 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnswering real-world clinical questions using large language model based systems
Jun 29, 2024



Evidence to guide healthcare decisions is often limited by a lack of relevant and trustworthy literature as well as difficulty in contextualizing existing research for a specific patient. Large language models (LLMs) could potentially address both challenges by either summarizing published literature or generating new studies based on real-world data (RWD). We evaluated the ability of five LLM-based systems in answering 50 clinical questions and had nine independent physicians review the responses for relevance, reliability, and actionability. As it stands, general-purpose LLMs (ChatGPT-4, Claude 3 Opus, Gemini Pro 1.5) rarely produced answers that were deemed relevant and evidence-based (2% - 10%). In contrast, retrieval augmented generation (RAG)-based and agentic LLM systems produced relevant and evidence-based answers for 24% (OpenEvidence) to 58% (ChatRWD) of questions. Only the agentic ChatRWD was able to answer novel questions compared to other LLMs (65% vs. 0-9%). These results suggest that while general-purpose LLMs should not be used as-is, a purpose-built system for evidence summarization based on RAG and one for generating novel evidence working synergistically would improve availability of pertinent evidence for patient care.
Evaluation of GPT-3.5 and GPT-4 for supporting real-world information needs in healthcare delivery
May 01, 2023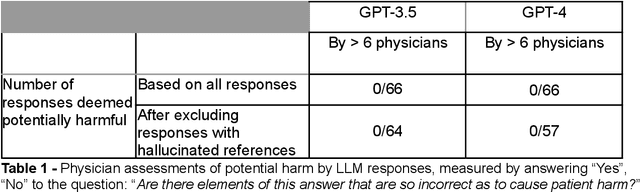
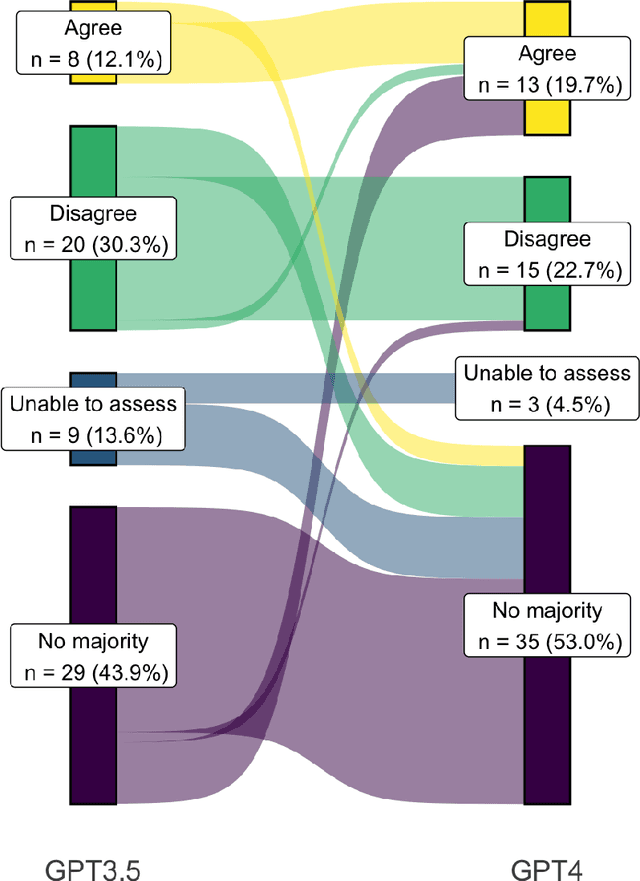
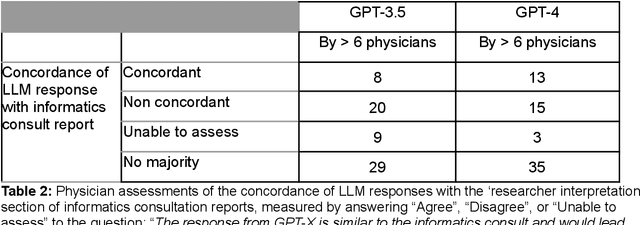
Despite growing interest in using large language models (LLMs) in healthcare, current explorations do not assess the real-world utility and safety of LLMs in clinical settings. Our objective was to determine whether two LLMs can serve information needs submitted by physicians as questions to an informatics consultation service in a safe and concordant manner. Sixty six questions from an informatics consult service were submitted to GPT-3.5 and GPT-4 via simple prompts. 12 physicians assessed the LLM responses' possibility of patient harm and concordance with existing reports from an informatics consultation service. Physician assessments were summarized based on majority vote. For no questions did a majority of physicians deem either LLM response as harmful. For GPT-3.5, responses to 8 questions were concordant with the informatics consult report, 20 discordant, and 9 were unable to be assessed. There were 29 responses with no majority on "Agree", "Disagree", and "Unable to assess". For GPT-4, responses to 13 questions were concordant, 15 discordant, and 3 were unable to be assessed. There were 35 responses with no majority. Responses from both LLMs were largely devoid of overt harm, but less than 20% of the responses agreed with an answer from an informatics consultation service, responses contained hallucinated references, and physicians were divided on what constitutes harm. These results suggest that while general purpose LLMs are able to provide safe and credible responses, they often do not meet the specific information need of a given question. A definitive evaluation of the usefulness of LLMs in healthcare settings will likely require additional research on prompt engineering, calibration, and custom-tailoring of general purpose models.
Missingness as Stability: Understanding the Structure of Missingness in Longitudinal EHR data and its Impact on Reinforcement Learning in Healthcare
Nov 16, 2019

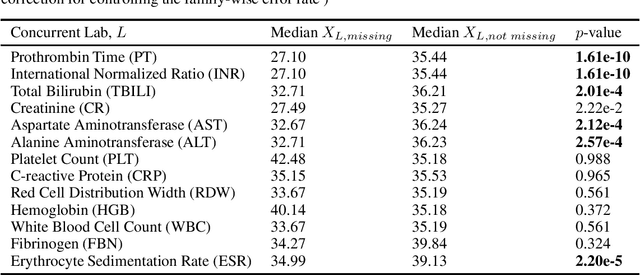
There is an emerging trend in the reinforcement learning for healthcare literature. In order to prepare longitudinal, irregularly sampled, clinical datasets for reinforcement learning algorithms, many researchers will resample the time series data to short, regular intervals and use last-observation-carried-forward (LOCF) imputation to fill in these gaps. Typically, they will not maintain any explicit information about which values were imputed. In this work, we (1) call attention to this practice and discuss its potential implications; (2) propose an alternative representation of the patient state that addresses some of these issues; and (3) demonstrate in a novel but representative clinical dataset that our alternative representation yields consistently better results for achieving optimal control, as measured by off-policy policy evaluation, compared to representations that do not incorporate missingness information.