 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT for Evidence Retrieval and Claim Verification
Oct 07, 2019
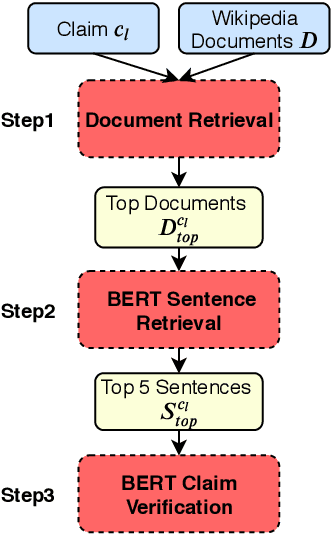

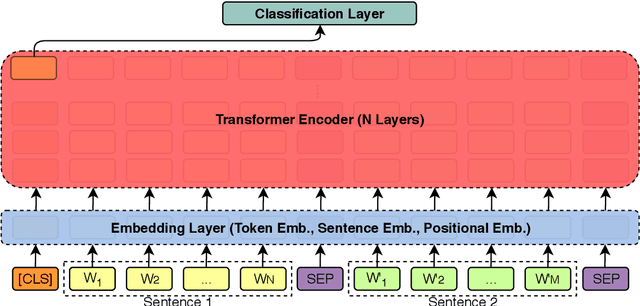
Motivated by the promising performance of pre-trained language models, we investigate BERT in an evidence retrieval and claim verification pipeline for the FEVER fact extraction and verification challenge. To this end, we propose to use two BERT models, one for retrieving potential evidence sentences supporting or rejecting claims, and another for verifying claims based on the predicted evidence sets. To train the BERT retrieval system, we use pointwise and pairwise loss functions, and examine the effect of hard negative mining. A second BERT model is trained to classify the samples as supported, refuted, and not enough information. Our system achieves a new state of the art recall of 87.1 for retrieving top five sentences out of the FEVER documents consisting of 50K Wikipedia pages, and scores second in the official leaderboard with the FEVER score of 69.7.
Convolutional Neural Networks for Aerial Vehicle Detection and Recognition
Aug 26, 2018
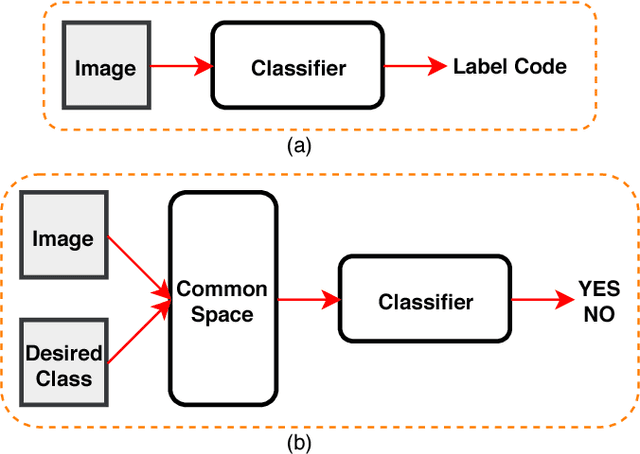


This paper investigates the problem of aerial vehicle recognition using a text-guided deep convolutional neural network classifier. The network receives an aerial image and a desired class, and makes a yes or no output by matching the image and the textual description of the desired class. We train and test our model on a synthetic aerial dataset and our desired classes consist of the combination of the class types and colors of the vehicles. This strategy helps when considering more classes in testing than in training.
Convolutional Neural Networks for Aerial Multi-Label Pedestrian Detection
Jul 16, 2018

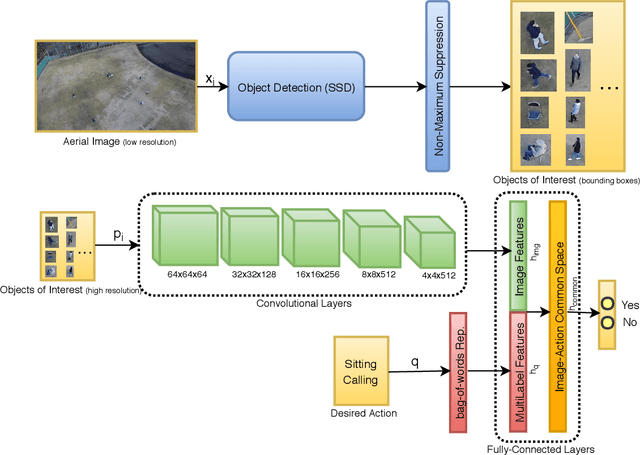

The low resolution of objects of interest in aerial images makes pedestrian detection and action detection extremely challenging tasks. Furthermore, using deep convolutional neural networks to process large images can be demanding in terms of computational requirements. In order to alleviate these challenges, we propose a two-step, yes and no question answering framework to find specific individuals doing one or multiple specific actions in aerial images. First, a deep object detector, Single Shot Multibox Detector (SSD), is used to generate object proposals from small aerial images. Second, another deep network, is used to learn a latent common sub-space which associates the high resolution aerial imagery and the pedestrian action labels that are provided by the human-based sources
UTSig: A Persian Offline Signature Dataset
Aug 12, 2016


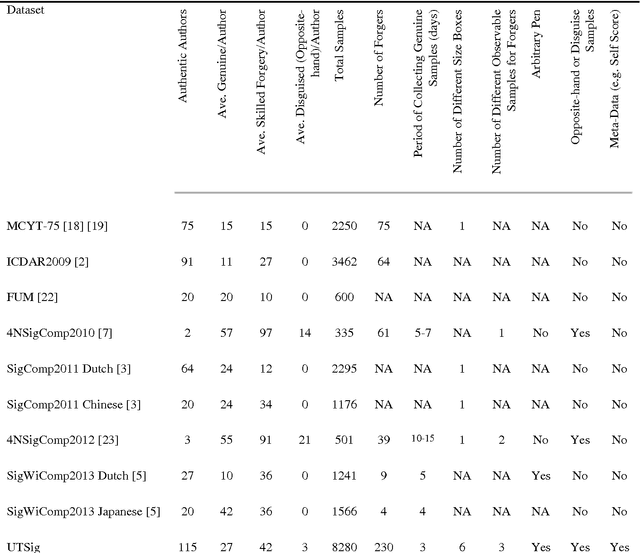
The pivotal role of datasets in signature verification systems motivates researchers to collect signature samples. Distinct characteristics of Persian signature demands for richer and culture-dependent offline signature datasets. This paper introduces a new and public Persian offline signature dataset, UTSig, that consists of 8280 images from 115 classes. Each class has 27 genuine signatures, 3 opposite-hand signatures, and 42 skilled forgeries made by 6 forgers. Compared with the other public datasets, UTSig has more samples, more classes, and more forgers. We considered various variables including signing period, writing instrument, signature box size, and number of observable samples for forgers in the data collection procedure. By careful examination of main characteristics of offline signature datasets, we observe that Persian signatures have fewer numbers of branch points and end points. We propose and evaluate four different training and test setups for UTSig. Results of our experiments show that training genuine samples along with opposite-hand samples and random forgeries can improve the performance in terms of equal error rate and minimum cost of log likelihood ratio.