 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonitoring Deployed AI Systems in Health Care
Dec 09, 2025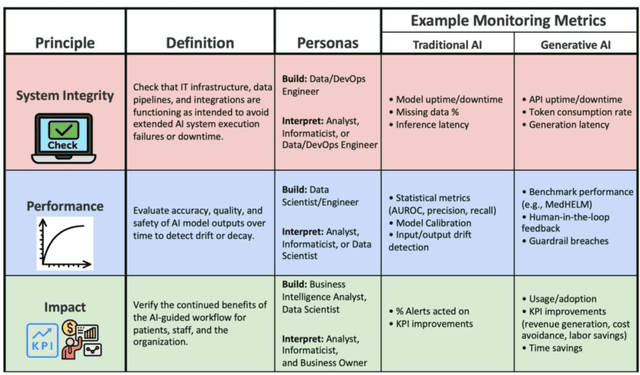
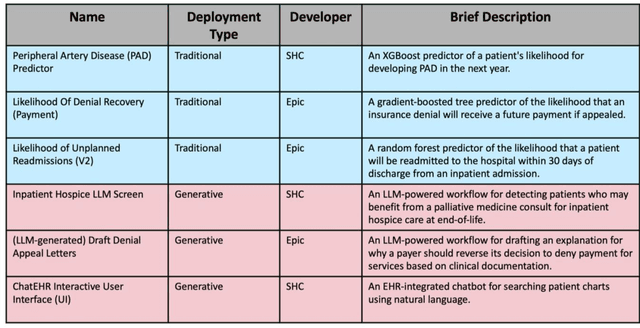
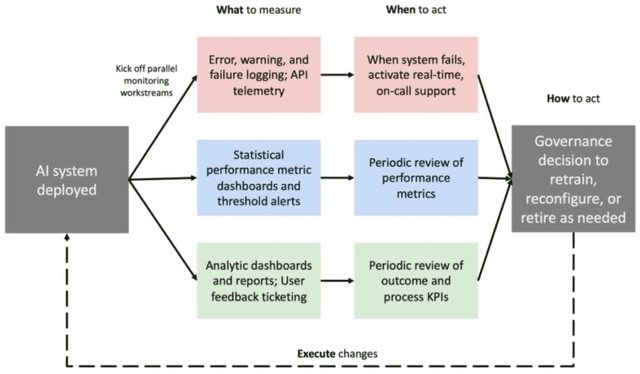
Post-deployment monitoring of artificial intelligence (AI) systems in health care is essential to ensure their safety, quality, and sustained benefit-and to support governance decisions about which systems to update, modify, or decommission. Motivated by these needs, we developed a framework for monitoring deployed AI systems grounded in the mandate to take specific actions when they fail to behave as intended. This framework, which is now actively used at Stanford Health Care, is organized around three complementary principles: system integrity, performance, and impact. System integrity monitoring focuses on maximizing system uptime, detecting runtime errors, and identifying when changes to the surrounding IT ecosystem have unintended effects. Performance monitoring focuses on maintaining accurate system behavior in the face of changing health care practices (and thus input data) over time. Impact monitoring assesses whether a deployed system continues to have value in the form of benefit to clinicians and patients. Drawing on examples of deployed AI systems at our academic medical center, we provide practical guidance for creating monitoring plans based on these principles that specify which metrics to measure, when those metrics should be reviewed, who is responsible for acting when metrics change, and what concrete follow-up actions should be taken-for both traditional and generative AI. We also discuss challenges to implementing this framework, including the effort and cost of monitoring for health systems with limited resources and the difficulty of incorporating data-driven monitoring practices into complex organizations where conflicting priorities and definitions of success often coexist. This framework offers a practical template and starting point for health systems seeking to ensure that AI deployments remain safe and effective over time.
MedHELM: Holistic Evaluation of Large Language Models for Medical Tasks
May 26, 2025



While large language models (LLMs) achieve near-perfect scores on medical licensing exams, these evaluations inadequately reflect the complexity and diversity of real-world clinical practice. We introduce MedHELM, an extensible evaluation framework for assessing LLM performance for medical tasks with three key contributions. First, a clinician-validated taxonomy spanning 5 categories, 22 subcategories, and 121 tasks developed with 29 clinicians. Second, a comprehensive benchmark suite comprising 35 benchmarks (17 existing, 18 newly formulated) providing complete coverage of all categories and subcategories in the taxonomy. Third, a systematic comparison of LLMs with improved evaluation methods (using an LLM-jury) and a cost-performance analysis. Evaluation of 9 frontier LLMs, using the 35 benchmarks, revealed significant performance variation. Advanced reasoning models (DeepSeek R1: 66% win-rate; o3-mini: 64% win-rate) demonstrated superior performance, though Claude 3.5 Sonnet achieved comparable results at 40% lower estimated computational cost. On a normalized accuracy scale (0-1), most models performed strongly in Clinical Note Generation (0.73-0.85) and Patient Communication & Education (0.78-0.83), moderately in Medical Research Assistance (0.65-0.75), and generally lower in Clinical Decision Support (0.56-0.72) and Administration & Workflow (0.53-0.63). Our LLM-jury evaluation method achieved good agreement with clinician ratings (ICC = 0.47), surpassing both average clinician-clinician agreement (ICC = 0.43) and automated baselines including ROUGE-L (0.36) and BERTScore-F1 (0.44). Claude 3.5 Sonnet achieved comparable performance to top models at lower estimated cost. These findings highlight the importance of real-world, task-specific evaluation for medical use of LLMs and provides an open source framework to enable this.
VeriFact: Verifying Facts in LLM-Generated Clinical Text with Electronic Health Records
Jan 28, 2025Methods to ensure factual accuracy of text generated by large language models (LLM) in clinical medicine are lacking. VeriFact is an artificial intelligence system that combines retrieval-augmented generation and LLM-as-a-Judge to verify whether LLM-generated text is factually supported by a patient's medical history based on their electronic health record (EHR). To evaluate this system, we introduce VeriFact-BHC, a new dataset that decomposes Brief Hospital Course narratives from discharge summaries into a set of simple statements with clinician annotations for whether each statement is supported by the patient's EHR clinical notes. Whereas highest agreement between clinicians was 88.5%, VeriFact achieves up to 92.7% agreement when compared to a denoised and adjudicated average human clinican ground truth, suggesting that VeriFact exceeds the average clinician's ability to fact-check text against a patient's medical record. VeriFact may accelerate the development of LLM-based EHR applications by removing current evaluation bottlenecks.
Zero-Shot Clinical Trial Patient Matching with LLMs
Feb 05, 2024
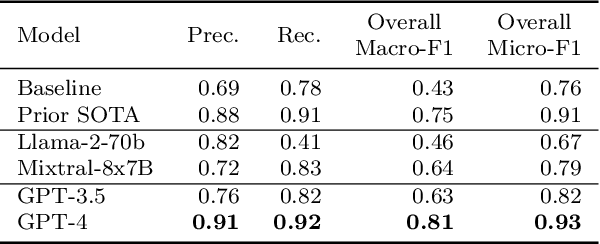
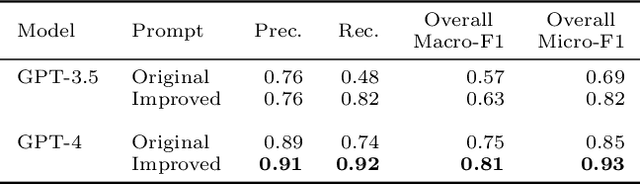

Matching patients to clinical trials is a key unsolved challenge in bringing new drugs to market. Today, identifying patients who meet a trial's eligibility criteria is highly manual, taking up to 1 hour per patient. Automated screening is challenging, however, as it requires understanding unstructured clinical text. Large language models (LLMs) offer a promising solution. In this work, we explore their application to trial matching. First, we design an LLM-based system which, given a patient's medical history as unstructured clinical text, evaluates whether that patient meets a set of inclusion criteria (also specified as free text). Our zero-shot system achieves state-of-the-art scores on the n2c2 2018 cohort selection benchmark. Second, we improve the data and cost efficiency of our method by identifying a prompting strategy which matches patients an order of magnitude faster and more cheaply than the status quo, and develop a two-stage retrieval pipeline that reduces the number of tokens processed by up to a third while retaining high performance. Third, we evaluate the interpretability of our system by having clinicians evaluate the natural language justifications generated by the LLM for each eligibility decision, and show that it can output coherent explanations for 97% of its correct decisions and 75% of its incorrect ones. Our results establish the feasibility of using LLMs to accelerate clinical trial operations.