 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models
Jul 02, 2024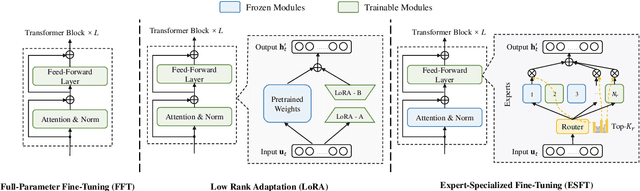
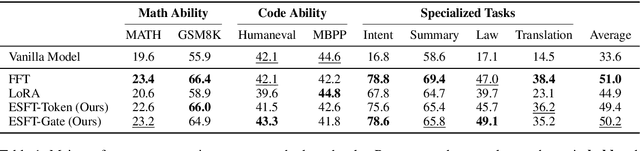
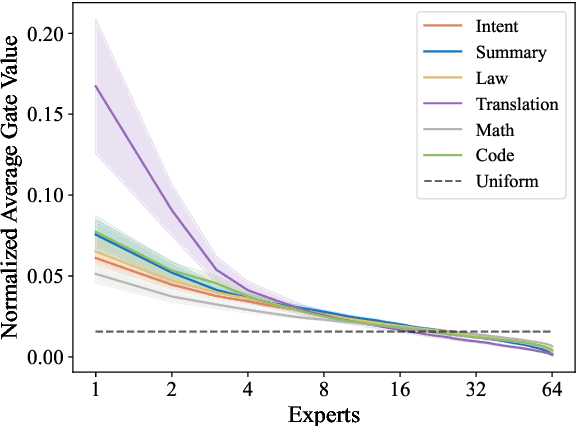

Parameter-efficient fine-tuning (PEFT) is crucial for customizing Large Language Models (LLMs) with constrained resources. Although there have been various PEFT methods for dense-architecture LLMs, PEFT for sparse-architecture LLMs is still underexplored. In this work, we study the PEFT method for LLMs with the Mixture-of-Experts (MoE) architecture and the contents of this work are mainly threefold: (1) We investigate the dispersion degree of the activated experts in customized tasks, and found that the routing distribution for a specific task tends to be highly concentrated, while the distribution of activated experts varies significantly across different tasks. (2) We propose Expert-Specialized Fine-Tuning, or ESFT, which tunes the experts most relevant to downstream tasks while freezing the other experts and modules; experimental results demonstrate that our method not only improves the tuning efficiency, but also matches or even surpasses the performance of full-parameter fine-tuning. (3) We further analyze the impact of the MoE architecture on expert-specialized fine-tuning. We find that MoE models with finer-grained experts are more advantageous in selecting the combination of experts that are most relevant to downstream tasks, thereby enhancing both the training efficiency and effectiveness.
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
Jun 17, 2024



We present DeepSeek-Coder-V2, an open-source Mixture-of-Experts (MoE) code language model that achieves performance comparable to GPT4-Turbo in code-specific tasks. Specifically, DeepSeek-Coder-V2 is further pre-trained from an intermediate checkpoint of DeepSeek-V2 with additional 6 trillion tokens. Through this continued pre-training, DeepSeek-Coder-V2 substantially enhances the coding and mathematical reasoning capabilities of DeepSeek-V2, while maintaining comparable performance in general language tasks. Compared to DeepSeek-Coder-33B, DeepSeek-Coder-V2 demonstrates significant advancements in various aspects of code-related tasks, as well as reasoning and general capabilities. Additionally, DeepSeek-Coder-V2 expands its support for programming languages from 86 to 338, while extending the context length from 16K to 128K. In standard benchmark evaluations, DeepSeek-Coder-V2 achieves superior performance compared to closed-source models such as GPT4-Turbo, Claude 3 Opus, and Gemini 1.5 Pro in coding and math benchmarks.
Hyperbolic Secant representation of the logistic function: Application to probabilistic Multiple Instance Learning for CT intracranial hemorrhage detection
Mar 21, 2024



Multiple Instance Learning (MIL) is a weakly supervised paradigm that has been successfully applied to many different scientific areas and is particularly well suited to medical imaging. Probabilistic MIL methods, and more specifically Gaussian Processes (GPs), have achieved excellent results due to their high expressiveness and uncertainty quantification capabilities. One of the most successful GP-based MIL methods, VGPMIL, resorts to a variational bound to handle the intractability of the logistic function. Here, we formulate VGPMIL using P\'olya-Gamma random variables. This approach yields the same variational posterior approximations as the original VGPMIL, which is a consequence of the two representations that the Hyperbolic Secant distribution admits. This leads us to propose a general GP-based MIL method that takes different forms by simply leveraging distributions other than the Hyperbolic Secant one. Using the Gamma distribution we arrive at a new approach that obtains competitive or superior predictive performance and efficiency. This is validated in a comprehensive experimental study including one synthetic MIL dataset, two well-known MIL benchmarks, and a real-world medical problem. We expect that this work provides useful ideas beyond MIL that can foster further research in the field.
* 48 pages, 12 figures, published in Artificial Intelligence Journal
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Feb 06, 2024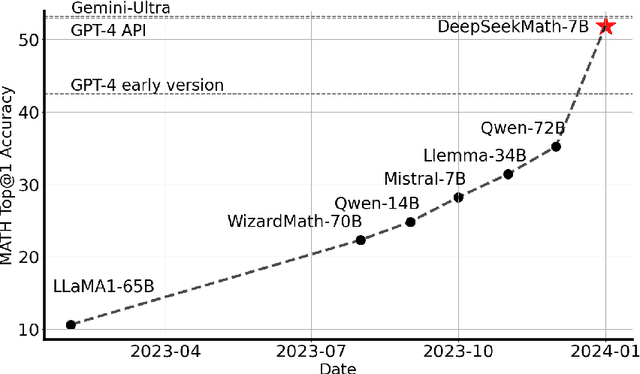
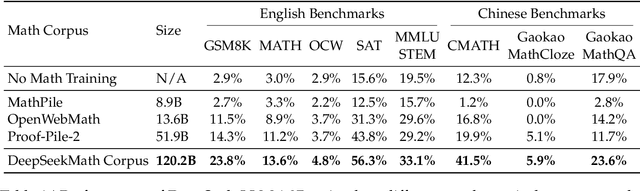
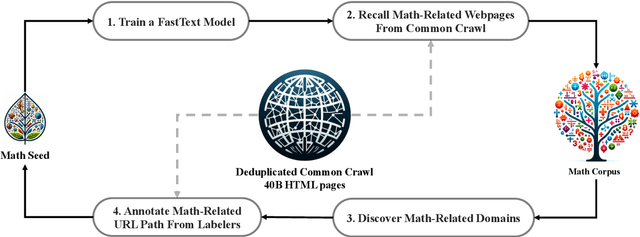
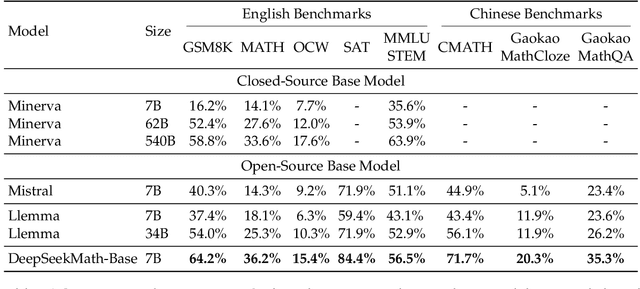
Mathematical reasoning poses a significant challenge for language models due to its complex and structured nature. In this paper, we introduce DeepSeekMath 7B, which continues pre-training DeepSeek-Coder-Base-v1.5 7B with 120B math-related tokens sourced from Common Crawl, together with natural language and code data. DeepSeekMath 7B has achieved an impressive score of 51.7% on the competition-level MATH benchmark without relying on external toolkits and voting techniques, approaching the performance level of Gemini-Ultra and GPT-4. Self-consistency over 64 samples from DeepSeekMath 7B achieves 60.9% on MATH. The mathematical reasoning capability of DeepSeekMath is attributed to two key factors: First, we harness the significant potential of publicly available web data through a meticulously engineered data selection pipeline. Second, we introduce Group Relative Policy Optimization (GRPO), a variant of Proximal Policy Optimization (PPO), that enhances mathematical reasoning abilities while concurrently optimizing the memory usage of PPO.
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
Jan 26, 2024



The rapid development of large language models has revolutionized code intelligence in software development. However, the predominance of closed-source models has restricted extensive research and development. To address this, we introduce the DeepSeek-Coder series, a range of open-source code models with sizes from 1.3B to 33B, trained from scratch on 2 trillion tokens. These models are pre-trained on a high-quality project-level code corpus and employ a fill-in-the-blank task with a 16K window to enhance code generation and infilling. Our extensive evaluations demonstrate that DeepSeek-Coder not only achieves state-of-the-art performance among open-source code models across multiple benchmarks but also surpasses existing closed-source models like Codex and GPT-3.5. Furthermore, DeepSeek-Coder models are under a permissive license that allows for both research and unrestricted commercial use.
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
Jan 11, 2024



In the era of large language models, Mixture-of-Experts (MoE) is a promising architecture for managing computational costs when scaling up model parameters. However, conventional MoE architectures like GShard, which activate the top-$K$ out of $N$ experts, face challenges in ensuring expert specialization, i.e. each expert acquires non-overlapping and focused knowledge. In response, we propose the DeepSeekMoE architecture towards ultimate expert specialization. It involves two principal strategies: (1) finely segmenting the experts into $mN$ ones and activating $mK$ from them, allowing for a more flexible combination of activated experts; (2) isolating $K_s$ experts as shared ones, aiming at capturing common knowledge and mitigating redundancy in routed experts. Starting from a modest scale with 2B parameters, we demonstrate that DeepSeekMoE 2B achieves comparable performance with GShard 2.9B, which has 1.5 times the expert parameters and computation. In addition, DeepSeekMoE 2B nearly approaches the performance of its dense counterpart with the same number of total parameters, which set the upper bound of MoE models. Subsequently, we scale up DeepSeekMoE to 16B parameters and show that it achieves comparable performance with LLaMA2 7B, with only about 40% of computations. Further, our preliminary efforts to scale up DeepSeekMoE to 145B parameters consistently validate its substantial advantages over the GShard architecture, and show its performance comparable with DeepSeek 67B, using only 28.5% (maybe even 18.2%) of computations.
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Jan 05, 2024



The rapid development of open-source large language models (LLMs) has been truly remarkable. However, the scaling law described in previous literature presents varying conclusions, which casts a dark cloud over scaling LLMs. We delve into the study of scaling laws and present our distinctive findings that facilitate scaling of large scale models in two commonly used open-source configurations, 7B and 67B. Guided by the scaling laws, we introduce DeepSeek LLM, a project dedicated to advancing open-source language models with a long-term perspective. To support the pre-training phase, we have developed a dataset that currently consists of 2 trillion tokens and is continuously expanding. We further conduct supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, resulting in the creation of DeepSeek Chat models. Our evaluation results demonstrate that DeepSeek LLM 67B surpasses LLaMA-2 70B on various benchmarks, particularly in the domains of code, mathematics, and reasoning. Furthermore, open-ended evaluations reveal that DeepSeek LLM 67B Chat exhibits superior performance compared to GPT-3.5.
Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
Dec 28, 2023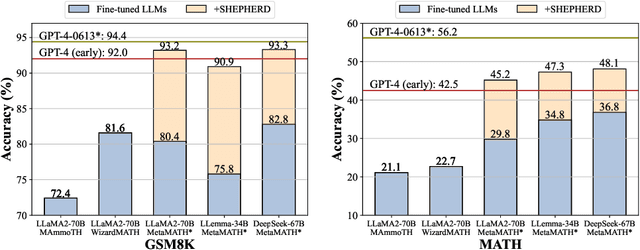


In this paper, we present an innovative process-oriented math process reward model called \textbf{Math-Shepherd}, which assigns a reward score to each step of math problem solutions. The training of Math-Shepherd is achieved using automatically constructed process-wise supervision data, breaking the bottleneck of heavy reliance on manual annotation in existing work. We explore the effectiveness of Math-Shepherd in two scenarios: 1) \textit{Verification}: Math-Shepherd is utilized for reranking multiple outputs generated by Large Language Models (LLMs); 2) \textit{Reinforcement Learning}: Math-Shepherd is employed to reinforce LLMs with step-by-step Proximal Policy Optimization (PPO). With Math-Shepherd, a series of open-source LLMs demonstrates exceptional performance. For instance, the step-by-step PPO with Math-Shepherd significantly improves the accuracy of Mistral-7B (77.9\%$\to$84.1\% on GSM8K and 28.6\%$\to$33.0\% on MATH). The accuracy can be further enhanced to 89.1\% and 43.5\% on GSM8K and MATH with the verification of Math-Shepherd, respectively. We believe that automatic process supervision holds significant potential for the future evolution of LLMs.
A Generative deep learning approach for shape recognition of arbitrary objects from phaseless acoustic scattering data
Jul 12, 2022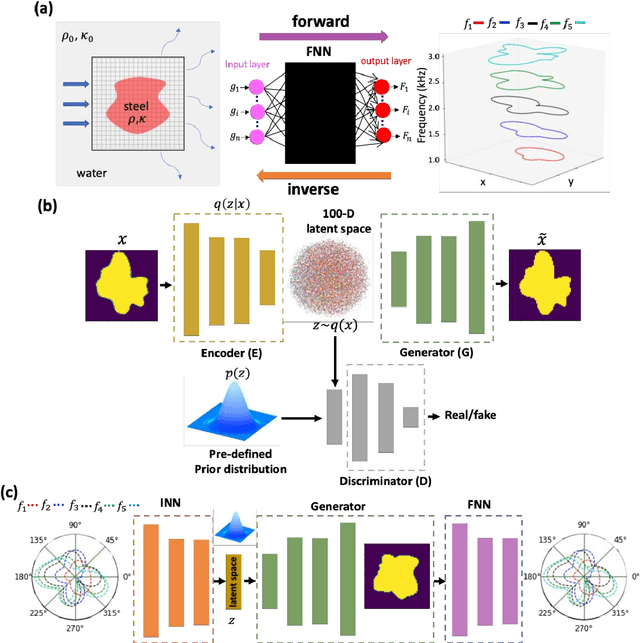
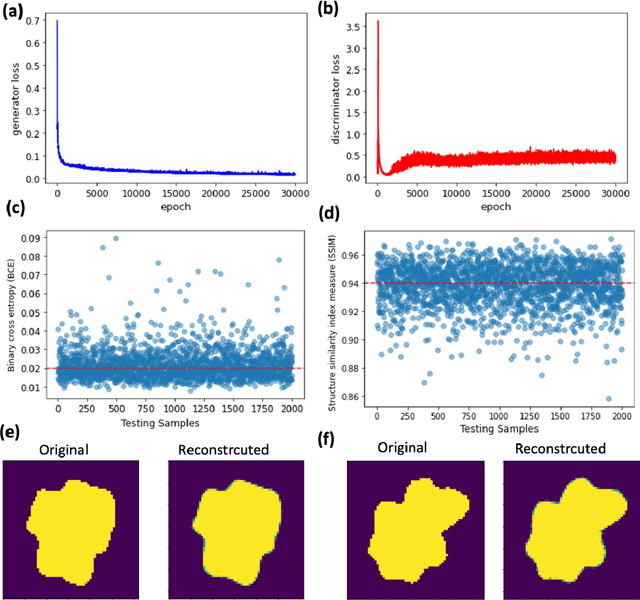
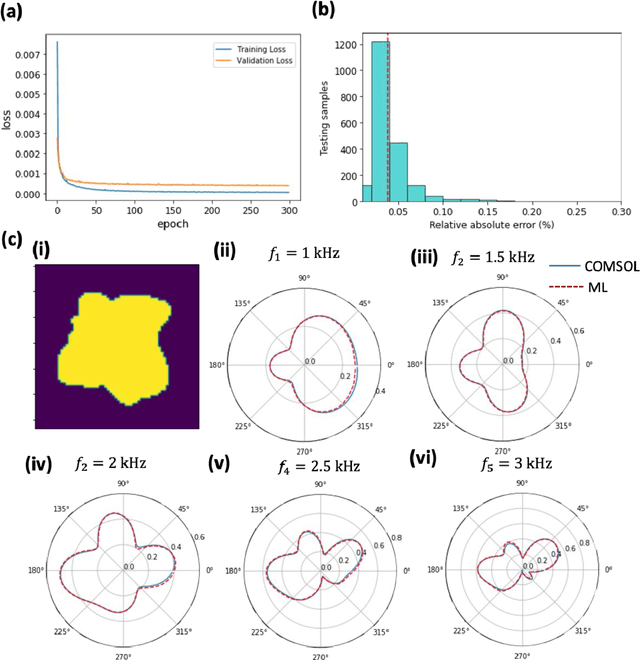
We propose and demonstrate a generative deep learning approach for the shape recognition of an arbitrary object from its acoustic scattering properties. The strategy exploits deep neural networks to learn the mapping between the latent space of a two-dimensional acoustic object and the far-field scattering amplitudes. A neural network is designed as an Adversarial autoencoder and trained via unsupervised learning to determine the latent space of the acoustic object. Important structural features of the object are embedded in lower-dimensional latent space which supports the modeling of a shape generator and accelerates the learning in the inverse design process.The proposed inverse design uses the variational inference approach with encoder and decoder-like architecture where the decoder is composed of two pretrained neural networks, the generator and the forward model. The data-driven framework finds an accurate solution to the ill-posed inverse scattering problem, where non-unique solution space is overcome by the multifrequency phaseless far-field patterns. This inverse method is a powerful design tool that does not require complex analytical calculation and opens up new avenues for practical realization, automatic recognition of arbitrary shaped submarines or large fish, and other underwater applications.
Machine learning for knowledge acquisition and accelerated inverse-design for non-Hermitian systems
Apr 28, 2022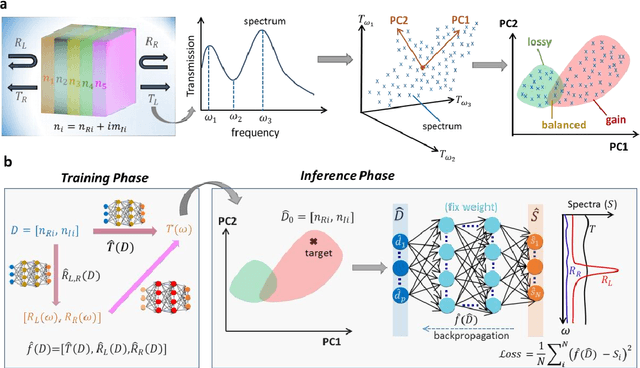
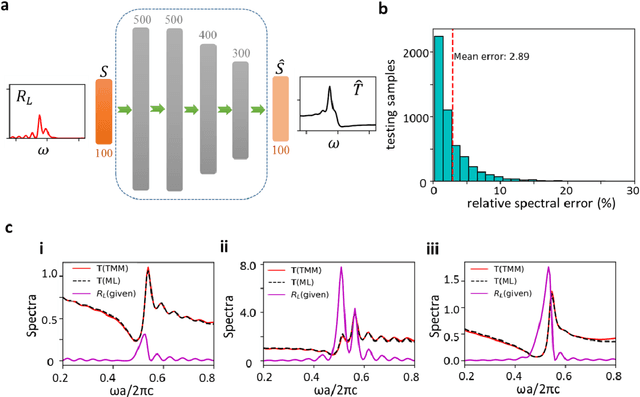
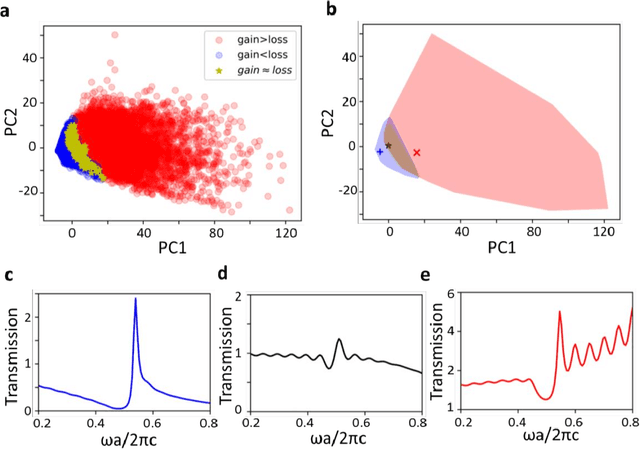
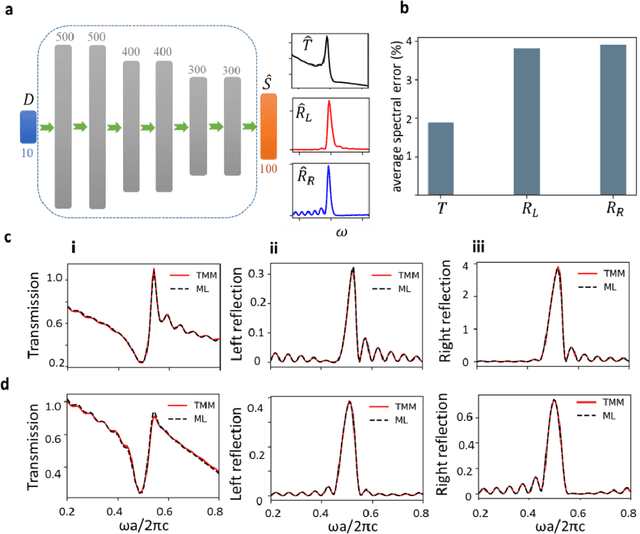
Non-Hermitian systems offer new platforms for unusual physical properties that can be flexibly manipulated by redistribution of the real and imaginary parts of refractive indices, whose presence breaks conventional wave propagation symmetries, leading to asymmetric reflection and symmetric transmission with respect to the wave propagation direction. Here, we use supervised and unsupervised learning techniques for knowledge acquisition in non-Hermitian systems which accelerate the inverse design process. In particular, we construct a deep learning model that relates the transmission and asymmetric reflection in non-conservative settings and proposes sub-manifold learning to recognize non-Hermitian features from transmission spectra. The developed deep learning framework determines the feasibility of a desired spectral response for a given structure and uncovers the role of effective gain-loss parameters to tailor the spectral response. These findings pave the way for intelligent inverse design and shape our understanding of the physical mechanism in general non-Hermitian systems.