 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedHELM: Holistic Evaluation of Large Language Models for Medical Tasks
May 26, 2025



While large language models (LLMs) achieve near-perfect scores on medical licensing exams, these evaluations inadequately reflect the complexity and diversity of real-world clinical practice. We introduce MedHELM, an extensible evaluation framework for assessing LLM performance for medical tasks with three key contributions. First, a clinician-validated taxonomy spanning 5 categories, 22 subcategories, and 121 tasks developed with 29 clinicians. Second, a comprehensive benchmark suite comprising 35 benchmarks (17 existing, 18 newly formulated) providing complete coverage of all categories and subcategories in the taxonomy. Third, a systematic comparison of LLMs with improved evaluation methods (using an LLM-jury) and a cost-performance analysis. Evaluation of 9 frontier LLMs, using the 35 benchmarks, revealed significant performance variation. Advanced reasoning models (DeepSeek R1: 66% win-rate; o3-mini: 64% win-rate) demonstrated superior performance, though Claude 3.5 Sonnet achieved comparable results at 40% lower estimated computational cost. On a normalized accuracy scale (0-1), most models performed strongly in Clinical Note Generation (0.73-0.85) and Patient Communication & Education (0.78-0.83), moderately in Medical Research Assistance (0.65-0.75), and generally lower in Clinical Decision Support (0.56-0.72) and Administration & Workflow (0.53-0.63). Our LLM-jury evaluation method achieved good agreement with clinician ratings (ICC = 0.47), surpassing both average clinician-clinician agreement (ICC = 0.43) and automated baselines including ROUGE-L (0.36) and BERTScore-F1 (0.44). Claude 3.5 Sonnet achieved comparable performance to top models at lower estimated cost. These findings highlight the importance of real-world, task-specific evaluation for medical use of LLMs and provides an open source framework to enable this.
Assessing the Limitations of Large Language Models in Clinical Fact Decomposition
Dec 17, 2024Verifying factual claims is critical for using large language models (LLMs) in healthcare. Recent work has proposed fact decomposition, which uses LLMs to rewrite source text into concise sentences conveying a single piece of information, as an approach for fine-grained fact verification. Clinical documentation poses unique challenges for fact decomposition due to dense terminology and diverse note types. To explore these challenges, we present FactEHR, a dataset consisting of full document fact decompositions for 2,168 clinical notes spanning four types from three hospital systems. Our evaluation, including review by clinicians, highlights significant variability in the quality of fact decomposition for four commonly used LLMs, with some LLMs generating 2.6x more facts per sentence than others. The results underscore the need for better LLM capabilities to support factual verification in clinical text. To facilitate future research in this direction, we plan to release our code at \url{https://github.com/som-shahlab/factehr}.
Zero-Shot Clinical Trial Patient Matching with LLMs
Feb 05, 2024
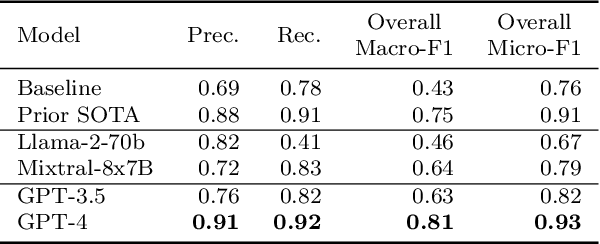
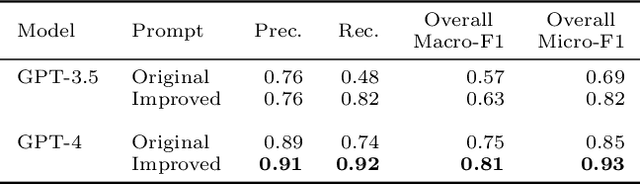

Matching patients to clinical trials is a key unsolved challenge in bringing new drugs to market. Today, identifying patients who meet a trial's eligibility criteria is highly manual, taking up to 1 hour per patient. Automated screening is challenging, however, as it requires understanding unstructured clinical text. Large language models (LLMs) offer a promising solution. In this work, we explore their application to trial matching. First, we design an LLM-based system which, given a patient's medical history as unstructured clinical text, evaluates whether that patient meets a set of inclusion criteria (also specified as free text). Our zero-shot system achieves state-of-the-art scores on the n2c2 2018 cohort selection benchmark. Second, we improve the data and cost efficiency of our method by identifying a prompting strategy which matches patients an order of magnitude faster and more cheaply than the status quo, and develop a two-stage retrieval pipeline that reduces the number of tokens processed by up to a third while retaining high performance. Third, we evaluate the interpretability of our system by having clinicians evaluate the natural language justifications generated by the LLM for each eligibility decision, and show that it can output coherent explanations for 97% of its correct decisions and 75% of its incorrect ones. Our results establish the feasibility of using LLMs to accelerate clinical trial operations.