 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT for Evidence Retrieval and Claim Verification
Paper and Code

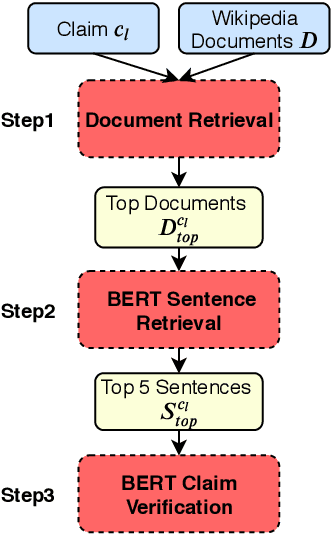

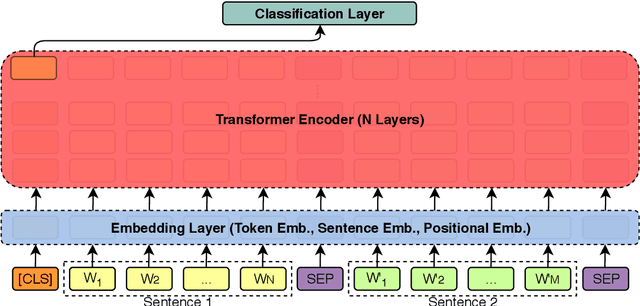
Motivated by the promising performance of pre-trained language models, we investigate BERT in an evidence retrieval and claim verification pipeline for the FEVER fact extraction and verification challenge. To this end, we propose to use two BERT models, one for retrieving potential evidence sentences supporting or rejecting claims, and another for verifying claims based on the predicted evidence sets. To train the BERT retrieval system, we use pointwise and pairwise loss functions, and examine the effect of hard negative mining. A second BERT model is trained to classify the samples as supported, refuted, and not enough information. Our system achieves a new state of the art recall of 87.1 for retrieving top five sentences out of the FEVER documents consisting of 50K Wikipedia pages, and scores second in the official leaderboard with the FEVER score of 69.7.