 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Diverse and Fine-Grained Instruction-Following Ability Exploration with Synthetic Data
Jul 04, 2024



Instruction-following is particularly crucial for large language models (LLMs) to support diverse user requests. While existing work has made progress in aligning LLMs with human preferences, evaluating their capabilities on instruction following remains a challenge due to complexity and diversity of real-world user instructions. While existing evaluation methods focus on general skills, they suffer from two main shortcomings, i.e., lack of fine-grained task-level evaluation and reliance on singular instruction expression. To address these problems, this paper introduces DINGO, a fine-grained and diverse instruction-following evaluation dataset that has two main advantages: (1) DINGO is based on a manual annotated, fine-grained and multi-level category tree with 130 nodes derived from real-world user requests; (2) DINGO includes diverse instructions, generated by both GPT-4 and human experts. Through extensive experiments, we demonstrate that DINGO can not only provide more challenging and comprehensive evaluation for LLMs, but also provide task-level fine-grained directions to further improve LLMs.
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
Jun 17, 2024



We present DeepSeek-Coder-V2, an open-source Mixture-of-Experts (MoE) code language model that achieves performance comparable to GPT4-Turbo in code-specific tasks. Specifically, DeepSeek-Coder-V2 is further pre-trained from an intermediate checkpoint of DeepSeek-V2 with additional 6 trillion tokens. Through this continued pre-training, DeepSeek-Coder-V2 substantially enhances the coding and mathematical reasoning capabilities of DeepSeek-V2, while maintaining comparable performance in general language tasks. Compared to DeepSeek-Coder-33B, DeepSeek-Coder-V2 demonstrates significant advancements in various aspects of code-related tasks, as well as reasoning and general capabilities. Additionally, DeepSeek-Coder-V2 expands its support for programming languages from 86 to 338, while extending the context length from 16K to 128K. In standard benchmark evaluations, DeepSeek-Coder-V2 achieves superior performance compared to closed-source models such as GPT4-Turbo, Claude 3 Opus, and Gemini 1.5 Pro in coding and math benchmarks.
SEED: Simple, Efficient, and Effective Data Management via Large Language Models
Oct 01, 2023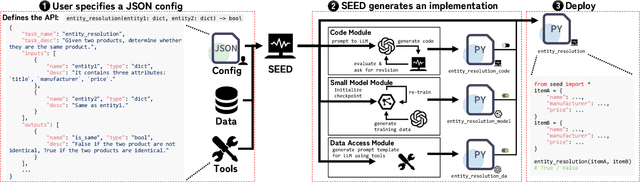
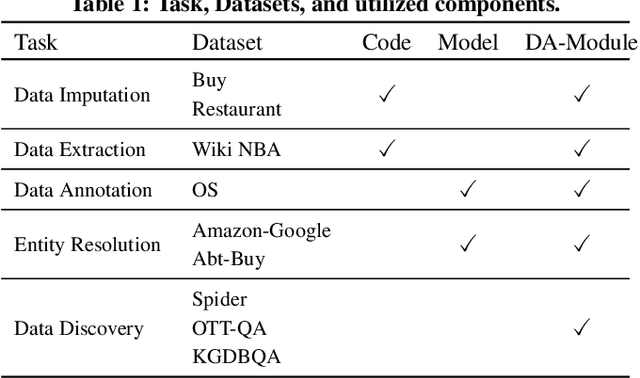
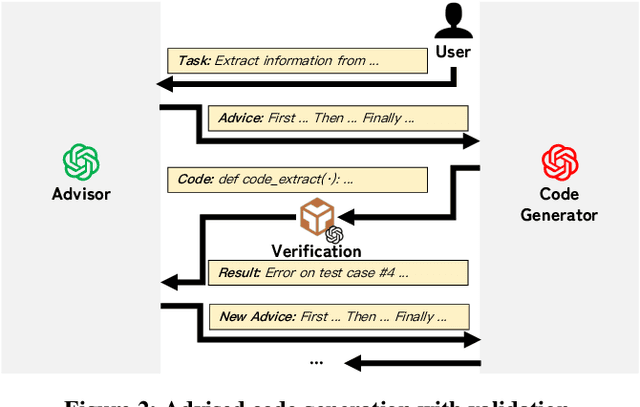
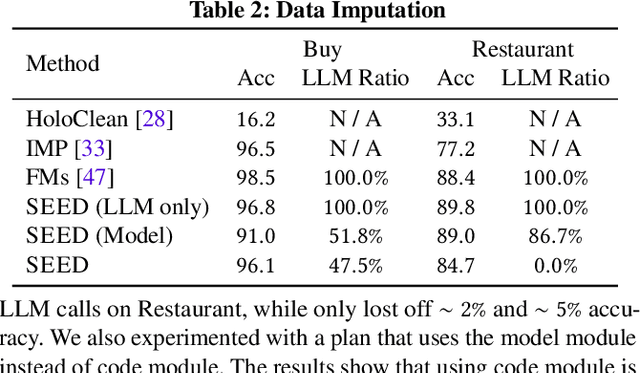
We introduce SEED, an LLM-centric system that allows users to easily create efficient, and effective data management applications. SEED comprises three main components: code generation, model generation, and augmented LLM query to address the challenges that LLM services are computationally and economically expensive and do not always work well on all cases for a given data management task. SEED addresses the expense challenge by localizing LLM computation as much as possible. This includes replacing most of LLM calls with local code, local models, and augmenting LLM queries with batching and data access tools, etc. To ensure effectiveness, SEED features a bunch of optimization techniques to enhance the localized solution and the LLM queries, including automatic code validation, code ensemble, model representatives selection, selective tool usages, etc. Moreover, with SEED users are able to easily construct a data management solution customized to their applications. It allows the users to configure each component and compose an execution pipeline in natural language. SEED then automatically compiles it into an executable program. We showcase the efficiency and effectiveness of SEED using diverse data management tasks such as data imputation, NL2SQL translation, etc., achieving state-of-the-art few-shot performance while significantly reducing the number of required LLM calls.
Interleaving Pre-Trained Language Models and Large Language Models for Zero-Shot NL2SQL Generation
Jun 15, 2023Zero-shot NL2SQL is crucial in achieving natural language to SQL that is adaptive to new environments (e.g., new databases, new linguistic phenomena or SQL structures) with zero annotated NL2SQL samples from such environments. Existing approaches either fine-tune pre-trained language models (PLMs) based on annotated data or use prompts to guide fixed large language models (LLMs) such as ChatGPT. PLMs can perform well in schema alignment but struggle to achieve complex reasoning, while LLMs is superior in complex reasoning tasks but cannot achieve precise schema alignment. In this paper, we propose a ZeroNL2SQL framework that combines the complementary advantages of PLMs and LLMs for supporting zero-shot NL2SQL. ZeroNL2SQL first uses PLMs to generate an SQL sketch via schema alignment, then uses LLMs to fill the missing information via complex reasoning. Moreover, in order to better align the generated SQL queries with values in the given database instances, we design a predicate calibration method to guide the LLM in completing the SQL sketches based on the database instances and select the optimal SQL query via an execution-based strategy. Comprehensive experiments show that ZeroNL2SQL can achieve the best zero-shot NL2SQL performance on real-world benchmarks. Specifically, ZeroNL2SQL outperforms the state-of-the-art PLM-based methods by 3.2% to 13% and exceeds LLM-based methods by 10% to 20% on execution accuracy.
PASTA: Table-Operations Aware Fact Verification via Sentence-Table Cloze Pre-training
Nov 05, 2022Fact verification has attracted a lot of research attention recently, e.g., in journalism, marketing, and policymaking, as misinformation and disinformation online can sway one's opinion and affect one's actions. While fact-checking is a hard task in general, in many cases, false statements can be easily debunked based on analytics over tables with reliable information. Hence, table-based fact verification has recently emerged as an important and growing research area. Yet, progress has been limited due to the lack of datasets that can be used to pre-train language models (LMs) to be aware of common table operations, such as aggregating a column or comparing tuples. To bridge this gap, in this paper we introduce PASTA, a novel state-of-the-art framework for table-based fact verification via pre-training with synthesized sentence-table cloze questions. In particular, we design six types of common sentence-table cloze tasks, including Filter, Aggregation, Superlative, Comparative, Ordinal, and Unique, based on which we synthesize a large corpus consisting of 1.2 million sentence-table pairs from WikiTables. PASTA uses a recent pre-trained LM, DeBERTaV3, and further pretrains it on our corpus. Our experimental results show that PASTA achieves new state-of-the-art performance on two table-based fact verification benchmarks: TabFact and SEM-TAB-FACTS. In particular, on the complex set of TabFact, which contains multiple operations, PASTA largely outperforms the previous state of the art by 4.7 points (85.6% vs. 80.9%), and the gap between PASTA and human performance on the small TabFact test set is narrowed to just 1.5 points (90.6% vs. 92.1%).