 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-Based Digitization of Overlapping ECG Images with Open-Source Python Code
Jun 12, 2025



This paper addresses the persistent challenge of accurately digitizing paper-based electrocardiogram (ECG) recordings, with a particular focus on robustly handling single leads compromised by signal overlaps-a common yet under-addressed issue in existing methodologies. We propose a two-stage pipeline designed to overcome this limitation. The first stage employs a U-Net based segmentation network, trained on a dataset enriched with overlapping signals and fortified with custom data augmentations, to accurately isolate the primary ECG trace. The subsequent stage converts this refined binary mask into a time-series signal using established digitization techniques, enhanced by an adaptive grid detection module for improved versatility across different ECG formats and scales. Our experimental results demonstrate the efficacy of our approach. The U-Net architecture achieves an IoU of 0.87 for the fine-grained segmentation task. Crucially, our proposed digitization method yields superior performance compared to a well-established baseline technique across both non-overlapping and challenging overlapping ECG samples. For non-overlapping signals, our method achieved a Mean Squared Error (MSE) of 0.0010 and a Pearson Correlation Coefficient (rho) of 0.9644, compared to 0.0015 and 0.9366, respectively, for the baseline. On samples with signal overlap, our method achieved an MSE of 0.0029 and a rho of 0.9641, significantly improving upon the baseline's 0.0178 and 0.8676. This work demonstrates an effective strategy to significantly enhance digitization accuracy, especially in the presence of signal overlaps, thereby laying a strong foundation for the reliable conversion of analog ECG records into analyzable digital data for contemporary research and clinical applications. The implementation is publicly available at this GitHub repository: https://github.com/masoudrahimi39/ECG-code.
Models Developed for Spiking Neural Networks
Dec 08, 2022
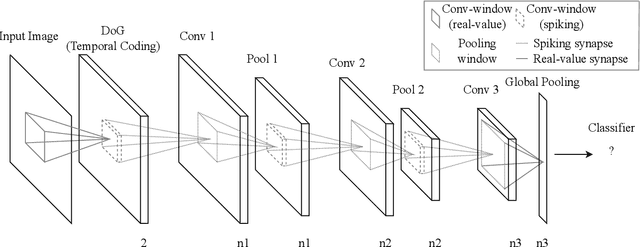
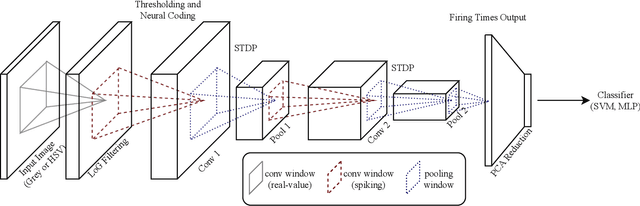
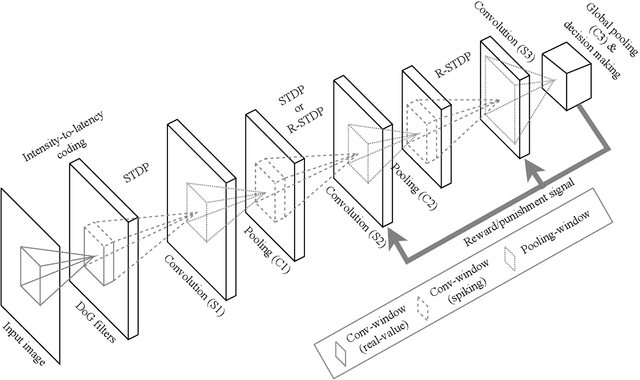
Emergence of deep neural networks (DNNs) has raised enormous attention towards artificial neural networks (ANNs) once again. They have become the state-of-the-art models and have won different machine learning challenges. Although these networks are inspired by the brain, they lack biological plausibility, and they have structural differences compared to the brain. Spiking neural networks (SNNs) have been around for a long time, and they have been investigated to understand the dynamics of the brain. However, their application in real-world and complicated machine learning tasks were limited. Recently, they have shown great potential in solving such tasks. Due to their energy efficiency and temporal dynamics there are many promises in their future development. In this work, we reviewed the structures and performances of SNNs on image classification tasks. The comparisons illustrate that these networks show great capabilities for more complicated problems. Furthermore, the simple learning rules developed for SNNs, such as STDP and R-STDP, can be a potential alternative to replace the backpropagation algorithm used in DNNs.
A Novel Approximate Hamming Weight Computing for Spiking Neural Networks: an FPGA Friendly Architecture
Apr 29, 2021

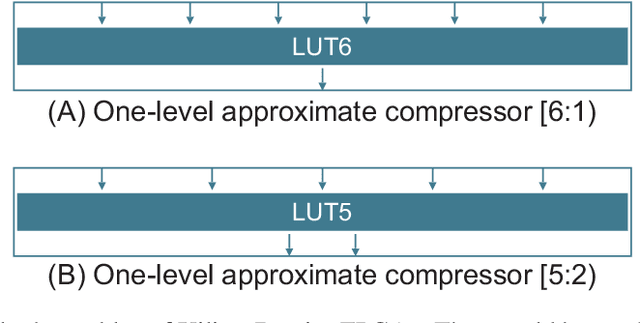

Hamming weights of sparse and long binary vectors are important modules in many scientific applications, particularly in spiking neural networks that are of our interest. To improve both area and latency of their FPGA implementations, we propose a method inspired from synaptic transmission failure for exploiting FPGA lookup tables to compress long input vectors. To evaluate the effectiveness of this approach, we count the number of `1's of the compressed vector using a simple linear adder. We classify the compressors into shallow ones with up to two levels of lookup tables and deep ones with more than two levels. The architecture generated by this approach shows up to 82% and 35% reductions for different configurations of shallow compressors in area and latency respectively. Moreover, our simulation results show that calculating the Hamming weight of a 1024-bit vector of a spiking neural network by the use of only deep compressors preserves the chaotic behavior of the network while slightly impacts on the learning performance.
Attention-based Assisted Excitation for Salient Object Segmentation
Mar 31, 2020
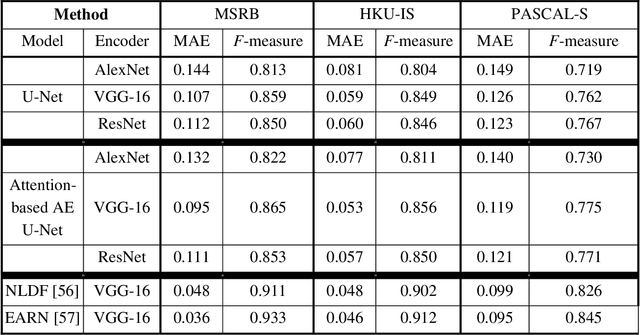
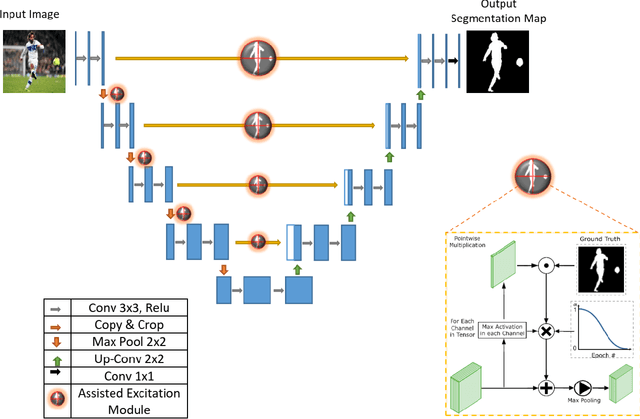

Visual attention brings significant progress for Convolution Neural Networks (CNNs) in various applications. In this paper, object-based attention in human visual cortex inspires us to introduce a mechanism for modification of activations in feature maps of CNNs. In this mechanism, the activations of object locations are excited in feature maps. This mechanism is specifically inspired by gain additive attention modulation in object-based attention in brain. It facilitates figure-ground segregation in the visual cortex. Similar to brain, we use the idea to address two challenges in salient object segmentation: object interior parts and concise boundaries. We implemented it based on U-net model using different architectures in the encoder parts, including AlexNet, VGG, and ResNet. The proposed method was examined on three benchmark datasets: HKU-IS, MSRB, and PASCAL-S. Experimental results showed that the inspired idea could significantly improve the results in terms of mean absolute error and F-measure. The results also showed that our proposed method better captured not only the boundary but also the object interior. Thus, it can tackle the mentioned challenges.
Multi-Representational Learning for Offline Signature Verification using Multi-Loss Snapshot Ensemble of CNNs
Mar 11, 2019
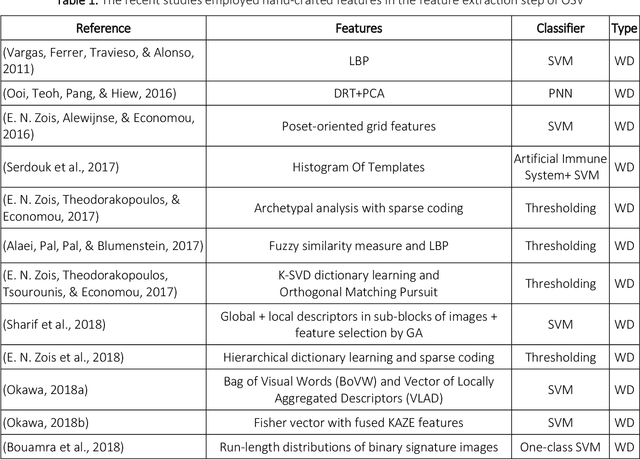
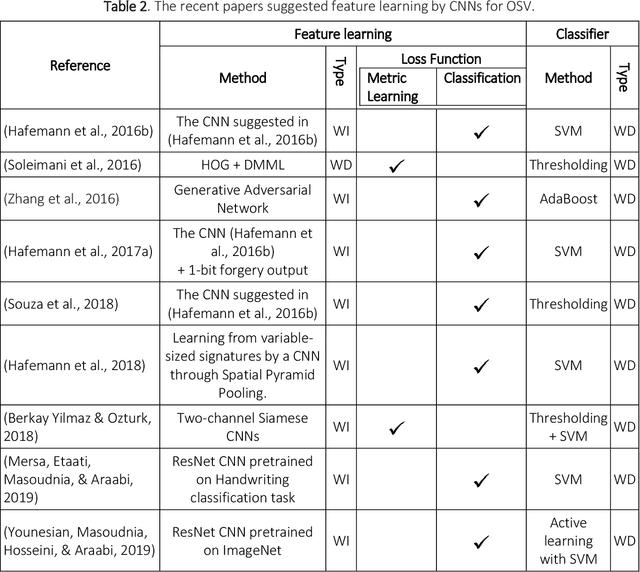
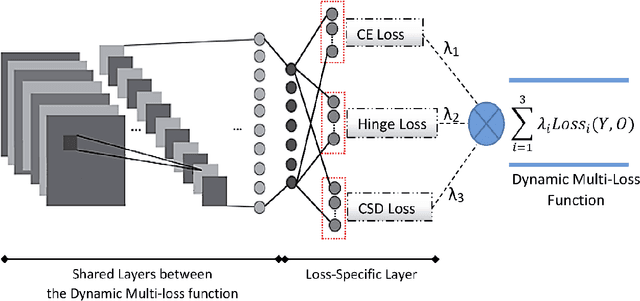
Offline Signature Verification (OSV) is a challenging pattern recognition task, especially in presence of skilled forgeries that are not available during training. This study aims to tackle its challenges and meet the substantial need for generalization for OSV by examining different loss functions for Convolutional Neural Network (CNN). We adopt our new approach to OSV by asking two questions: 1. which classification loss provides more generalization for feature learning in OSV? , and 2. How integration of different losses into a unified multi-loss function lead to an improved learning framework? These questions are studied based on analysis of three loss functions, including cross entropy, Cauchy-Schwarz divergence, and hinge loss. According to complementary features of these losses, we combine them into a dynamic multi-loss function and propose a novel ensemble framework for simultaneous use of them in CNN. Our proposed Multi-Loss Snapshot Ensemble (MLSE) consists of several sequential trials. In each trial, a dominant loss function is selected from the multi-loss set, and the remaining losses act as a regularizer. Different trials learn diverse representations for each input based on signature identification task. This multi-representation set is then employed for the verification task. An ensemble of SVMs is trained on these representations, and their decisions are finally combined according to the selection of most generalizable SVM for each user. We conducted two sets of experiments based on two different protocols of OSV, i.e., writer-dependent and writer-independent on three signature datasets: GPDS-Synthetic, MCYT, and UT-SIG. Based on the writer-dependent OSV protocol, we achieved substantial improvements over the best EERs in the literature. The results of the second set of experiments also confirmed the robustness to the arrival of new users enrolled in the OSV system.