 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSub-goal Distillation: A Method to Improve Small Language Agents
May 04, 2024
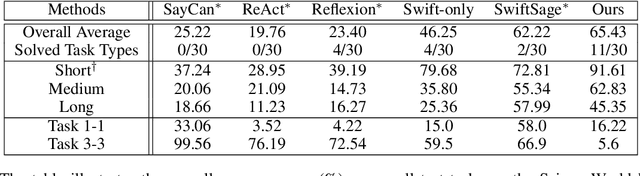
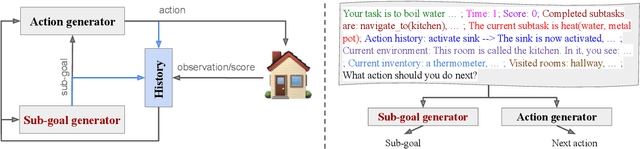

While Large Language Models (LLMs) have demonstrated significant promise as agents in interactive tasks, their substantial computational requirements and restricted number of calls constrain their practical utility, especially in long-horizon interactive tasks such as decision-making or in scenarios involving continuous ongoing tasks. To address these constraints, we propose a method for transferring the performance of an LLM with billions of parameters to a much smaller language model (770M parameters). Our approach involves constructing a hierarchical agent comprising a planning module, which learns through Knowledge Distillation from an LLM to generate sub-goals, and an execution module, which learns to accomplish these sub-goals using elementary actions. In detail, we leverage an LLM to annotate an oracle path with a sequence of sub-goals towards completing a goal. Subsequently, we utilize this annotated data to fine-tune both the planning and execution modules. Importantly, neither module relies on real-time access to an LLM during inference, significantly reducing the overall cost associated with LLM interactions to a fixed cost. In ScienceWorld, a challenging and multi-task interactive text environment, our method surpasses standard imitation learning based solely on elementary actions by 16.7% (absolute). Our analysis highlights the efficiency of our approach compared to other LLM-based methods. Our code and annotated data for distillation can be found on GitHub.
Building Dynamic Knowledge Graphs from Text-based Games
Oct 22, 2019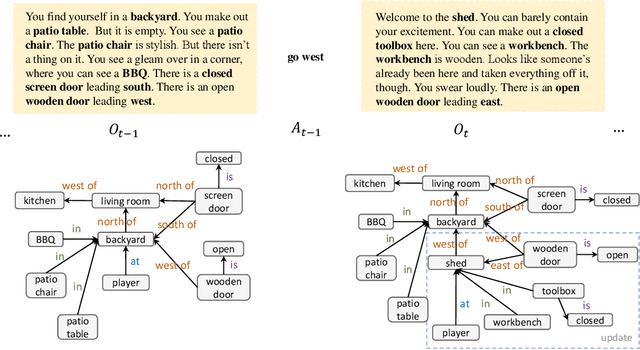

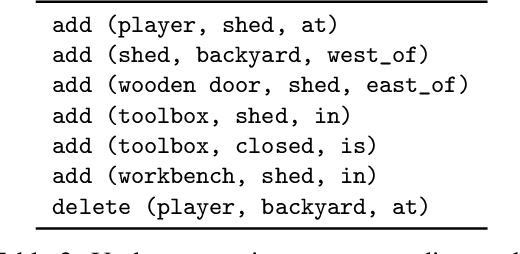
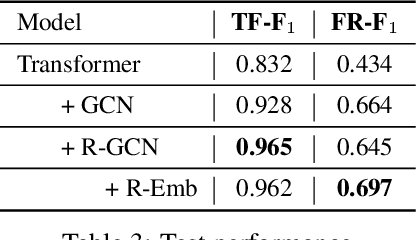
We are interested in learning how to update Knowledge Graphs (KG) from text. In this preliminary work, we propose a novel Sequence-to-Sequence (Seq2Seq) architecture to generate elementary KG operations. Furthermore, we introduce a new dataset for KG extraction built upon text-based game transitions (over 300k data points). We conduct experiments and discuss the results.
Interactive Machine Comprehension with Information Seeking Agents
Sep 04, 2019
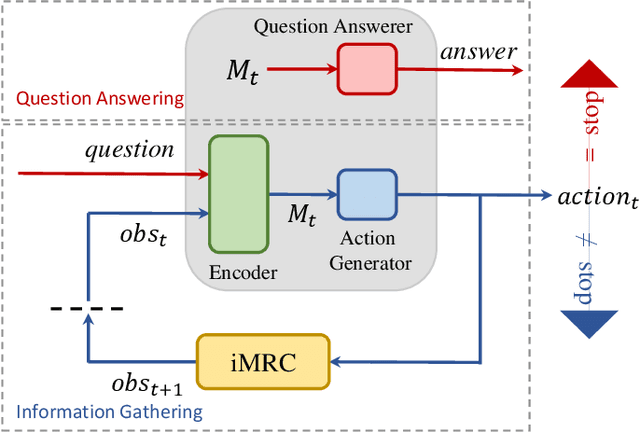
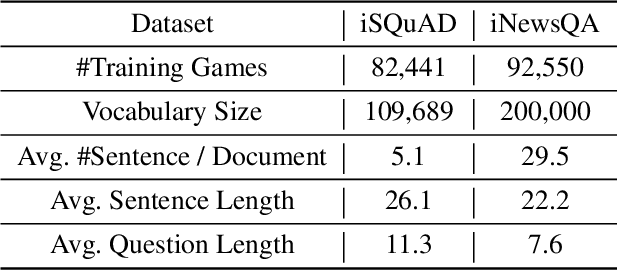
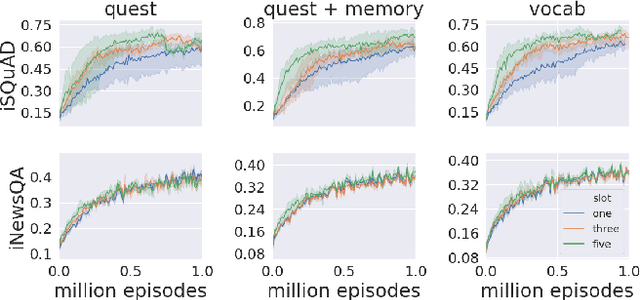
Existing machine reading comprehension (MRC) models do not scale effectively to real-world applications like web-level information retrieval and question answering (QA). We argue that this stems from the nature of MRC datasets: most of these are static environments wherein the supporting documents and all necessary information are fully observed. In this paper, we propose a simple method that reframes existing MRC datasets as interactive, partially observable environments. Specifically, we "occlude" the majority of a document's text and add context-sensitive commands that reveal "glimpses" of the hidden text to a model. We repurpose SQuAD and NewsQA as an initial case study, and then show how the interactive corpora can be used to train a model that seeks relevant information through sequential decision making. We believe that this setting can contribute in scaling models to web-level QA scenarios.
Interactive Language Learning by Question Answering
Aug 28, 2019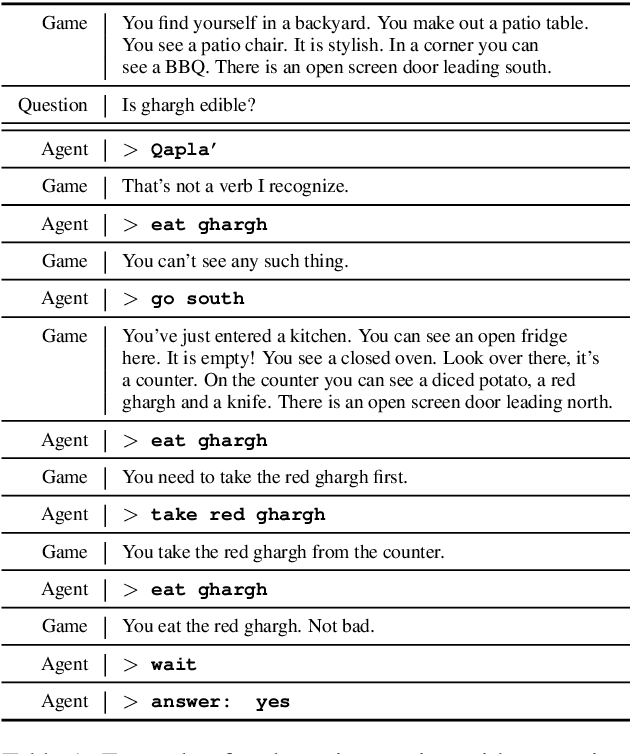
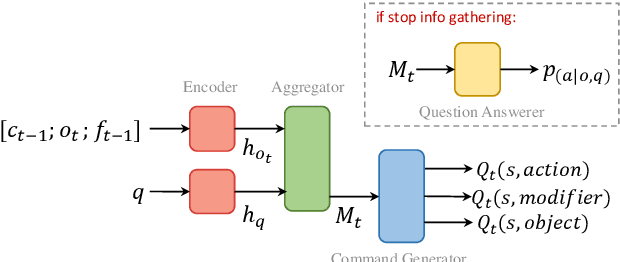
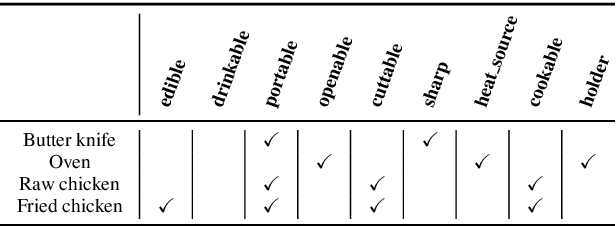
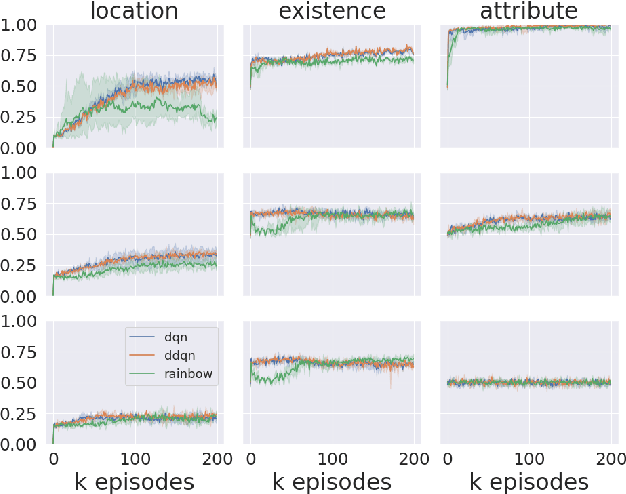
Humans observe and interact with the world to acquire knowledge. However, most existing machine reading comprehension (MRC) tasks miss the interactive, information-seeking component of comprehension. Such tasks present models with static documents that contain all necessary information, usually concentrated in a single short substring. Thus, models can achieve strong performance through simple word- and phrase-based pattern matching. We address this problem by formulating a novel text-based question answering task: Question Answering with Interactive Text (QAit). In QAit, an agent must interact with a partially observable text-based environment to gather information required to answer questions. QAit poses questions about the existence, location, and attributes of objects found in the environment. The data is built using a text-based game generator that defines the underlying dynamics of interaction with the environment. We propose and evaluate a set of baseline models for the QAit task that includes deep reinforcement learning agents. Experiments show that the task presents a major challenge for machine reading systems, while humans solve it with relative ease.