 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMath-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
Paper and Code
Dec 28, 2023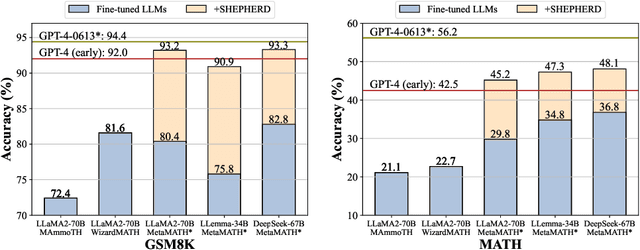

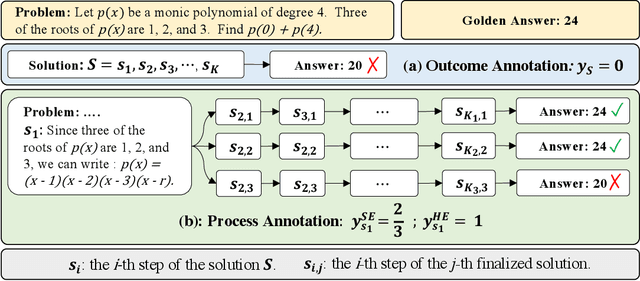

In this paper, we present an innovative process-oriented math process reward model called \textbf{Math-Shepherd}, which assigns a reward score to each step of math problem solutions. The training of Math-Shepherd is achieved using automatically constructed process-wise supervision data, breaking the bottleneck of heavy reliance on manual annotation in existing work. We explore the effectiveness of Math-Shepherd in two scenarios: 1) \textit{Verification}: Math-Shepherd is utilized for reranking multiple outputs generated by Large Language Models (LLMs); 2) \textit{Reinforcement Learning}: Math-Shepherd is employed to reinforce LLMs with step-by-step Proximal Policy Optimization (PPO). With Math-Shepherd, a series of open-source LLMs demonstrates exceptional performance. For instance, the step-by-step PPO with Math-Shepherd significantly improves the accuracy of Mistral-7B (77.9\%$\to$84.1\% on GSM8K and 28.6\%$\to$33.0\% on MATH). The accuracy can be further enhanced to 89.1\% and 43.5\% on GSM8K and MATH with the verification of Math-Shepherd, respectively. We believe that automatic process supervision holds significant potential for the future evolution of LLMs.