 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedHELM: Holistic Evaluation of Large Language Models for Medical Tasks
May 26, 2025



While large language models (LLMs) achieve near-perfect scores on medical licensing exams, these evaluations inadequately reflect the complexity and diversity of real-world clinical practice. We introduce MedHELM, an extensible evaluation framework for assessing LLM performance for medical tasks with three key contributions. First, a clinician-validated taxonomy spanning 5 categories, 22 subcategories, and 121 tasks developed with 29 clinicians. Second, a comprehensive benchmark suite comprising 35 benchmarks (17 existing, 18 newly formulated) providing complete coverage of all categories and subcategories in the taxonomy. Third, a systematic comparison of LLMs with improved evaluation methods (using an LLM-jury) and a cost-performance analysis. Evaluation of 9 frontier LLMs, using the 35 benchmarks, revealed significant performance variation. Advanced reasoning models (DeepSeek R1: 66% win-rate; o3-mini: 64% win-rate) demonstrated superior performance, though Claude 3.5 Sonnet achieved comparable results at 40% lower estimated computational cost. On a normalized accuracy scale (0-1), most models performed strongly in Clinical Note Generation (0.73-0.85) and Patient Communication & Education (0.78-0.83), moderately in Medical Research Assistance (0.65-0.75), and generally lower in Clinical Decision Support (0.56-0.72) and Administration & Workflow (0.53-0.63). Our LLM-jury evaluation method achieved good agreement with clinician ratings (ICC = 0.47), surpassing both average clinician-clinician agreement (ICC = 0.43) and automated baselines including ROUGE-L (0.36) and BERTScore-F1 (0.44). Claude 3.5 Sonnet achieved comparable performance to top models at lower estimated cost. These findings highlight the importance of real-world, task-specific evaluation for medical use of LLMs and provides an open source framework to enable this.
VeriFact: Verifying Facts in LLM-Generated Clinical Text with Electronic Health Records
Jan 28, 2025Methods to ensure factual accuracy of text generated by large language models (LLM) in clinical medicine are lacking. VeriFact is an artificial intelligence system that combines retrieval-augmented generation and LLM-as-a-Judge to verify whether LLM-generated text is factually supported by a patient's medical history based on their electronic health record (EHR). To evaluate this system, we introduce VeriFact-BHC, a new dataset that decomposes Brief Hospital Course narratives from discharge summaries into a set of simple statements with clinician annotations for whether each statement is supported by the patient's EHR clinical notes. Whereas highest agreement between clinicians was 88.5%, VeriFact achieves up to 92.7% agreement when compared to a denoised and adjudicated average human clinican ground truth, suggesting that VeriFact exceeds the average clinician's ability to fact-check text against a patient's medical record. VeriFact may accelerate the development of LLM-based EHR applications by removing current evaluation bottlenecks.
Assessing the Limitations of Large Language Models in Clinical Fact Decomposition
Dec 17, 2024Verifying factual claims is critical for using large language models (LLMs) in healthcare. Recent work has proposed fact decomposition, which uses LLMs to rewrite source text into concise sentences conveying a single piece of information, as an approach for fine-grained fact verification. Clinical documentation poses unique challenges for fact decomposition due to dense terminology and diverse note types. To explore these challenges, we present FactEHR, a dataset consisting of full document fact decompositions for 2,168 clinical notes spanning four types from three hospital systems. Our evaluation, including review by clinicians, highlights significant variability in the quality of fact decomposition for four commonly used LLMs, with some LLMs generating 2.6x more facts per sentence than others. The results underscore the need for better LLM capabilities to support factual verification in clinical text. To facilitate future research in this direction, we plan to release our code at \url{https://github.com/som-shahlab/factehr}.
Evaluation of GPT-3.5 and GPT-4 for supporting real-world information needs in healthcare delivery
May 01, 2023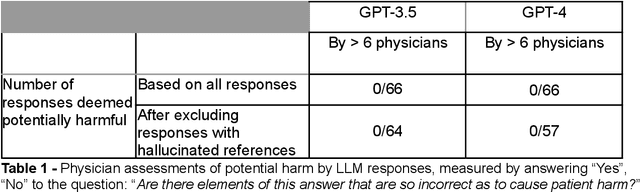
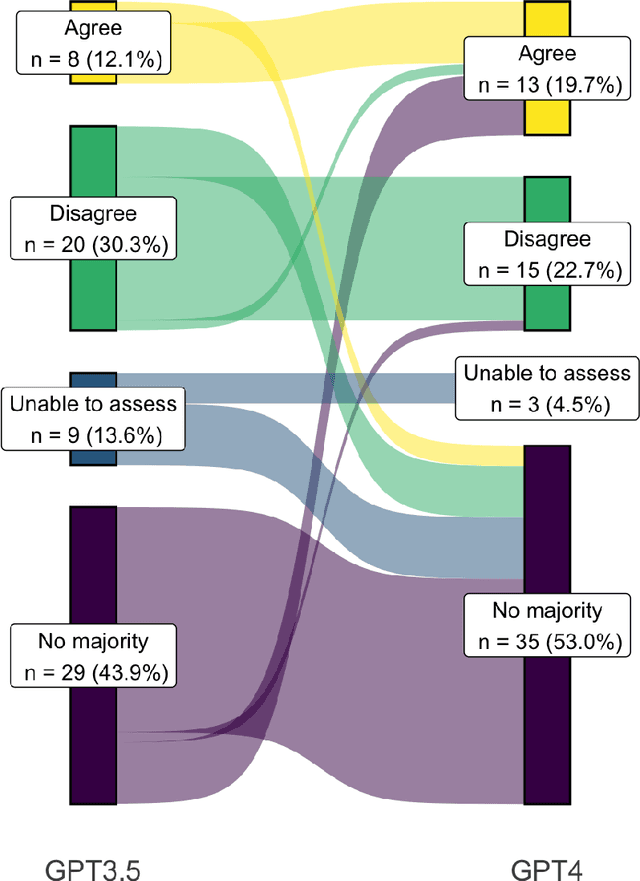
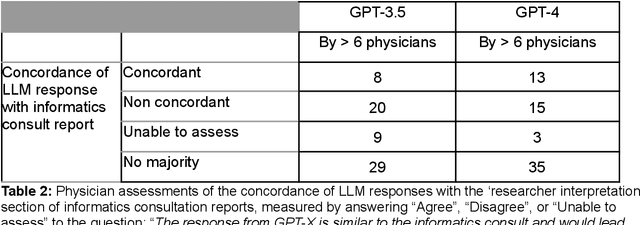
Despite growing interest in using large language models (LLMs) in healthcare, current explorations do not assess the real-world utility and safety of LLMs in clinical settings. Our objective was to determine whether two LLMs can serve information needs submitted by physicians as questions to an informatics consultation service in a safe and concordant manner. Sixty six questions from an informatics consult service were submitted to GPT-3.5 and GPT-4 via simple prompts. 12 physicians assessed the LLM responses' possibility of patient harm and concordance with existing reports from an informatics consultation service. Physician assessments were summarized based on majority vote. For no questions did a majority of physicians deem either LLM response as harmful. For GPT-3.5, responses to 8 questions were concordant with the informatics consult report, 20 discordant, and 9 were unable to be assessed. There were 29 responses with no majority on "Agree", "Disagree", and "Unable to assess". For GPT-4, responses to 13 questions were concordant, 15 discordant, and 3 were unable to be assessed. There were 35 responses with no majority. Responses from both LLMs were largely devoid of overt harm, but less than 20% of the responses agreed with an answer from an informatics consultation service, responses contained hallucinated references, and physicians were divided on what constitutes harm. These results suggest that while general purpose LLMs are able to provide safe and credible responses, they often do not meet the specific information need of a given question. A definitive evaluation of the usefulness of LLMs in healthcare settings will likely require additional research on prompt engineering, calibration, and custom-tailoring of general purpose models.
Givenness Hierarchy Theoretic Cognitive Status Filtering
May 22, 2020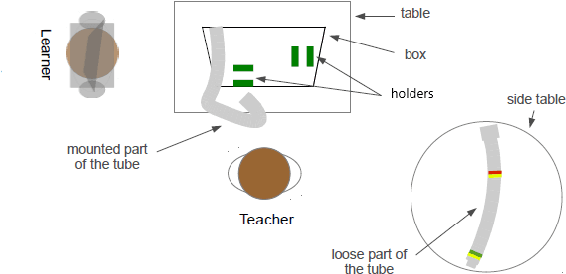
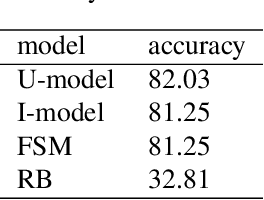
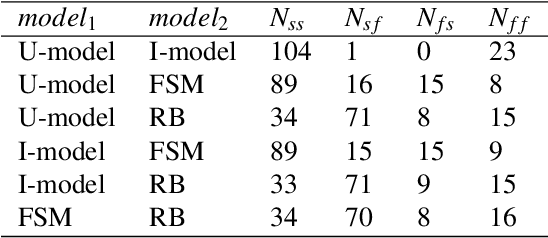
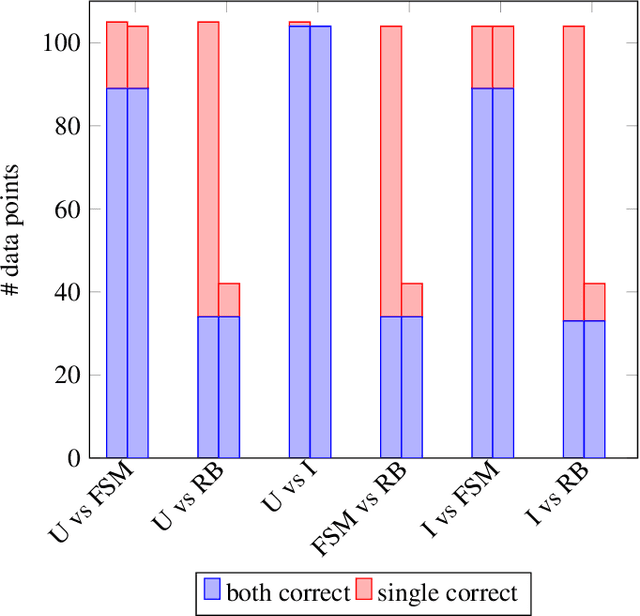
For language-capable interactive robots to be effectively introduced into human society, they must be able to naturally and efficiently communicate about the objects, locations, and people found in human environments. An important aspect of natural language communication is the use of pronouns. Ac-cording to the linguistic theory of the Givenness Hierarchy(GH), humans use pronouns due to implicit assumptions about the cognitive statuses their referents have in the minds of their conversational partners. In previous work, Williams et al. presented the first computational implementation of the full GH for the purpose of robot language understanding, leveraging a set of rules informed by the GH literature. However, that approach was designed specifically for language understanding,oriented around GH-inspired memory structures used to assess what entities are candidate referents given a particular cognitive status. In contrast, language generation requires a model in which cognitive status can be assessed for a given entity. We present and compare two such models of cognitive status: a rule-based Finite State Machine model directly informed by the GH literature and a Cognitive Status Filter designed to more flexibly handle uncertainty. The models are demonstrated and evaluated using a silver-standard English subset of the OFAI Multimodal Task Description Corpus.