 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSub-goal Distillation: A Method to Improve Small Language Agents
Paper and Code

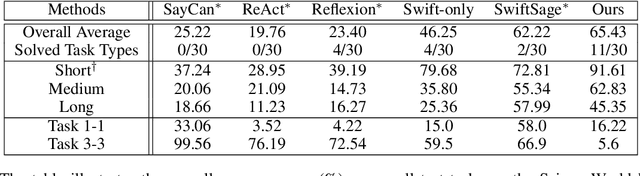
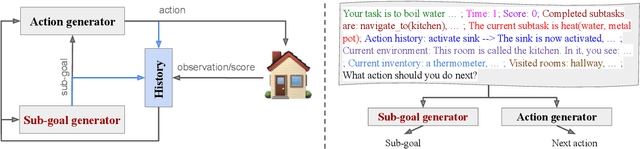

While Large Language Models (LLMs) have demonstrated significant promise as agents in interactive tasks, their substantial computational requirements and restricted number of calls constrain their practical utility, especially in long-horizon interactive tasks such as decision-making or in scenarios involving continuous ongoing tasks. To address these constraints, we propose a method for transferring the performance of an LLM with billions of parameters to a much smaller language model (770M parameters). Our approach involves constructing a hierarchical agent comprising a planning module, which learns through Knowledge Distillation from an LLM to generate sub-goals, and an execution module, which learns to accomplish these sub-goals using elementary actions. In detail, we leverage an LLM to annotate an oracle path with a sequence of sub-goals towards completing a goal. Subsequently, we utilize this annotated data to fine-tune both the planning and execution modules. Importantly, neither module relies on real-time access to an LLM during inference, significantly reducing the overall cost associated with LLM interactions to a fixed cost. In ScienceWorld, a challenging and multi-task interactive text environment, our method surpasses standard imitation learning based solely on elementary actions by 16.7% (absolute). Our analysis highlights the efficiency of our approach compared to other LLM-based methods. Our code and annotated data for distillation can be found on GitHub.