 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEED: Simple, Efficient, and Effective Data Management via Large Language Models
Oct 01, 2023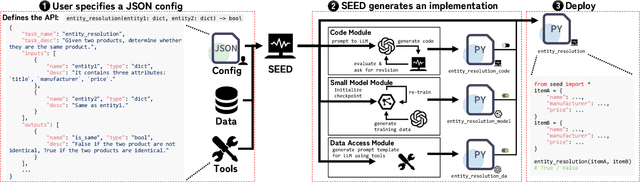
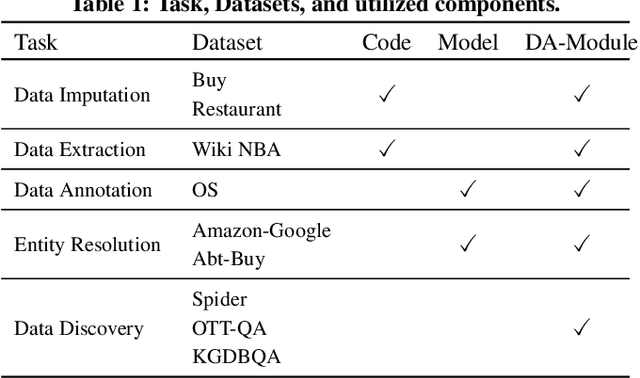
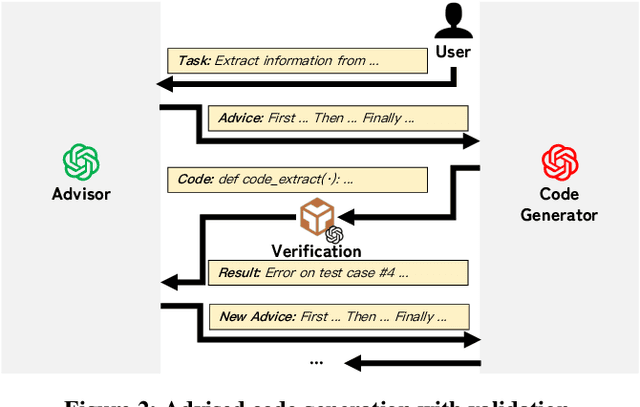
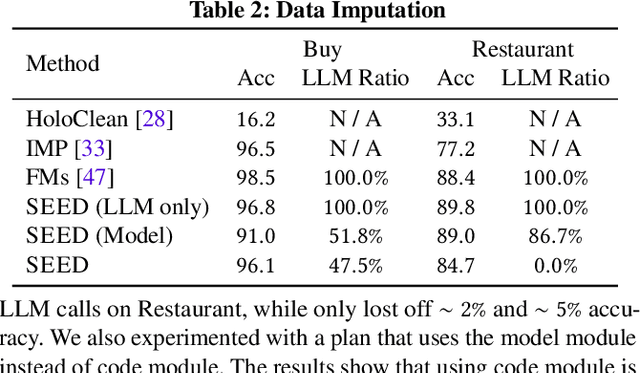
We introduce SEED, an LLM-centric system that allows users to easily create efficient, and effective data management applications. SEED comprises three main components: code generation, model generation, and augmented LLM query to address the challenges that LLM services are computationally and economically expensive and do not always work well on all cases for a given data management task. SEED addresses the expense challenge by localizing LLM computation as much as possible. This includes replacing most of LLM calls with local code, local models, and augmenting LLM queries with batching and data access tools, etc. To ensure effectiveness, SEED features a bunch of optimization techniques to enhance the localized solution and the LLM queries, including automatic code validation, code ensemble, model representatives selection, selective tool usages, etc. Moreover, with SEED users are able to easily construct a data management solution customized to their applications. It allows the users to configure each component and compose an execution pipeline in natural language. SEED then automatically compiles it into an executable program. We showcase the efficiency and effectiveness of SEED using diverse data management tasks such as data imputation, NL2SQL translation, etc., achieving state-of-the-art few-shot performance while significantly reducing the number of required LLM calls.
RoTaR: Efficient Row-Based Table Representation Learning via Teacher-Student Training
Jun 20, 2023We propose RoTaR, a row-based table representation learning method, to address the efficiency and scalability issues faced by existing table representation learning methods. The key idea of RoTaR is to generate query-agnostic row representations that could be re-used via query-specific aggregation. In addition to the row-based architecture, we introduce several techniques: cell-aware position embedding, teacher-student training paradigm, and selective backward to improve the performance of RoTaR model.
Lingua Manga: A Generic Large Language Model Centric System for Data Curation
Jun 20, 2023Data curation is a wide-ranging area which contains many critical but time-consuming data processing tasks. However, the diversity of such tasks makes it challenging to develop a general-purpose data curation system. To address this issue, we present Lingua Manga, a user-friendly and versatile system that utilizes pre-trained large language models. Lingua Manga offers automatic optimization for achieving high performance and label efficiency while facilitating flexible and rapid development. Through three example applications with distinct objectives and users of varying levels of technical proficiency, we demonstrate that Lingua Manga can effectively assist both skilled programmers and low-code or even no-code users in addressing data curation challenges.
Interleaving Pre-Trained Language Models and Large Language Models for Zero-Shot NL2SQL Generation
Jun 15, 2023Zero-shot NL2SQL is crucial in achieving natural language to SQL that is adaptive to new environments (e.g., new databases, new linguistic phenomena or SQL structures) with zero annotated NL2SQL samples from such environments. Existing approaches either fine-tune pre-trained language models (PLMs) based on annotated data or use prompts to guide fixed large language models (LLMs) such as ChatGPT. PLMs can perform well in schema alignment but struggle to achieve complex reasoning, while LLMs is superior in complex reasoning tasks but cannot achieve precise schema alignment. In this paper, we propose a ZeroNL2SQL framework that combines the complementary advantages of PLMs and LLMs for supporting zero-shot NL2SQL. ZeroNL2SQL first uses PLMs to generate an SQL sketch via schema alignment, then uses LLMs to fill the missing information via complex reasoning. Moreover, in order to better align the generated SQL queries with values in the given database instances, we design a predicate calibration method to guide the LLM in completing the SQL sketches based on the database instances and select the optimal SQL query via an execution-based strategy. Comprehensive experiments show that ZeroNL2SQL can achieve the best zero-shot NL2SQL performance on real-world benchmarks. Specifically, ZeroNL2SQL outperforms the state-of-the-art PLM-based methods by 3.2% to 13% and exceeds LLM-based methods by 10% to 20% on execution accuracy.
Self-Supervised Multi-Object Tracking with Cross-Input Consistency
Nov 10, 2021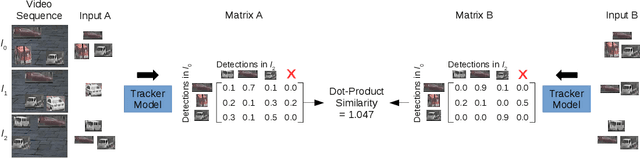
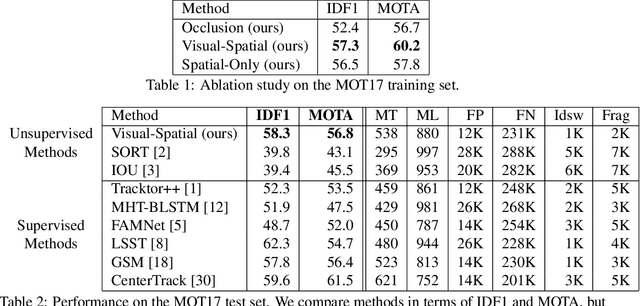
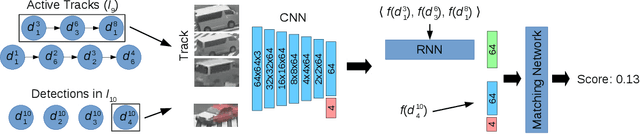
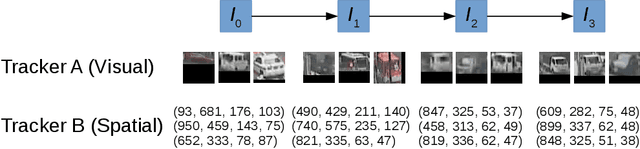
In this paper, we propose a self-supervised learning procedure for training a robust multi-object tracking (MOT) model given only unlabeled video. While several self-supervisory learning signals have been proposed in prior work on single-object tracking, such as color propagation and cycle-consistency, these signals cannot be directly applied for training RNN models, which are needed to achieve accurate MOT: they yield degenerate models that, for instance, always match new detections to tracks with the closest initial detections. We propose a novel self-supervisory signal that we call cross-input consistency: we construct two distinct inputs for the same sequence of video, by hiding different information about the sequence in each input. We then compute tracks in that sequence by applying an RNN model independently on each input, and train the model to produce consistent tracks across the two inputs. We evaluate our unsupervised method on MOT17 and KITTI -- remarkably, we find that, despite training only on unlabeled video, our unsupervised approach outperforms four supervised methods published in the last 1--2 years, including Tracktor++, FAMNet, GSM, and mmMOT.
Updating Street Maps using Changes Detected in Satellite Imagery
Oct 13, 2021
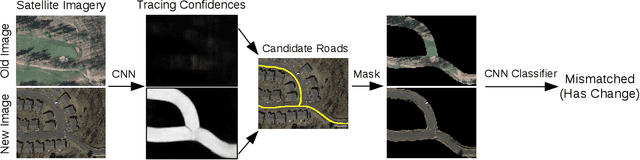


Accurately maintaining digital street maps is labor-intensive. To address this challenge, much work has studied automatically processing geospatial data sources such as GPS trajectories and satellite images to reduce the cost of maintaining digital maps. An end-to-end map update system would first process geospatial data sources to extract insights, and second leverage those insights to update and improve the map. However, prior work largely focuses on the first step of this pipeline: these map extraction methods infer road networks from scratch given geospatial data sources (in effect creating entirely new maps), but do not address the second step of leveraging this extracted information to update the existing digital map data. In this paper, we first explain why current map extraction techniques yield low accuracy when extended to update existing maps. We then propose a novel method that leverages the progression of satellite imagery over time to substantially improve accuracy. Our approach first compares satellite images captured at different times to identify portions of the physical road network that have visibly changed, and then updates the existing map accordingly. We show that our change-based approach reduces map update error rates four-fold.
Beyond Road Extraction: A Dataset for Map Update using Aerial Images
Oct 10, 2021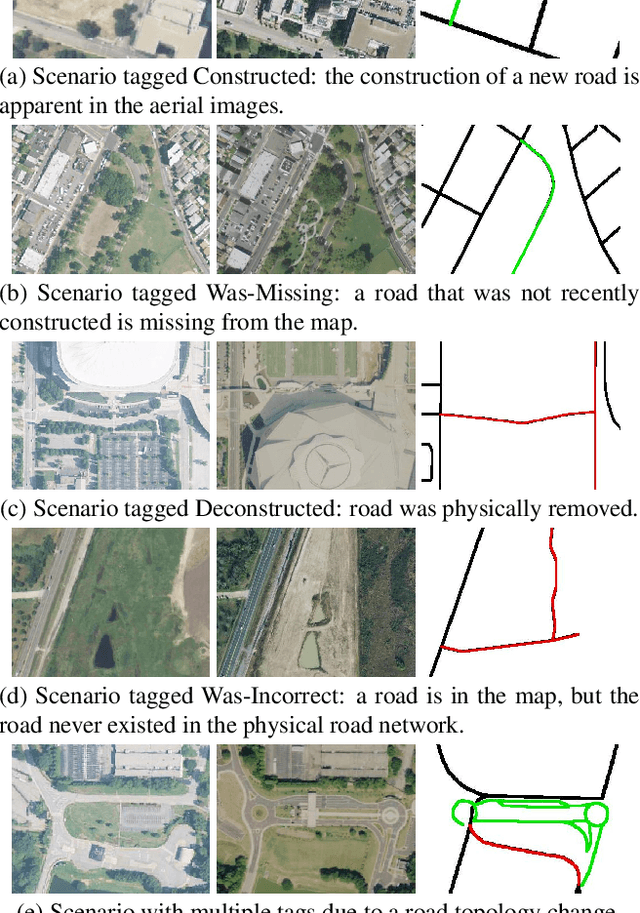
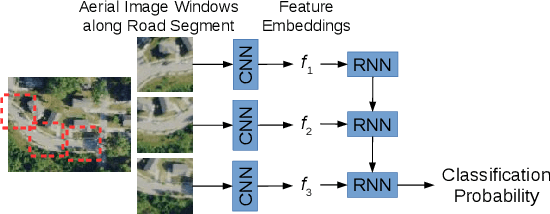
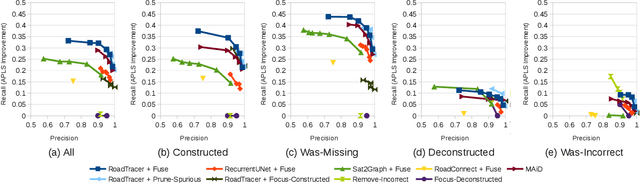
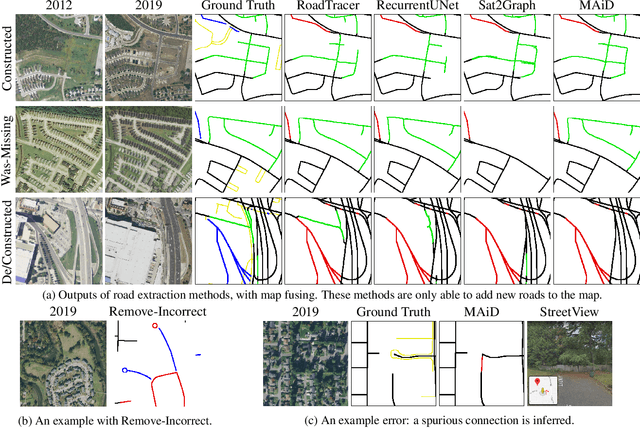
The increasing availability of satellite and aerial imagery has sparked substantial interest in automatically updating street maps by processing aerial images. Until now, the community has largely focused on road extraction, where road networks are inferred from scratch from an aerial image. However, given that relatively high-quality maps exist in most parts of the world, in practice, inference approaches must be applied to update existing maps rather than infer new ones. With recent road extraction methods showing high accuracy, we argue that it is time to transition to the more practical map update task, where an existing map is updated by adding, removing, and shifting roads, without introducing errors in parts of the existing map that remain up-to-date. In this paper, we develop a new dataset called MUNO21 for the map update task, and show that it poses several new and interesting research challenges. We evaluate several state-of-the-art road extraction methods on MUNO21, and find that substantial further improvements in accuracy will be needed to realize automatic map update.
TagMe: GPS-Assisted Automatic Object Annotation in Videos
Mar 24, 2021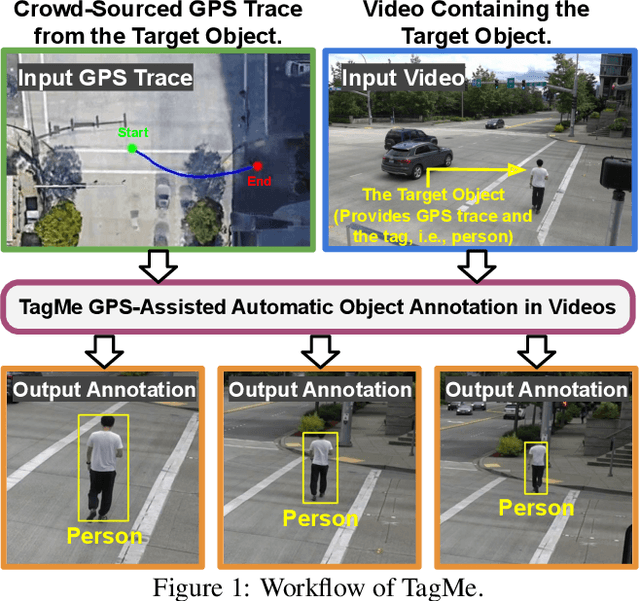
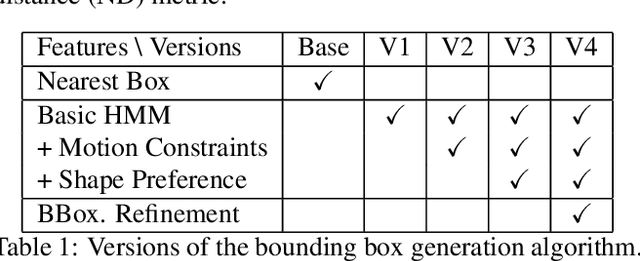

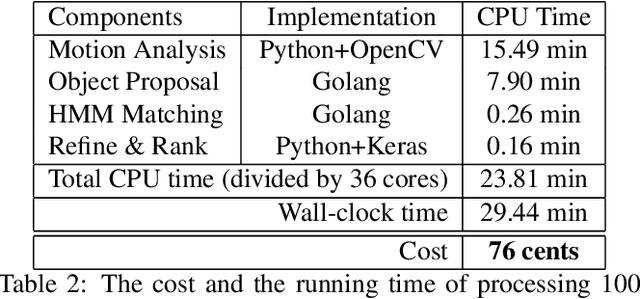
Training high-accuracy object detection models requires large and diverse annotated datasets. However, creating these data-sets is time-consuming and expensive since it relies on human annotators. We design, implement, and evaluate TagMe, a new approach for automatic object annotation in videos that uses GPS data. When the GPS trace of an object is available, TagMe matches the object's motion from GPS trace and the pixels' motions in the video to find the pixels belonging to the object in the video and creates the bounding box annotations of the object. TagMe works using passive data collection and can continuously generate new object annotations from outdoor video streams without any human annotators. We evaluate TagMe on a dataset of 100 video clips. We show TagMe can produce high-quality object annotations in a fully-automatic and low-cost way. Compared with the traditional human-in-the-loop solution, TagMe can produce the same amount of annotations at a much lower cost, e.g., up to 110x.
Relational Pretrained Transformers towards Democratizing Data Preparation [Vision]
Dec 04, 2020![Figure 1 for Relational Pretrained Transformers towards Democratizing Data Preparation [Vision]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fd51bec1426494f23de57b2c4184c7e26583eda53%2F1-Figure1-1.png&w=640&q=75)
![Figure 2 for Relational Pretrained Transformers towards Democratizing Data Preparation [Vision]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fd51bec1426494f23de57b2c4184c7e26583eda53%2F4-Table1-1.png&w=640&q=75)
![Figure 3 for Relational Pretrained Transformers towards Democratizing Data Preparation [Vision]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fd51bec1426494f23de57b2c4184c7e26583eda53%2F3-Figure2-1.png&w=640&q=75)
![Figure 4 for Relational Pretrained Transformers towards Democratizing Data Preparation [Vision]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fd51bec1426494f23de57b2c4184c7e26583eda53%2F6-Table2-1.png&w=640&q=75)
Can AI help automate human-easy but computer-hard data preparation tasks (for example, data cleaning, data integration, and information extraction), which currently heavily involve data scientists, practitioners, and crowd workers? We envision that human-easy data preparation for relational data can be automated. To this end, we first identify the desiderata for computers to achieve near-human intelligence for data preparation: computers need a deep-learning architecture (or model) that can read and understand millions of tables; computers require unsupervised learning to perform self-learning without labeled data, and can gain knowledge from existing tasks and previous experience; and computers desire few-shot learn-ing that can adjust to new tasks with a few examples. Our proposal is called Relational Pretrained Transformers (RPTs), a general frame-work for various data preparation tasks, which typically consists of the following models/methods: (1) transformer, a general and powerful deep-learning model, that can read tables/texts/images;(2) masked language model for self-learning and collaborative train-ing for transferring knowledge and experience; and (3) pattern-exploiting training that better interprets a task from a few examples.We further present concrete RPT architectures for three classical data preparation tasks, namely data cleaning, entity resolution, and information extraction. We demonstrate RPTs with some initial yet promising results. Last but not least, we identify activities that will unleash a series of research opportunities to push forward the field of data preparation.
Inferring and Improving Street Maps with Data-Driven Automation
Nov 06, 2019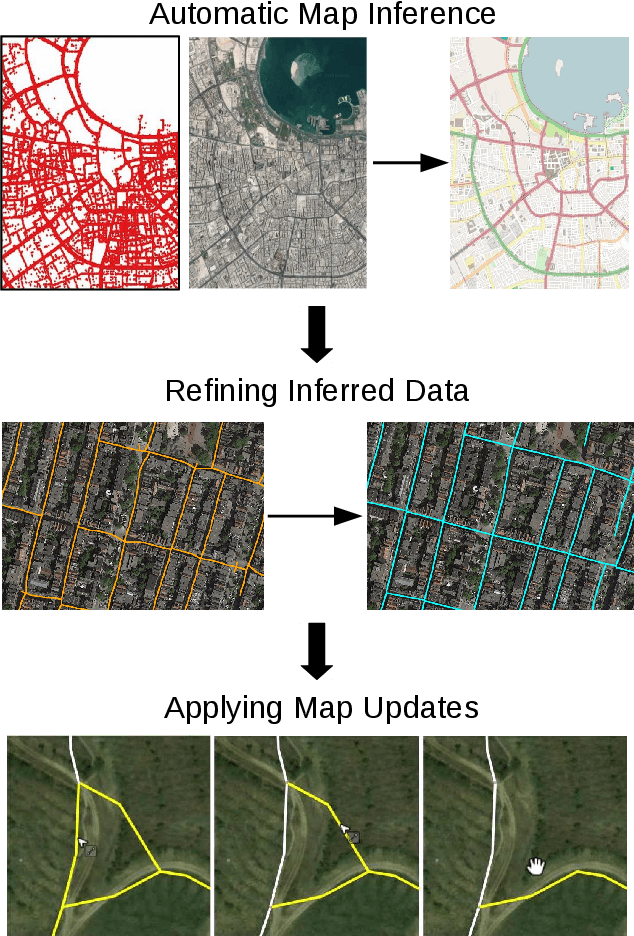
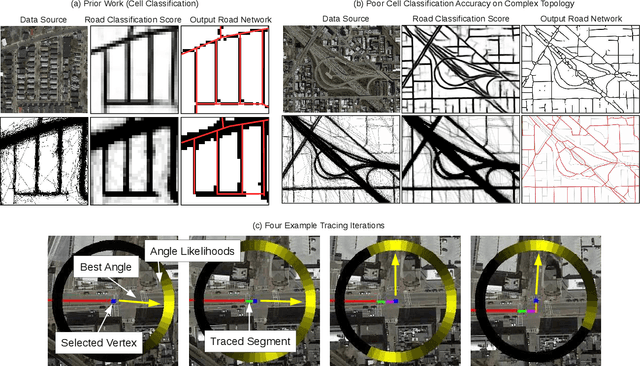
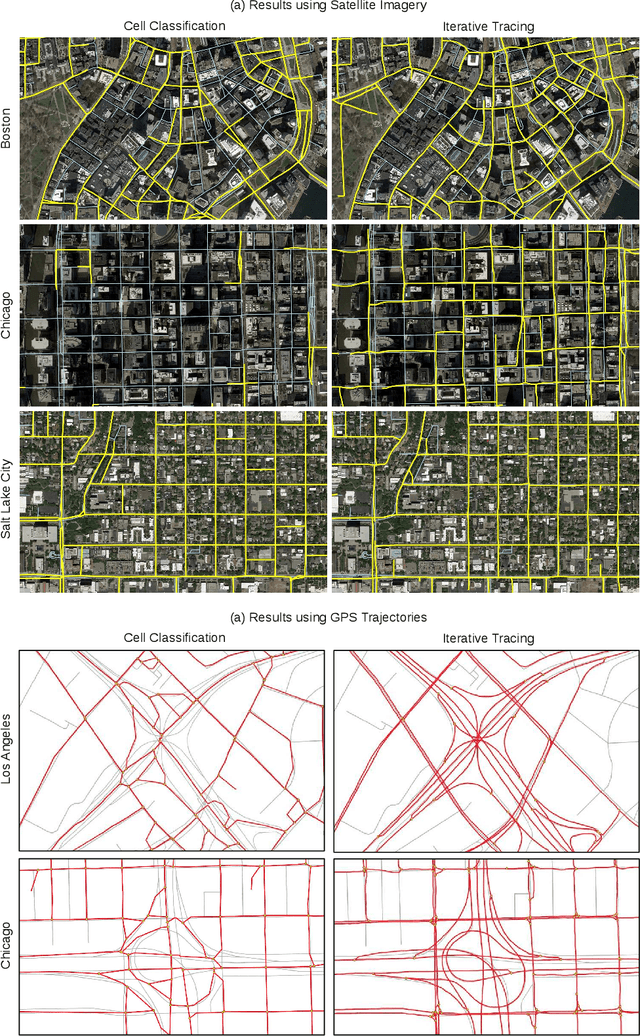
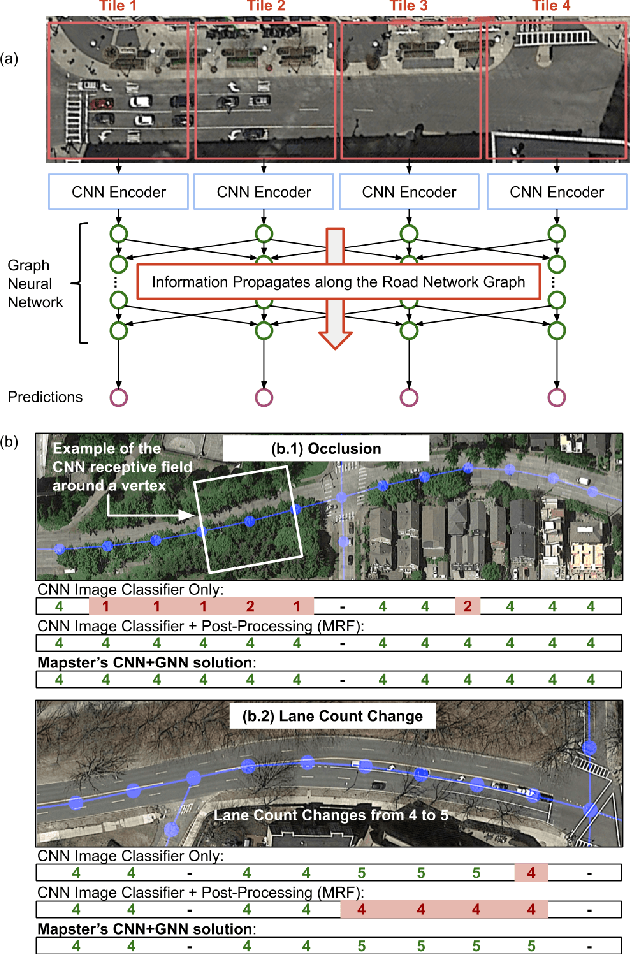
Street maps are a crucial data source that help to inform a wide range of decisions, from navigating a city to disaster relief and urban planning. However, in many parts of the world, street maps are incomplete or lag behind new construction. Editing maps today involves a tedious process of manually tracing and annotating roads, buildings, and other map features. Over the past decade, many automatic map inference systems have been proposed to automatically extract street map data from satellite imagery, aerial imagery, and GPS trajectory datasets. However, automatic map inference has failed to gain traction in practice due to two key limitations: high error rates (low precision), which manifest in noisy inference outputs, and a lack of end-to-end system design to leverage inferred data to update existing street maps. At MIT and QCRI, we have developed a number of algorithms and approaches to address these challenges, which we combined into a new system we call Mapster. Mapster is a human-in-the-loop street map editing system that incorporates three components to robustly accelerate the mapping process over traditional tools and workflows: high-precision automatic map inference, data refinement, and machine-assisted map editing. Through an evaluation on a large-scale dataset including satellite imagery, GPS trajectories, and ground-truth map data in forty cities, we show that Mapster makes automation practical for map editing, and enables the curation of map datasets that are more complete and up-to-date at less cost.