 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting generalization in the subspaces for faster model-based learning
Paper and Code
Oct 25, 2017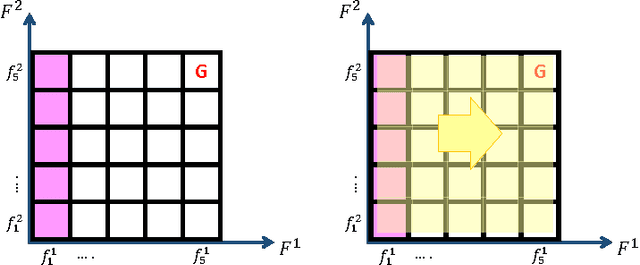
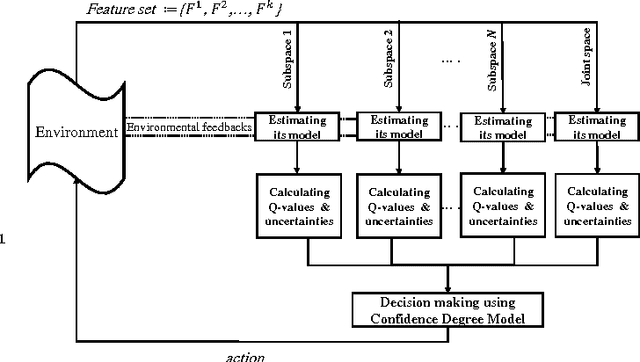
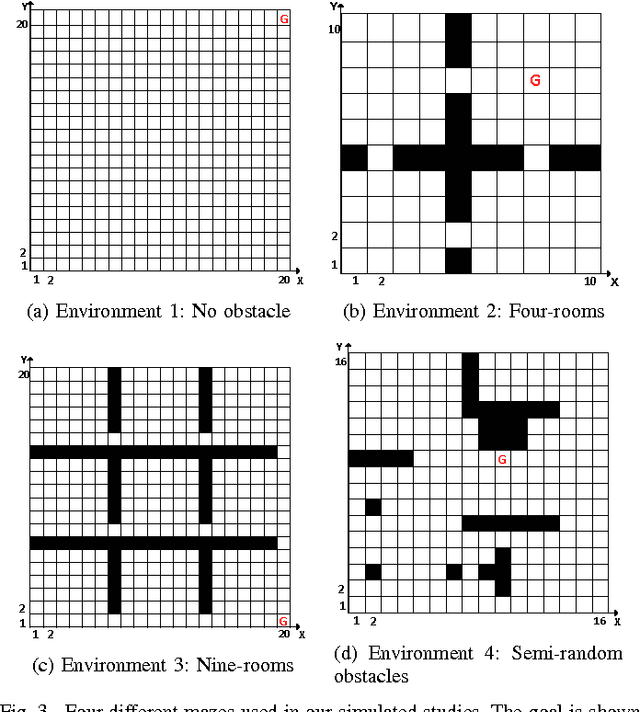
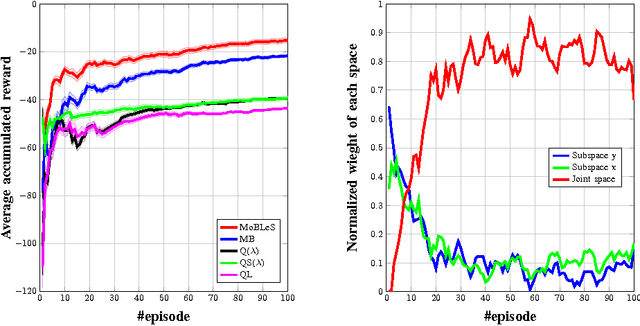
Due to the lack of enough generalization in the state-space, common methods in Reinforcement Learning (RL) suffer from slow learning speed especially in the early learning trials. This paper introduces a model-based method in discrete state-spaces for increasing learning speed in terms of required experience (but not required computational time) by exploiting generalization in the experiences of the subspaces. A subspace is formed by choosing a subset of features in the original state representation (full-space). Generalization and faster learning in a subspace are due to many-to-one mapping of experiences from the full-space to each state in the subspace. Nevertheless, due to inherent perceptual aliasing in the subspaces, the policy suggested by each subspace does not generally converge to the optimal policy. Our approach, called Model Based Learning with Subspaces (MoBLeS), calculates confidence intervals of the estimated Q-values in the full-space and in the subspaces. These confidence intervals are used in the decision making, such that the agent benefits the most from the possible generalization while avoiding from detriment of the perceptual aliasing in the subspaces. Convergence of MoBLeS to the optimal policy is theoretically investigated. Additionally, we show through several experiments that MoBLeS improves the learning speed in the early trials.