 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperbolic Secant representation of the logistic function: Application to probabilistic Multiple Instance Learning for CT intracranial hemorrhage detection
Mar 21, 2024



Multiple Instance Learning (MIL) is a weakly supervised paradigm that has been successfully applied to many different scientific areas and is particularly well suited to medical imaging. Probabilistic MIL methods, and more specifically Gaussian Processes (GPs), have achieved excellent results due to their high expressiveness and uncertainty quantification capabilities. One of the most successful GP-based MIL methods, VGPMIL, resorts to a variational bound to handle the intractability of the logistic function. Here, we formulate VGPMIL using P\'olya-Gamma random variables. This approach yields the same variational posterior approximations as the original VGPMIL, which is a consequence of the two representations that the Hyperbolic Secant distribution admits. This leads us to propose a general GP-based MIL method that takes different forms by simply leveraging distributions other than the Hyperbolic Secant one. Using the Gamma distribution we arrive at a new approach that obtains competitive or superior predictive performance and efficiency. This is validated in a comprehensive experimental study including one synthetic MIL dataset, two well-known MIL benchmarks, and a real-world medical problem. We expect that this work provides useful ideas beyond MIL that can foster further research in the field.
* 48 pages, 12 figures, published in Artificial Intelligence Journal
An Adaptive Video Acquisition Scheme for Object Tracking and its Performance Optimization
Feb 24, 2021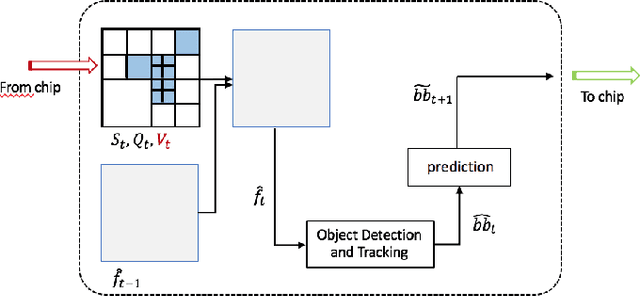
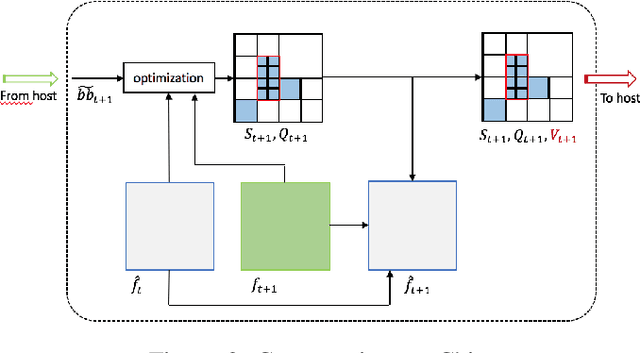


We present a novel adaptive host-chip modular architecture for video acquisition to optimize an overall objective task constrained under a given bit rate. The chip is a high resolution imaging sensor such as gigapixel focal plane array (FPA) with low computational power deployed on the field remotely, while the host is a server with high computational power. The communication channel data bandwidth between the chip and host is constrained to accommodate transfer of all captured data from the chip. The host performs objective task specific computations and also intelligently guides the chip to optimize (compress) the data sent to host. This proposed system is modular and highly versatile in terms of flexibility in re-orienting the objective task. In this work, object tracking is the objective task. While our architecture supports any form of compression/distortion, in this paper we use quadtree (QT)-segmented video frames. We use Viterbi (Dynamic Programming) algorithm to minimize the area normalized weighted rate-distortion allocation of resources. The host receives only these degraded frames for analysis. An object detector is used to detect objects, and a Kalman Filter based tracker is used to track those objects. Evaluation of system performance is done in terms of Multiple Object Tracking Accuracy (MOTA) metric. In this proposed novel architecture, performance gains in MOTA is obtained by twice training the object detector with different system generated distortions as a novel 2-step process. Additionally, object detector is assisted by tracker to upscore the region proposals in the detector to further improve the performance.