOLO object detectors without compromising their speed. During network training, we carefully feed in localization information. We excite certain activations in order to help the network learn to better localize. In the later stages of training, we gradually reduce our assisted excitation to zero. We reached a new state-of-the-art in the speed-accuracy trade-off. Our technique improves the mAP of YOLOv2 by 3.8% and mAP of YOLOv3 by 2.2% on MSCOCO dataset.This technique is inspired from curriculum learning. It is simple and effective and it is applicable to most single-stage object detectors.
Multi-Representational Learning for Offline Signature Verification using Multi-Loss Snapshot Ensemble of CNNs
Mar 11, 2019
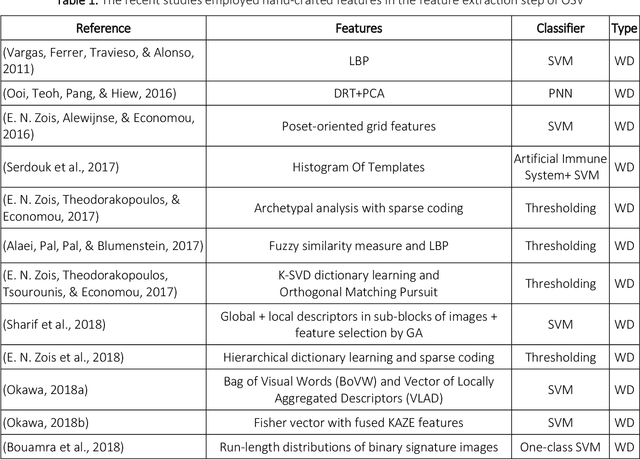
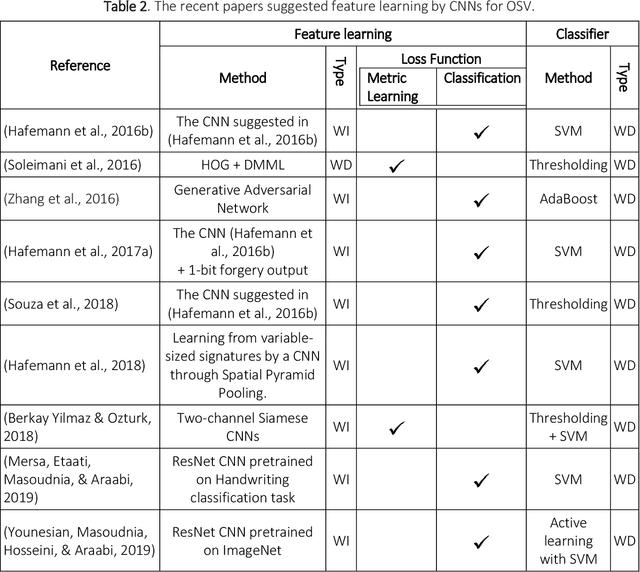
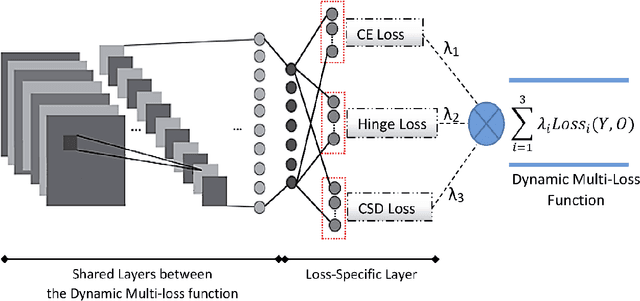
Offline Signature Verification (OSV) is a challenging pattern recognition task, especially in presence of skilled forgeries that are not available during training. This study aims to tackle its challenges and meet the substantial need for generalization for OSV by examining different loss functions for Convolutional Neural Network (CNN). We adopt our new approach to OSV by asking two questions: 1. which classification loss provides more generalization for feature learning in OSV? , and 2. How integration of different losses into a unified multi-loss function lead to an improved learning framework? These questions are studied based on analysis of three loss functions, including cross entropy, Cauchy-Schwarz divergence, and hinge loss. According to complementary features of these losses, we combine them into a dynamic multi-loss function and propose a novel ensemble framework for simultaneous use of them in CNN. Our proposed Multi-Loss Snapshot Ensemble (MLSE) consists of several sequential trials. In each trial, a dominant loss function is selected from the multi-loss set, and the remaining losses act as a regularizer. Different trials learn diverse representations for each input based on signature identification task. This multi-representation set is then employed for the verification task. An ensemble of SVMs is trained on these representations, and their decisions are finally combined according to the selection of most generalizable SVM for each user. We conducted two sets of experiments based on two different protocols of OSV, i.e., writer-dependent and writer-independent on three signature datasets: GPDS-Synthetic, MCYT, and UT-SIG. Based on the writer-dependent OSV protocol, we achieved substantial improvements over the best EERs in the literature. The results of the second set of experiments also confirmed the robustness to the arrival of new users enrolled in the OSV system.