 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Expertise of Non-Expert and Diverse Agents in Social Bandit Learning: A Free Energy Approach
Mar 12, 2026Personalized AI-based services involve a population of individual reinforcement learning agents. However, most reinforcement learning algorithms focus on harnessing individual learning and fail to leverage the social learning capabilities commonly exhibited by humans and animals. Social learning integrates individual experience with observing others' behavior, presenting opportunities for improved learning outcomes. In this study, we focus on a social bandit learning scenario where a social agent observes other agents' actions without knowledge of their rewards. The agents independently pursue their own policy without explicit motivation to teach each other. We propose a free energy-based social bandit learning algorithm over the policy space, where the social agent evaluates others' expertise levels without resorting to any oracle or social norms. Accordingly, the social agent integrates its direct experiences in the environment and others' estimated policies. The theoretical convergence of our algorithm to the optimal policy is proven. Empirical evaluations validate the superiority of our social learning method over alternative approaches in various scenarios. Our algorithm strategically identifies the relevant agents, even in the presence of random or suboptimal agents, and skillfully exploits their behavioral information. In addition to societies including expert agents, in the presence of relevant but non-expert agents, our algorithm significantly enhances individual learning performance, where most related methods fail. Importantly, it also maintains logarithmic regret.
A Dual-Axis Taxonomy of Knowledge Editing for LLMs: From Mechanisms to Functions
Aug 12, 2025Large language models (LLMs) acquire vast knowledge from large text corpora, but this information can become outdated or inaccurate. Since retraining is computationally expensive, knowledge editing offers an efficient alternative -- modifying internal knowledge without full retraining. These methods aim to update facts precisely while preserving the model's overall capabilities. While existing surveys focus on the mechanism of editing (e.g., parameter changes vs. external memory), they often overlook the function of the knowledge being edited. This survey introduces a novel, complementary function-based taxonomy to provide a more holistic view. We examine how different mechanisms apply to various knowledge types -- factual, temporal, conceptual, commonsense, and social -- highlighting how editing effectiveness depends on the nature of the target knowledge. By organizing our review along these two axes, we map the current landscape, outline the strengths and limitations of existing methods, define the problem formally, survey evaluation tasks and datasets, and conclude with open challenges and future directions.
DEEPQUESTION: Systematic Generation of Real-World Challenges for Evaluating LLMs Performance
May 30, 2025LLMs often excel on standard benchmarks but falter on real-world tasks. We introduce DeepQuestion, a scalable automated framework that augments existing datasets based on Bloom's taxonomy and creates novel questions that trace original solution paths to probe evaluative and creative skills. Extensive experiments across ten open-source and proprietary models, covering both general-purpose and reasoning LLMs, reveal substantial performance drops (even up to 70% accuracy loss) on higher-order tasks, underscoring persistent gaps in deep reasoning. Our work highlights the need for cognitively diverse benchmarks to advance LLM progress. DeepQuestion and related datasets will be released upon acceptance of the paper.
Subgoal Discovery Using a Free Energy Paradigm and State Aggregations
Dec 21, 2024



Reinforcement learning (RL) plays a major role in solving complex sequential decision-making tasks. Hierarchical and goal-conditioned RL are promising methods for dealing with two major problems in RL, namely sample inefficiency and difficulties in reward shaping. These methods tackle the mentioned problems by decomposing a task into simpler subtasks and temporally abstracting a task in the action space. One of the key components for task decomposition of these methods is subgoal discovery. We can use the subgoal states to define hierarchies of actions and also use them in decomposing complex tasks. Under the assumption that subgoal states are more unpredictable, we propose a free energy paradigm to discover them. This is achieved by using free energy to select between two spaces, the main space and an aggregation space. The $model \; changes$ from neighboring states to a given state shows the unpredictability of a given state, and therefore it is used in this paper for subgoal discovery. Our empirical results on navigation tasks like grid-world environments show that our proposed method can be applied for subgoal discovery without prior knowledge of the task. Our proposed method is also robust to the stochasticity of environments.
Optimizing Alignment with Less: Leveraging Data Augmentation for Personalized Evaluation
Dec 10, 2024



Automatic evaluation by large language models (LLMs) is a prominent topic today; however, judgment and evaluation tasks are often subjective and influenced by various factors, making adaptation challenging. While many studies demonstrate the capabilities of state-of-the-art proprietary LLMs in comparison to human evaluators, they often struggle to adapt to reference evaluators over time, a requirement for achieving personalized judgment. Additionally, numerous works have attempted to apply open LLMs as judges or evaluators, but these efforts frequently overlook the limitations of working with scarce data. Personalized judgment is inherently associated with limited data scenarios, which are common in many real-world problems. Our work aims to present a data augmentation technique to select a more effective sample from limited data in order to align an open LLM with human preference. Our work achieves approximately 7% improvements in Pearson correlation with a reference judge over the baseline,and 30% improvement over the base model (Llama3.1-8B-Instruct) in the mathematical reasoning evaluation task. demonstrating that augmenting selecting more effective preference data enables our approach to surpass baseline methods.
A Survey On Enhancing Reinforcement Learning in Complex Environments: Insights from Human and LLM Feedback
Nov 20, 2024



Reinforcement learning (RL) is one of the active fields in machine learning, demonstrating remarkable potential in tackling real-world challenges. Despite its promising prospects, this methodology has encountered with issues and challenges, hindering it from achieving the best performance. In particular, these approaches lack decent performance when navigating environments and solving tasks with large observation space, often resulting in sample-inefficiency and prolonged learning times. This issue, commonly referred to as the curse of dimensionality, complicates decision-making for RL agents, necessitating a careful balance between attention and decision-making. RL agents, when augmented with human or large language models' (LLMs) feedback, may exhibit resilience and adaptability, leading to enhanced performance and accelerated learning. Such feedback, conveyed through various modalities or granularities including natural language, serves as a guide for RL agents, aiding them in discerning relevant environmental cues and optimizing decision-making processes. In this survey paper, we mainly focus on problems of two-folds: firstly, we focus on humans or an LLMs assistance, investigating the ways in which these entities may collaborate with the RL agent in order to foster optimal behavior and expedite learning; secondly, we delve into the research papers dedicated to addressing the intricacies of environments characterized by large observation space.
CoCoP: Enhancing Text Classification with LLM through Code Completion Prompt
Nov 13, 2024



Text classification is a fundamental task in natural language processing (NLP), and large language models (LLMs) have demonstrated their capability to perform this task across various domains. However, the performance of LLMs heavily depends on the quality of their input prompts. Recent studies have also shown that LLMs exhibit remarkable results in code-related tasks. To leverage the capabilities of LLMs in text classification, we propose the Code Completion Prompt (CoCoP) method, which transforms the text classification problem into a code completion task. CoCoP significantly improves text classification performance across diverse datasets by utilizing LLMs' code-completion capability. For instance, CoCoP enhances the accuracy of the SST2 dataset by more than 20%. Moreover, when CoCoP integrated with LLMs specifically designed for code-related tasks (code models), such as CodeLLaMA, this method demonstrates better or comparable performance to few-shot learning techniques while using only one-tenth of the model size. The source code of our proposed method will be available to the public upon the acceptance of the paper.
Risk Sensitivity in Markov Games and Multi-Agent Reinforcement Learning: A Systematic Review
Jun 10, 2024

Markov games (MGs) and multi-agent reinforcement learning (MARL) are studied to model decision making in multi-agent systems. Traditionally, the objective in MG and MARL has been risk-neutral, i.e., agents are assumed to optimize a performance metric such as expected return, without taking into account subjective or cognitive preferences of themselves or of other agents. However, ignoring such preferences leads to inaccurate models of decision making in many real-world scenarios in finance, operations research, and behavioral economics. Therefore, when these preferences are present, it is necessary to incorporate a suitable measure of risk into the optimization objective of agents, which opens the door to risk-sensitive MG and MARL. In this paper, we systemically review the literature on risk sensitivity in MG and MARL that has been growing in recent years alongside other areas of reinforcement learning and game theory. We define and mathematically describe different risk measures used in MG and MARL and individually for each measure, discuss articles that incorporate it. Finally, we identify recent trends in theoretical and applied works in the field and discuss possible directions of future research.
Reinforcement Learning with Subspaces using Free Energy Paradigm
Dec 13, 2020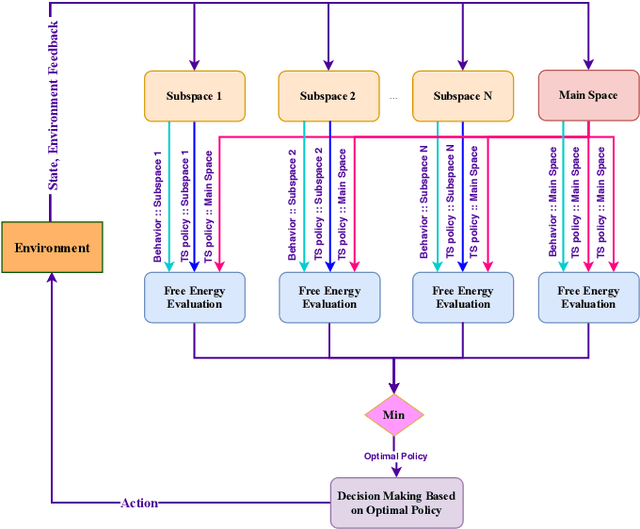
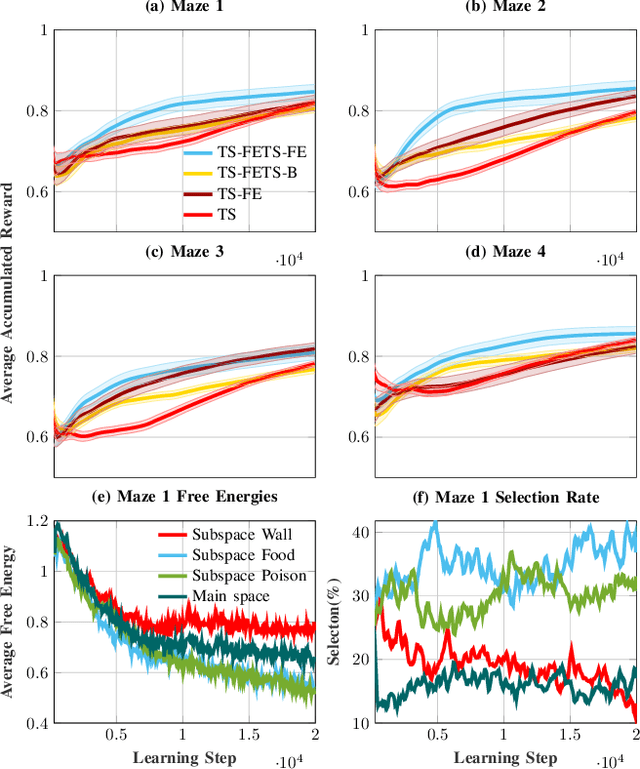
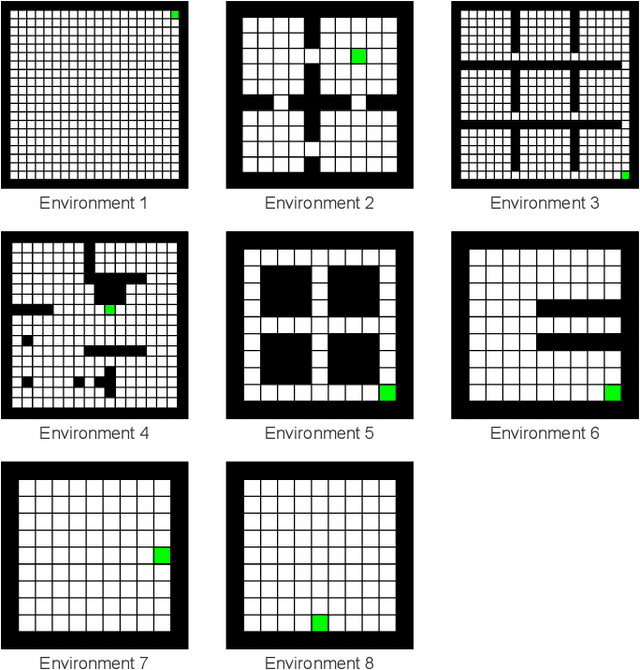
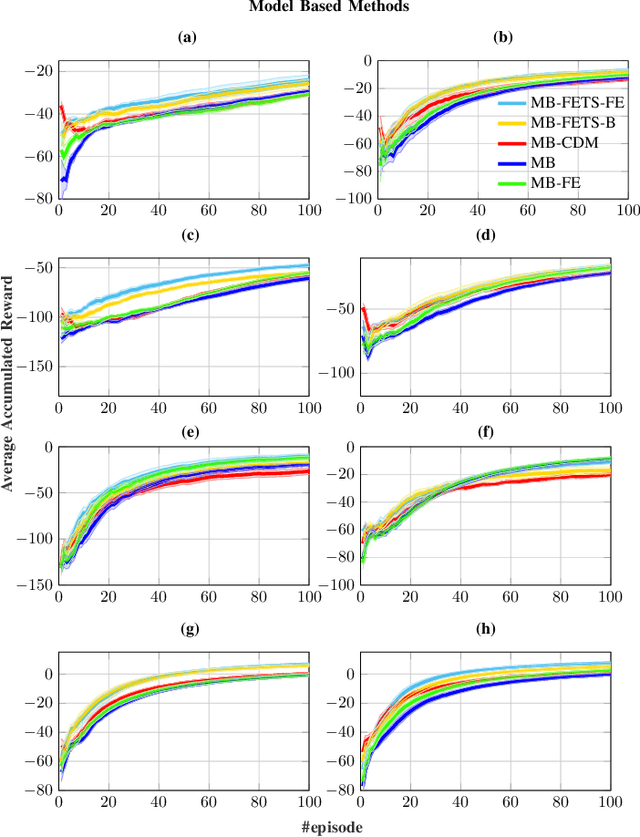
In large-scale problems, standard reinforcement learning algorithms suffer from slow learning speed. In this paper, we follow the framework of using subspaces to tackle this problem. We propose a free-energy minimization framework for selecting the subspaces and integrate the policy of the state-space into the subspaces. Our proposed free-energy minimization framework rests upon Thompson sampling policy and behavioral policy of subspaces and the state-space. It is therefore applicable to a variety of tasks, discrete or continuous state space, model-free and model-based tasks. Through a set of experiments, we show that this general framework highly improves the learning speed. We also provide a convergence proof.
Multi-Representational Learning for Offline Signature Verification using Multi-Loss Snapshot Ensemble of CNNs
Mar 11, 2019
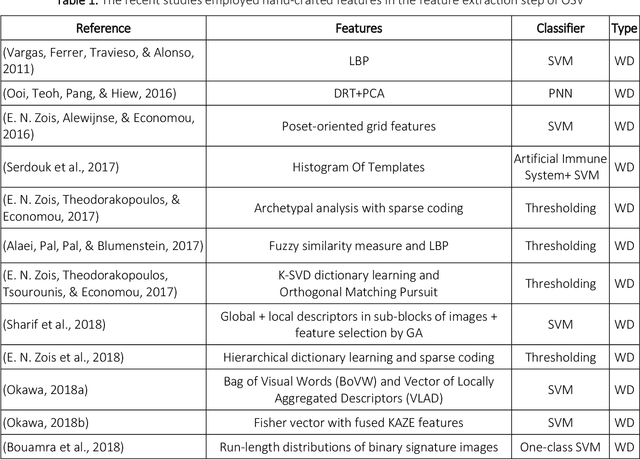
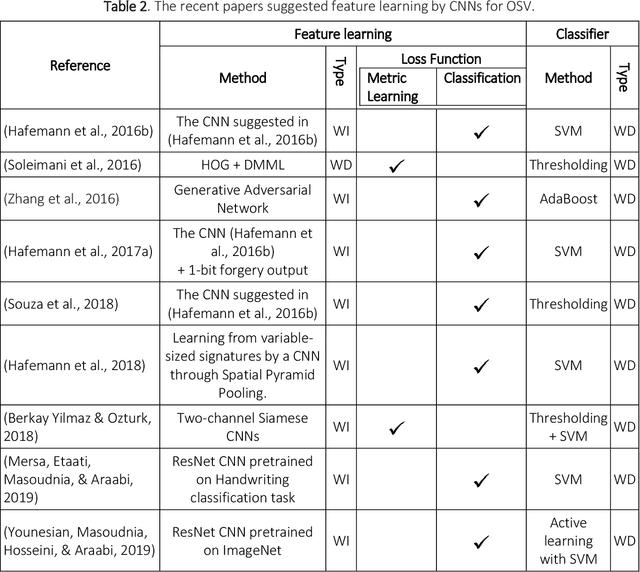
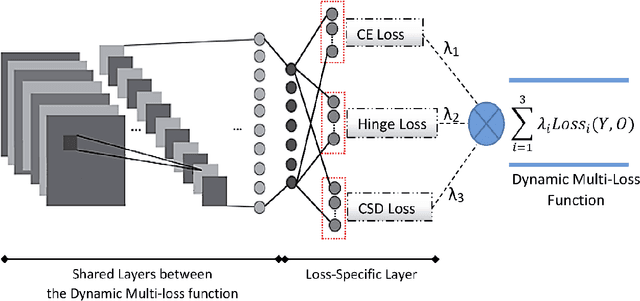
Offline Signature Verification (OSV) is a challenging pattern recognition task, especially in presence of skilled forgeries that are not available during training. This study aims to tackle its challenges and meet the substantial need for generalization for OSV by examining different loss functions for Convolutional Neural Network (CNN). We adopt our new approach to OSV by asking two questions: 1. which classification loss provides more generalization for feature learning in OSV? , and 2. How integration of different losses into a unified multi-loss function lead to an improved learning framework? These questions are studied based on analysis of three loss functions, including cross entropy, Cauchy-Schwarz divergence, and hinge loss. According to complementary features of these losses, we combine them into a dynamic multi-loss function and propose a novel ensemble framework for simultaneous use of them in CNN. Our proposed Multi-Loss Snapshot Ensemble (MLSE) consists of several sequential trials. In each trial, a dominant loss function is selected from the multi-loss set, and the remaining losses act as a regularizer. Different trials learn diverse representations for each input based on signature identification task. This multi-representation set is then employed for the verification task. An ensemble of SVMs is trained on these representations, and their decisions are finally combined according to the selection of most generalizable SVM for each user. We conducted two sets of experiments based on two different protocols of OSV, i.e., writer-dependent and writer-independent on three signature datasets: GPDS-Synthetic, MCYT, and UT-SIG. Based on the writer-dependent OSV protocol, we achieved substantial improvements over the best EERs in the literature. The results of the second set of experiments also confirmed the robustness to the arrival of new users enrolled in the OSV system.