 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Interpretability of Sparse Latent Representations with Class Information
May 20, 2025Variational Autoencoders (VAEs) are powerful generative models for learning latent representations. Standard VAEs generate dispersed and unstructured latent spaces by utilizing all dimensions, which limits their interpretability, especially in high-dimensional spaces. To address this challenge, Variational Sparse Coding (VSC) introduces a spike-and-slab prior distribution, resulting in sparse latent representations for each input. These sparse representations, characterized by a limited number of active dimensions, are inherently more interpretable. Despite this advantage, VSC falls short in providing structured interpretations across samples within the same class. Intuitively, samples from the same class are expected to share similar attributes while allowing for variations in those attributes. This expectation should manifest as consistent patterns of active dimensions in their latent representations, but VSC does not enforce such consistency. In this paper, we propose a novel approach to enhance the latent space interpretability by ensuring that the active dimensions in the latent space are consistent across samples within the same class. To achieve this, we introduce a new loss function that encourages samples from the same class to share similar active dimensions. This alignment creates a more structured and interpretable latent space, where each shared dimension corresponds to a high-level concept, or "factor." Unlike existing disentanglement-based methods that primarily focus on global factors shared across all classes, our method captures both global and class-specific factors, thereby enhancing the utility and interpretability of latent representations.
$Λ$-DARTS: Mitigating Performance Collapse by Harmonizing Operation Selection among Cells
Oct 14, 2022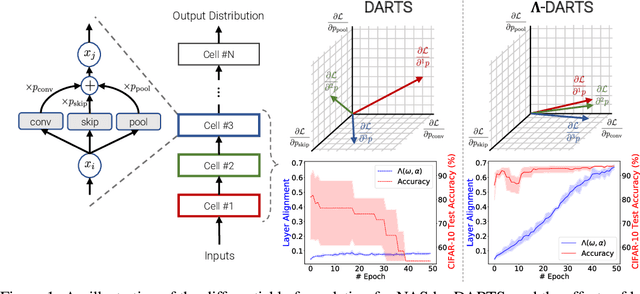
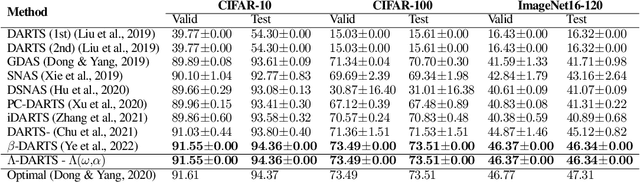

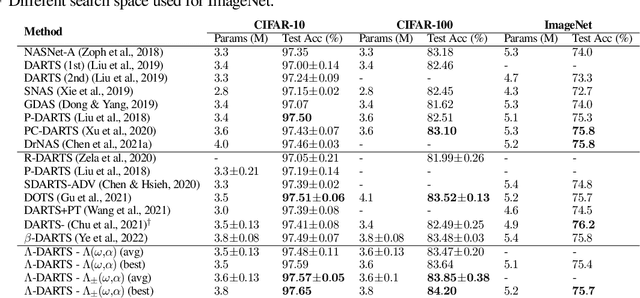
Differentiable neural architecture search (DARTS) is a popular method for neural architecture search (NAS), which performs cell-search and utilizes continuous relaxation to improve the search efficiency via gradient-based optimization. The main shortcoming of DARTS is performance collapse, where the discovered architecture suffers from a pattern of declining quality during search. Performance collapse has become an important topic of research, with many methods trying to solve the issue through either regularization or fundamental changes to DARTS. However, the weight-sharing framework used for cell-search in DARTS and the convergence of architecture parameters has not been analyzed yet. In this paper, we provide a thorough and novel theoretical and empirical analysis on DARTS and its point of convergence. We show that DARTS suffers from a specific structural flaw due to its weight-sharing framework that limits the convergence of DARTS to saturation points of the softmax function. This point of convergence gives an unfair advantage to layers closer to the output in choosing the optimal architecture, causing performance collapse. We then propose two new regularization terms that aim to prevent performance collapse by harmonizing operation selection via aligning gradients of layers. Experimental results on six different search spaces and three different datasets show that our method ($\Lambda$-DARTS) does indeed prevent performance collapse, providing justification for our theoretical analysis and the proposed remedy.
Assisted Excitation of Activations: A Learning Technique to Improve Object Detectors
Jun 12, 2019
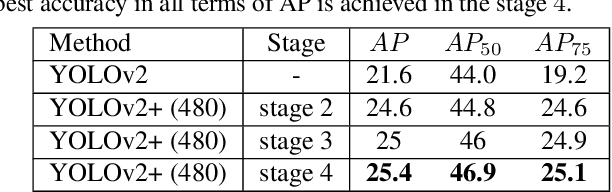


We present a simple and effective learning technique that significantly improves mAP of YOLO object detectors without compromising their speed. During network training, we carefully feed in localization information. We excite certain activations in order to help the network learn to better localize. In the later stages of training, we gradually reduce our assisted excitation to zero. We reached a new state-of-the-art in the speed-accuracy trade-off. Our technique improves the mAP of YOLOv2 by 3.8% and mAP of YOLOv3 by 2.2% on MSCOCO dataset.This technique is inspired from curriculum learning. It is simple and effective and it is applicable to most single-stage object detectors.
Evaluation of Dataflow through layers of Deep Neural Networks in Classification and Regression Problems
Jun 12, 2019This paper introduces two straightforward, effective indices to evaluate the input data and the data flowing through layers of a feedforward deep neural network. For classification problems, the separation rate of target labels in the space of dataflow is explained as a key factor indicating the performance of designed layers in improving the generalization of the network. According to the explained concept, a shapeless distance-based evaluation index is proposed. Similarly, for regression problems, the smoothness rate of target outputs in the space of dataflow is explained as a key factor indicating the performance of designed layers in improving the generalization of the network. According to the explained smoothness concept, a shapeless distance-based smoothness index is proposed for regression problems. To consider more strictly concepts of separation and smoothness, their extended versions are introduced, and by interpreting a regression problem as a classification problem, it is shown that the separation and smoothness indices are related together. Through four case studies, the profits of using the introduced indices are shown. In the first case study, for classification and regression problems , the challenging of some known input datasets are compared respectively by the proposed separation and smoothness indices. In the second case study, the quality of dataflow is evaluated through layers of two pre-trained VGG 16 networks in classification of Cifar10 and Cifar100. In the third case study, it is shown that the correct classification rate and the separation index are almost equivalent through layers particularly while the serration index is increased. In the last case study, two multi-layer neural networks, which are designed for the prediction of Boston Housing price, are compared layer by layer by using the proposed smoothness index.
Multi-Representational Learning for Offline Signature Verification using Multi-Loss Snapshot Ensemble of CNNs
Mar 11, 2019
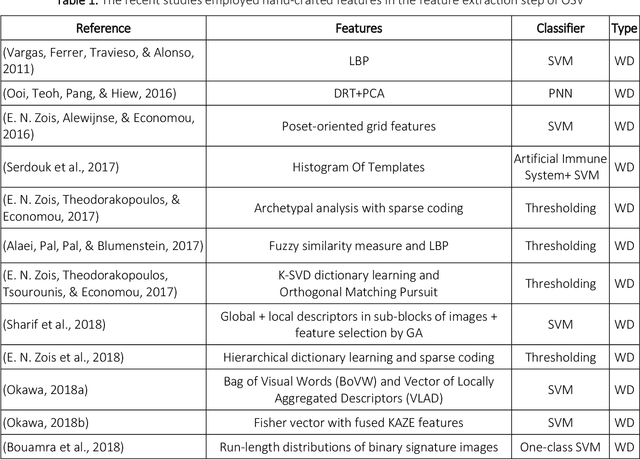
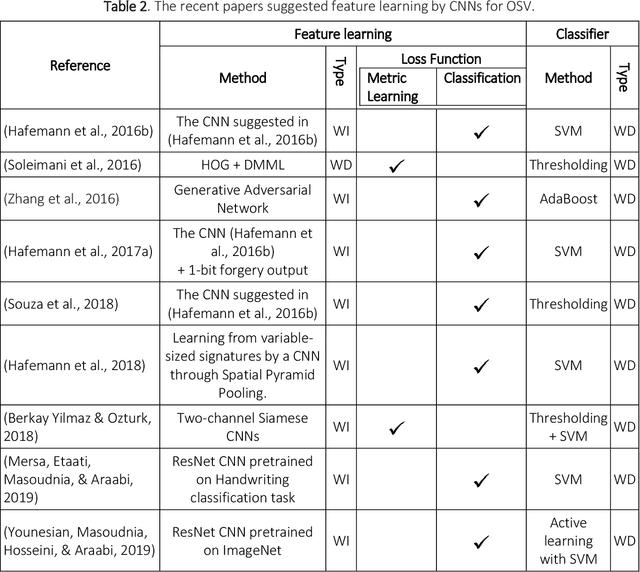
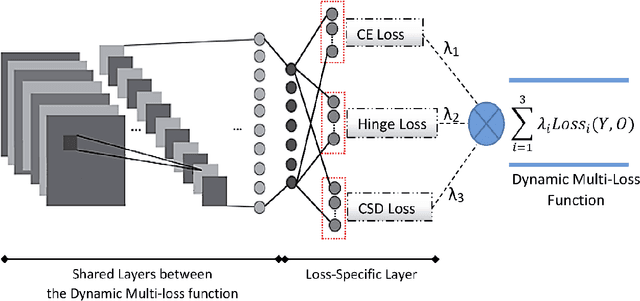
Offline Signature Verification (OSV) is a challenging pattern recognition task, especially in presence of skilled forgeries that are not available during training. This study aims to tackle its challenges and meet the substantial need for generalization for OSV by examining different loss functions for Convolutional Neural Network (CNN). We adopt our new approach to OSV by asking two questions: 1. which classification loss provides more generalization for feature learning in OSV? , and 2. How integration of different losses into a unified multi-loss function lead to an improved learning framework? These questions are studied based on analysis of three loss functions, including cross entropy, Cauchy-Schwarz divergence, and hinge loss. According to complementary features of these losses, we combine them into a dynamic multi-loss function and propose a novel ensemble framework for simultaneous use of them in CNN. Our proposed Multi-Loss Snapshot Ensemble (MLSE) consists of several sequential trials. In each trial, a dominant loss function is selected from the multi-loss set, and the remaining losses act as a regularizer. Different trials learn diverse representations for each input based on signature identification task. This multi-representation set is then employed for the verification task. An ensemble of SVMs is trained on these representations, and their decisions are finally combined according to the selection of most generalizable SVM for each user. We conducted two sets of experiments based on two different protocols of OSV, i.e., writer-dependent and writer-independent on three signature datasets: GPDS-Synthetic, MCYT, and UT-SIG. Based on the writer-dependent OSV protocol, we achieved substantial improvements over the best EERs in the literature. The results of the second set of experiments also confirmed the robustness to the arrival of new users enrolled in the OSV system.
Active Transfer Learning for Persian Offline Signature Verification
Feb 28, 2019
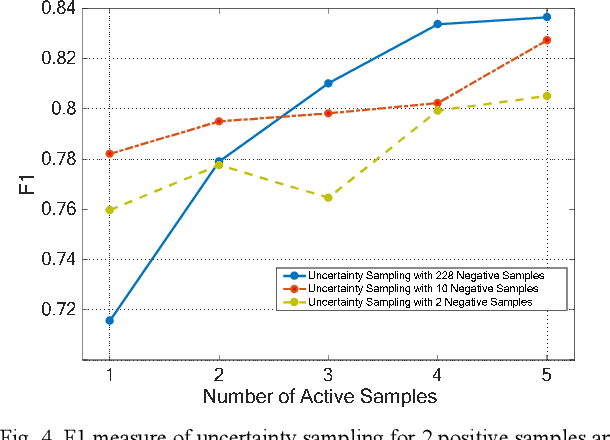
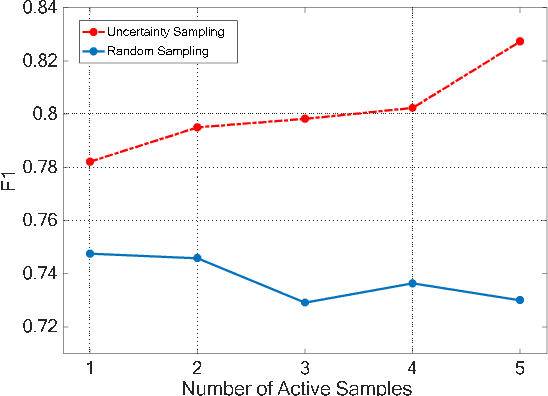
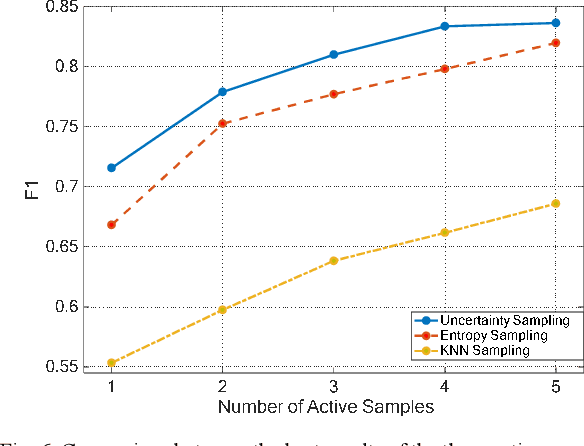
Offline Signature Verification (OSV) remains a challenging pattern recognition task, especially in the presence of skilled forgeries that are not available during the training. This challenge is aggravated when there are small labeled training data available but with large intra-personal variations. In this study, we address this issue by employing an active learning approach, which selects the most informative instances to label and therefore reduces the human labeling effort significantly. Our proposed OSV includes three steps: feature learning, active learning, and final verification. We benefit from transfer learning using a pre-trained CNN for feature learning. We also propose SVM-based active learning for each user to separate his genuine signatures from the random forgeries. We finally used the SVMs to verify the authenticity of the questioned signature. We examined our proposed active transfer learning method on UTSig: A Persian offline signature dataset. We achieved near 13% improvement compared to the random selection of instances. Our results also showed 1% improvement over the state-of-the-art method in which a fully supervised setting with five more labeled instances per user was used.
Learning Representations from Persian Handwriting for Offline Signature Verification, a Deep Transfer Learning Approach
Feb 28, 2019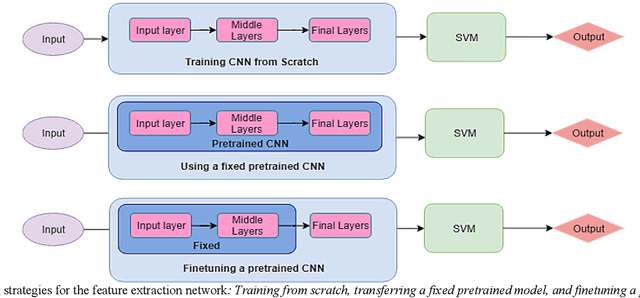

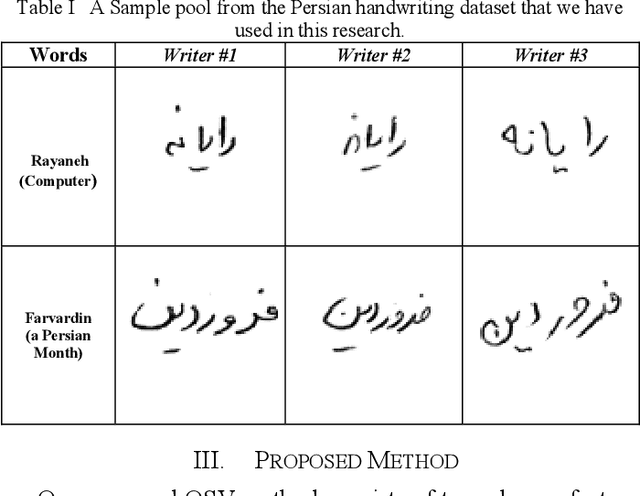

Offline Signature Verification (OSV) is a challenging pattern recognition task, especially when it is expected to generalize well on the skilled forgeries that are not available during the training. Its challenges also include small training sample and large intra-class variations. Considering the limitations, we suggest a novel transfer learning approach from Persian handwriting domain to multi-language OSV domain. We train two Residual CNNs on the source domain separately based on two different tasks of word classification and writer identification. Since identifying a person signature resembles identifying ones handwriting, it seems perfectly convenient to use handwriting for the feature learning phase. The learned representation on the more varied and plentiful handwriting dataset can compensate for the lack of training data in the original task, i.e. OSV, without sacrificing the generalizability. Our proposed OSV system includes two steps: learning representation and verification of the input signature. For the first step, the signature images are fed into the trained Residual CNNs. The output representations are then used to train SVMs for the verification. We test our OSV system on three different signature datasets, including MCYT (a Spanish signature dataset), UTSig (a Persian one) and GPDS-Synthetic (an artificial dataset). On UT-SIG, we achieved 9.80% Equal Error Rate (EER) which showed substantial improvement over the best EER in the literature, 17.45%. Our proposed method surpassed state-of-the-arts by 6% on GPDS-Synthetic, achieving 6.81%. On MCYT, EER of 3.98% was obtained which is comparable to the best previously reported results.
UTSig: A Persian Offline Signature Dataset
Aug 12, 2016


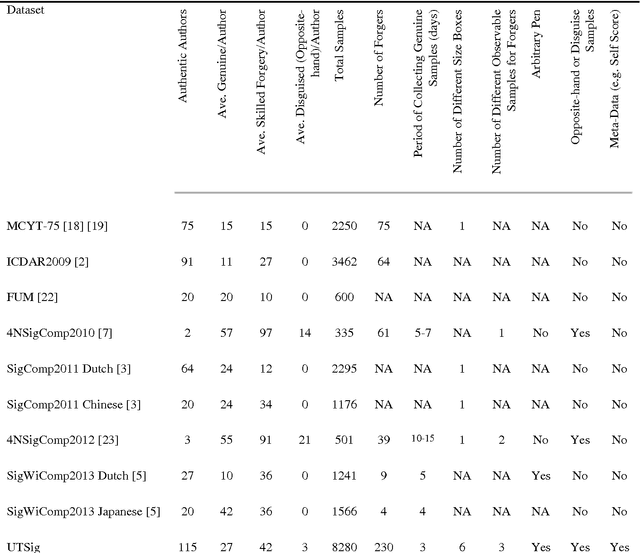
The pivotal role of datasets in signature verification systems motivates researchers to collect signature samples. Distinct characteristics of Persian signature demands for richer and culture-dependent offline signature datasets. This paper introduces a new and public Persian offline signature dataset, UTSig, that consists of 8280 images from 115 classes. Each class has 27 genuine signatures, 3 opposite-hand signatures, and 42 skilled forgeries made by 6 forgers. Compared with the other public datasets, UTSig has more samples, more classes, and more forgers. We considered various variables including signing period, writing instrument, signature box size, and number of observable samples for forgers in the data collection procedure. By careful examination of main characteristics of offline signature datasets, we observe that Persian signatures have fewer numbers of branch points and end points. We propose and evaluate four different training and test setups for UTSig. Results of our experiments show that training genuine samples along with opposite-hand samples and random forgeries can improve the performance in terms of equal error rate and minimum cost of log likelihood ratio.
Pigment Melanin: Pattern for Iris Recognition
Nov 29, 2009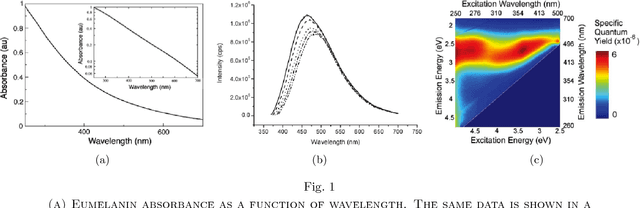
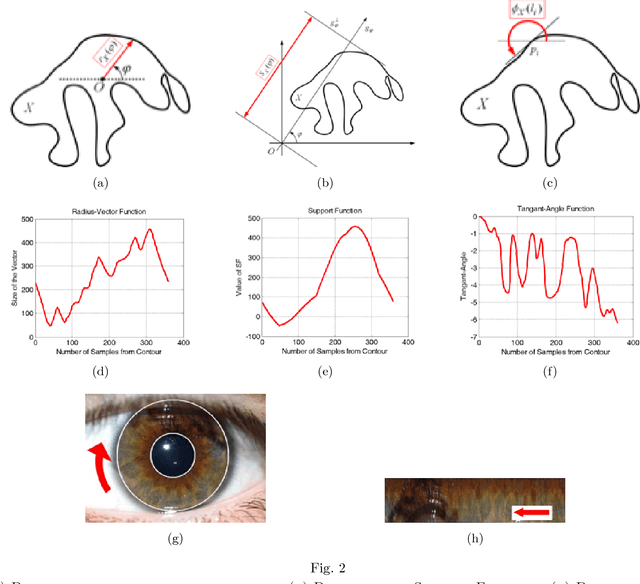


Recognition of iris based on Visible Light (VL) imaging is a difficult problem because of the light reflection from the cornea. Nonetheless, pigment melanin provides a rich feature source in VL, unavailable in Near-Infrared (NIR) imaging. This is due to biological spectroscopy of eumelanin, a chemical not stimulated in NIR. In this case, a plausible solution to observe such patterns may be provided by an adaptive procedure using a variational technique on the image histogram. To describe the patterns, a shape analysis method is used to derive feature-code for each subject. An important question is how much the melanin patterns, extracted from VL, are independent of iris texture in NIR. With this question in mind, the present investigation proposes fusion of features extracted from NIR and VL to boost the recognition performance. We have collected our own database (UTIRIS) consisting of both NIR and VL images of 158 eyes of 79 individuals. This investigation demonstrates that the proposed algorithm is highly sensitive to the patterns of cromophores and improves the iris recognition rate.