 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Neural Networks for Aerial Multi-Label Pedestrian Detection
Paper and Code


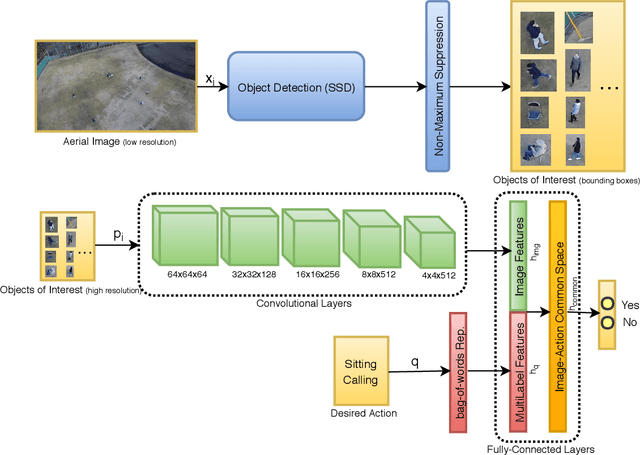

The low resolution of objects of interest in aerial images makes pedestrian detection and action detection extremely challenging tasks. Furthermore, using deep convolutional neural networks to process large images can be demanding in terms of computational requirements. In order to alleviate these challenges, we propose a two-step, yes and no question answering framework to find specific individuals doing one or multiple specific actions in aerial images. First, a deep object detector, Single Shot Multibox Detector (SSD), is used to generate object proposals from small aerial images. Second, another deep network, is used to learn a latent common sub-space which associates the high resolution aerial imagery and the pedestrian action labels that are provided by the human-based sources