 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialectics of Alignment: Harnessing Unsafe Knowledge for Dynamic Safety Routing
May 30, 2026The prevailing paradigm in large language model (LLM) alignment operates via erasure, filtering unsafe data or training models to strictly refuse harmful prompts. While effective at reducing immediate toxicity, this approach fundamentally constricts the model's epistemological scope, resulting in over-cautious systems that output uninformative blanket refusals to sensitive yet benign queries. In this work, we challenge the orthodoxy that unsafe data must be discarded. We propose a dialectical approach to alignment, positing that unsafe data encodes rich, domain specific knowledge critical for nuanced, safe, and informative generation. To operationalize this, we introduce SafeMoE, a Mixture-of-Experts (MoE) framework that isolates unsafe knowledge into domain-specific Low-Rank Adapters (LoRA experts) trained exclusively on harmful corpora. To synthesize safety from these unsafe primitives, we train a lightweight gating network using a minimal, highly curated set of safe-informative responses. During inference, this router dynamically orchestrates the unsafe experts, effectively steering the generation trajectory to harness their deep domain knowledge while strictly enforcing safety constraints. Extensive empirical evaluations across stringent safety benchmarks demonstrate that SafeMoE is not only safer, achieving over a 20% relative improvement in safe response rate (more than a 15% absolute gain), but also produces more informative responses when safety and harmfulness are of paramount concern. Furthermore, the routing mechanism exhibits strong zero-shot generalization to unseen domains and broader safety tasks without domain-specific supervision. Our findings suggest a paradigm shift in alignment: true safety requires not the masking of unsafe knowledge, but its controlled integration.
Probabilistic Calibration Is a Trainable Capability in Language Models
May 12, 2026Language models are increasingly used in settings where outputs must satisfy user-specified randomness constraints, yet their generation probabilities are often poorly calibrated to those targets. We study whether this capability can be improved directly through fine-tuning. Concretely, we fine-tune language models on synthetic prompts that require sampling from mathematical distributions, and compare two Calibration Fine-Tuning variants: a soft-target method that converts the desired output distribution into trie-derived next-token targets, and a hard-target method that trains on sampled completions from the same target distribution. Across 12 models spanning four families, both methods substantially improve structured-sampling fidelity on held-out distribution families and unseen parameter settings, showing that probabilistic calibration is a trainable capability. Under our selected training configurations, the two methods exhibit different empirical profiles: hard-target fine-tuning is often strongest on structured numeric sampling, while soft-target fine-tuning performs better on broader stochastic generation benchmarks, including open-ended random generation, multiple-choice answer-position balancing, and NoveltyBench. The gains sometimes reduce downstream capability, especially arithmetic reasoning, with costs varying by model. Overall, our results show that probabilistic calibration can be improved through fine-tuning, with our hard-target configuration favoring exact numeric fidelity and our soft-target configuration favoring broader stochastic transfer. Code is available at https://github.com/chandar-lab/calibration-finetuning.
REAM: Merging Improves Pruning of Experts in LLMs
Apr 06, 2026Mixture-of-Experts (MoE) large language models (LLMs) are among the top-performing architectures. The largest models, often with hundreds of billions of parameters, pose significant memory challenges for deployment. Traditional approaches to reduce memory requirements include weight pruning and quantization. Motivated by the Router-weighted Expert Activation Pruning (REAP) that prunes experts, we propose a novel method, Router-weighted Expert Activation Merging (REAM). Instead of removing experts, REAM groups them and merges their weights, better preserving original performance. We evaluate REAM against REAP and other baselines across multiple MoE LLMs on diverse multiple-choice (MC) question answering and generative (GEN) benchmarks. Our results reveal a trade-off between MC and GEN performance that depends on the mix of calibration data. By controlling the mix of general, math and coding data, we examine the Pareto frontier of this trade-off and show that REAM often outperforms the baselines and in many cases is comparable to the original uncompressed models.
Sub-goal Distillation: A Method to Improve Small Language Agents
May 04, 2024
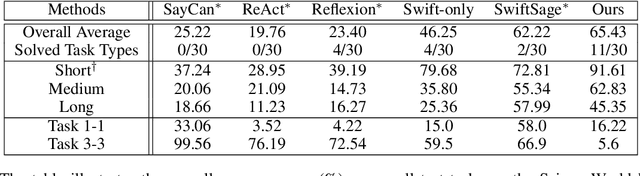
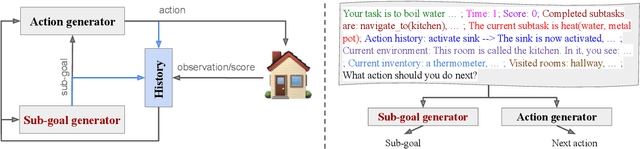

While Large Language Models (LLMs) have demonstrated significant promise as agents in interactive tasks, their substantial computational requirements and restricted number of calls constrain their practical utility, especially in long-horizon interactive tasks such as decision-making or in scenarios involving continuous ongoing tasks. To address these constraints, we propose a method for transferring the performance of an LLM with billions of parameters to a much smaller language model (770M parameters). Our approach involves constructing a hierarchical agent comprising a planning module, which learns through Knowledge Distillation from an LLM to generate sub-goals, and an execution module, which learns to accomplish these sub-goals using elementary actions. In detail, we leverage an LLM to annotate an oracle path with a sequence of sub-goals towards completing a goal. Subsequently, we utilize this annotated data to fine-tune both the planning and execution modules. Importantly, neither module relies on real-time access to an LLM during inference, significantly reducing the overall cost associated with LLM interactions to a fixed cost. In ScienceWorld, a challenging and multi-task interactive text environment, our method surpasses standard imitation learning based solely on elementary actions by 16.7% (absolute). Our analysis highlights the efficiency of our approach compared to other LLM-based methods. Our code and annotated data for distillation can be found on GitHub.
From Language to Language-ish: How Brain-Like is an LSTM's Representation of Nonsensical Language Stimuli?
Oct 14, 2020



The representations generated by many models of language (word embeddings, recurrent neural networks and transformers) correlate to brain activity recorded while people read. However, these decoding results are usually based on the brain's reaction to syntactically and semantically sound language stimuli. In this study, we asked: how does an LSTM (long short term memory) language model, trained (by and large) on semantically and syntactically intact language, represent a language sample with degraded semantic or syntactic information? Does the LSTM representation still resemble the brain's reaction? We found that, even for some kinds of nonsensical language, there is a statistically significant relationship between the brain's activity and the representations of an LSTM. This indicates that, at least in some instances, LSTMs and the human brain handle nonsensical data similarly.
Exploiting generalization in the subspaces for faster model-based learning
Oct 25, 2017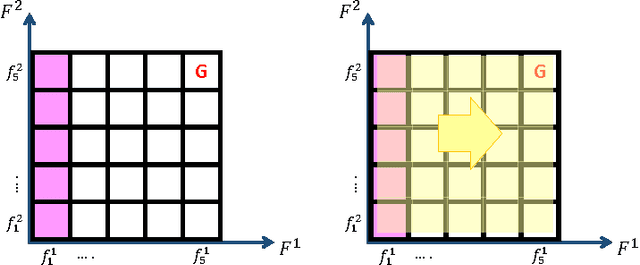
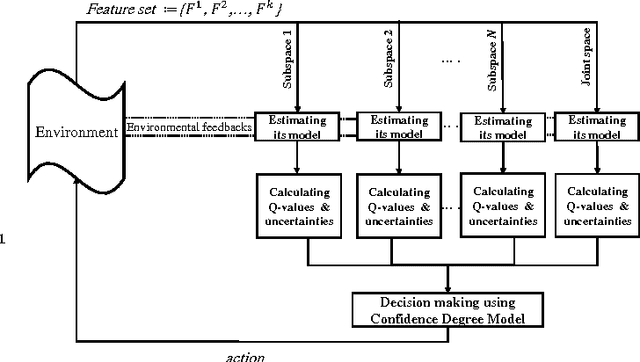
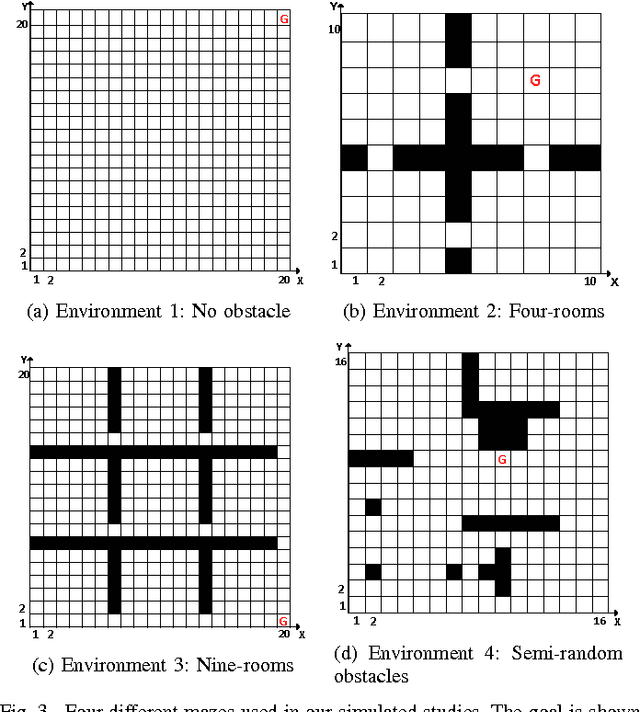
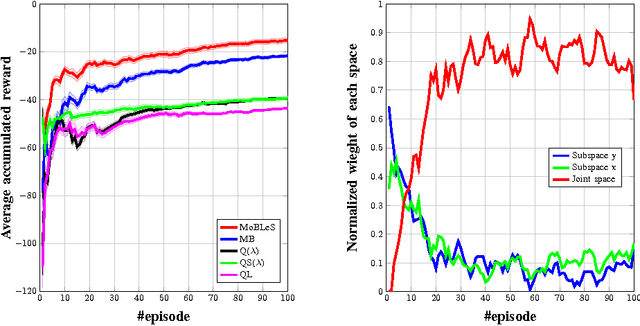
Due to the lack of enough generalization in the state-space, common methods in Reinforcement Learning (RL) suffer from slow learning speed especially in the early learning trials. This paper introduces a model-based method in discrete state-spaces for increasing learning speed in terms of required experience (but not required computational time) by exploiting generalization in the experiences of the subspaces. A subspace is formed by choosing a subset of features in the original state representation (full-space). Generalization and faster learning in a subspace are due to many-to-one mapping of experiences from the full-space to each state in the subspace. Nevertheless, due to inherent perceptual aliasing in the subspaces, the policy suggested by each subspace does not generally converge to the optimal policy. Our approach, called Model Based Learning with Subspaces (MoBLeS), calculates confidence intervals of the estimated Q-values in the full-space and in the subspaces. These confidence intervals are used in the decision making, such that the agent benefits the most from the possible generalization while avoiding from detriment of the perceptual aliasing in the subspaces. Convergence of MoBLeS to the optimal policy is theoretically investigated. Additionally, we show through several experiments that MoBLeS improves the learning speed in the early trials.