 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models
Jul 02, 2024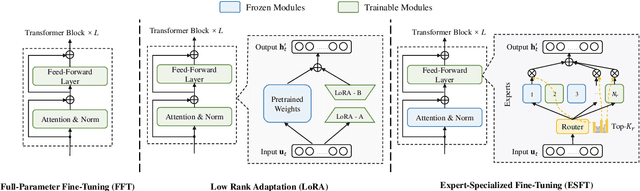
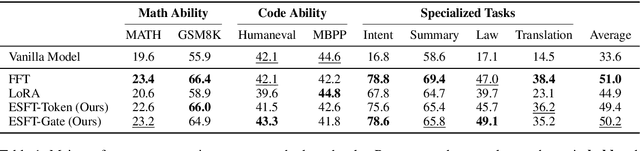
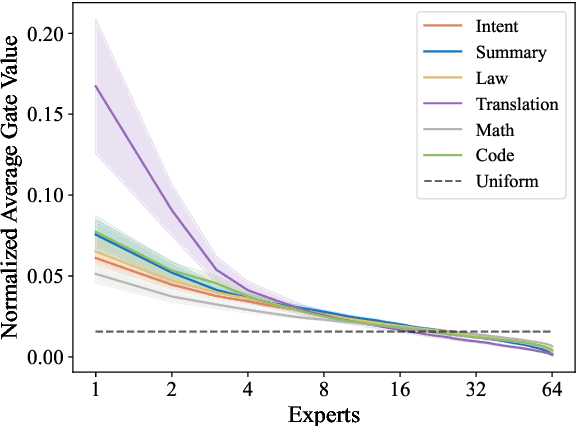

Parameter-efficient fine-tuning (PEFT) is crucial for customizing Large Language Models (LLMs) with constrained resources. Although there have been various PEFT methods for dense-architecture LLMs, PEFT for sparse-architecture LLMs is still underexplored. In this work, we study the PEFT method for LLMs with the Mixture-of-Experts (MoE) architecture and the contents of this work are mainly threefold: (1) We investigate the dispersion degree of the activated experts in customized tasks, and found that the routing distribution for a specific task tends to be highly concentrated, while the distribution of activated experts varies significantly across different tasks. (2) We propose Expert-Specialized Fine-Tuning, or ESFT, which tunes the experts most relevant to downstream tasks while freezing the other experts and modules; experimental results demonstrate that our method not only improves the tuning efficiency, but also matches or even surpasses the performance of full-parameter fine-tuning. (3) We further analyze the impact of the MoE architecture on expert-specialized fine-tuning. We find that MoE models with finer-grained experts are more advantageous in selecting the combination of experts that are most relevant to downstream tasks, thereby enhancing both the training efficiency and effectiveness.
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
Jun 17, 2024



We present DeepSeek-Coder-V2, an open-source Mixture-of-Experts (MoE) code language model that achieves performance comparable to GPT4-Turbo in code-specific tasks. Specifically, DeepSeek-Coder-V2 is further pre-trained from an intermediate checkpoint of DeepSeek-V2 with additional 6 trillion tokens. Through this continued pre-training, DeepSeek-Coder-V2 substantially enhances the coding and mathematical reasoning capabilities of DeepSeek-V2, while maintaining comparable performance in general language tasks. Compared to DeepSeek-Coder-33B, DeepSeek-Coder-V2 demonstrates significant advancements in various aspects of code-related tasks, as well as reasoning and general capabilities. Additionally, DeepSeek-Coder-V2 expands its support for programming languages from 86 to 338, while extending the context length from 16K to 128K. In standard benchmark evaluations, DeepSeek-Coder-V2 achieves superior performance compared to closed-source models such as GPT4-Turbo, Claude 3 Opus, and Gemini 1.5 Pro in coding and math benchmarks.
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
Jan 11, 2024



In the era of large language models, Mixture-of-Experts (MoE) is a promising architecture for managing computational costs when scaling up model parameters. However, conventional MoE architectures like GShard, which activate the top-$K$ out of $N$ experts, face challenges in ensuring expert specialization, i.e. each expert acquires non-overlapping and focused knowledge. In response, we propose the DeepSeekMoE architecture towards ultimate expert specialization. It involves two principal strategies: (1) finely segmenting the experts into $mN$ ones and activating $mK$ from them, allowing for a more flexible combination of activated experts; (2) isolating $K_s$ experts as shared ones, aiming at capturing common knowledge and mitigating redundancy in routed experts. Starting from a modest scale with 2B parameters, we demonstrate that DeepSeekMoE 2B achieves comparable performance with GShard 2.9B, which has 1.5 times the expert parameters and computation. In addition, DeepSeekMoE 2B nearly approaches the performance of its dense counterpart with the same number of total parameters, which set the upper bound of MoE models. Subsequently, we scale up DeepSeekMoE to 16B parameters and show that it achieves comparable performance with LLaMA2 7B, with only about 40% of computations. Further, our preliminary efforts to scale up DeepSeekMoE to 145B parameters consistently validate its substantial advantages over the GShard architecture, and show its performance comparable with DeepSeek 67B, using only 28.5% (maybe even 18.2%) of computations.
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Jan 05, 2024



The rapid development of open-source large language models (LLMs) has been truly remarkable. However, the scaling law described in previous literature presents varying conclusions, which casts a dark cloud over scaling LLMs. We delve into the study of scaling laws and present our distinctive findings that facilitate scaling of large scale models in two commonly used open-source configurations, 7B and 67B. Guided by the scaling laws, we introduce DeepSeek LLM, a project dedicated to advancing open-source language models with a long-term perspective. To support the pre-training phase, we have developed a dataset that currently consists of 2 trillion tokens and is continuously expanding. We further conduct supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, resulting in the creation of DeepSeek Chat models. Our evaluation results demonstrate that DeepSeek LLM 67B surpasses LLaMA-2 70B on various benchmarks, particularly in the domains of code, mathematics, and reasoning. Furthermore, open-ended evaluations reveal that DeepSeek LLM 67B Chat exhibits superior performance compared to GPT-3.5.
Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
Dec 28, 2023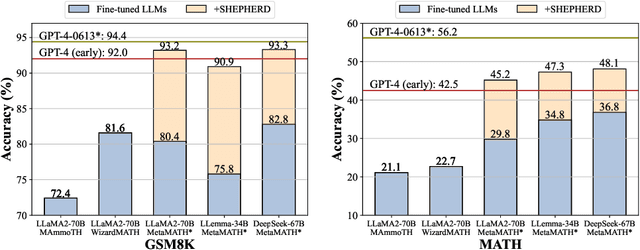

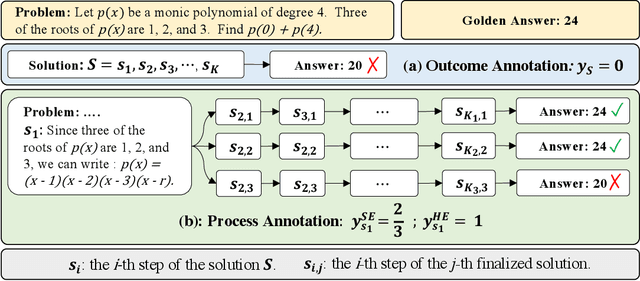

In this paper, we present an innovative process-oriented math process reward model called \textbf{Math-Shepherd}, which assigns a reward score to each step of math problem solutions. The training of Math-Shepherd is achieved using automatically constructed process-wise supervision data, breaking the bottleneck of heavy reliance on manual annotation in existing work. We explore the effectiveness of Math-Shepherd in two scenarios: 1) \textit{Verification}: Math-Shepherd is utilized for reranking multiple outputs generated by Large Language Models (LLMs); 2) \textit{Reinforcement Learning}: Math-Shepherd is employed to reinforce LLMs with step-by-step Proximal Policy Optimization (PPO). With Math-Shepherd, a series of open-source LLMs demonstrates exceptional performance. For instance, the step-by-step PPO with Math-Shepherd significantly improves the accuracy of Mistral-7B (77.9\%$\to$84.1\% on GSM8K and 28.6\%$\to$33.0\% on MATH). The accuracy can be further enhanced to 89.1\% and 43.5\% on GSM8K and MATH with the verification of Math-Shepherd, respectively. We believe that automatic process supervision holds significant potential for the future evolution of LLMs.
Towards Codable Text Watermarking for Large Language Models
Jul 29, 2023As large language models (LLMs) generate texts with increasing fluency and realism, there is a growing need to identify the source of texts to prevent the abuse of LLMs. Text watermarking techniques have proven reliable in distinguishing whether a text is generated by LLMs by injecting hidden patterns into the generated texts. However, we argue that existing watermarking methods for LLMs are encoding-inefficient (only contain one bit of information - whether it is generated from an LLM or not) and cannot flexibly meet the diverse information encoding needs (such as encoding model version, generation time, user id, etc.) in different LLMs application scenarios. In this work, we conduct the first systematic study on the topic of Codable Text Watermarking for LLMs (CTWL) that allows text watermarks to carry more customizable information. First of all, we study the taxonomy of LLM watermarking technology and give a mathematical formulation for CTWL. Additionally, we provide a comprehensive evaluation system for CTWL: (1) watermarking success rate, (2) robustness against various corruptions, (3) coding rate of payload information, (4) encoding and decoding efficiency, (5) impacts on the quality of the generated text. To meet the requirements of these non-Pareto-improving metrics, we devise a CTWL method named Balance-Marking, based on the motivation of ensuring that available and unavailable vocabularies for encoding information have approximately equivalent probabilities. Compared to the random vocabulary partitioning extended from the existing work, a probability-balanced vocabulary partition can significantly improve the quality of the generated text. Extensive experimental results have shown that our method outperforms a direct baseline under comprehensive evaluation.
Label Words are Anchors: An Information Flow Perspective for Understanding In-Context Learning
May 23, 2023



In-context learning (ICL) emerges as a promising capability of large language models (LLMs) by providing them with demonstration examples to perform diverse tasks. However, the underlying mechanism of how LLMs learn from the provided context remains under-explored. In this paper, we investigate the working mechanism of ICL through an information flow lens. Our findings reveal that label words in the demonstration examples function as anchors: (1) semantic information aggregates into label word representations during the shallow computation layers' processing; (2) the consolidated information in label words serves as a reference for LLMs' final predictions. Based on these insights, we introduce an anchor re-weighting method to improve ICL performance, a demonstration compression technique to expedite inference, and an analysis framework for diagnosing ICL errors in GPT2-XL. The promising applications of our findings again validate the uncovered ICL working mechanism and pave the way for future studies.
Diffusion Theory as a Scalpel: Detecting and Purifying Poisonous Dimensions in Pre-trained Language Models Caused by Backdoor or Bias
May 08, 2023



Pre-trained Language Models (PLMs) may be poisonous with backdoors or bias injected by the suspicious attacker during the fine-tuning process. A core challenge of purifying potentially poisonous PLMs is precisely finding poisonous dimensions. To settle this issue, we propose the Fine-purifying approach, which utilizes the diffusion theory to study the dynamic process of fine-tuning for finding potentially poisonous dimensions. According to the relationship between parameter drifts and Hessians of different dimensions, we can detect poisonous dimensions with abnormal dynamics, purify them by resetting them to clean pre-trained weights, and then fine-tune the purified weights on a small clean dataset. To the best of our knowledge, we are the first to study the dynamics guided by the diffusion theory for safety or defense purposes. Experimental results validate the effectiveness of Fine-purifying even with a small clean dataset.
Integrating Local Real Data with Global Gradient Prototypes for Classifier Re-Balancing in Federated Long-Tailed Learning
Jan 26, 2023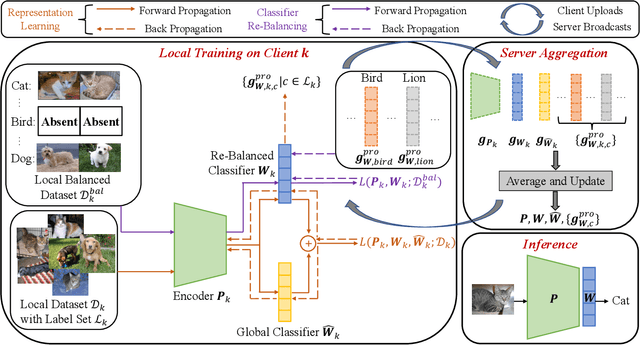



Federated Learning (FL) has become a popular distributed learning paradigm that involves multiple clients training a global model collaboratively in a data privacy-preserving manner. However, the data samples usually follow a long-tailed distribution in the real world, and FL on the decentralized and long-tailed data yields a poorly-behaved global model severely biased to the head classes with the majority of the training samples. To alleviate this issue, decoupled training has recently been introduced to FL, considering it has achieved promising results in centralized long-tailed learning by re-balancing the biased classifier after the instance-balanced training. However, the current study restricts the capacity of decoupled training in federated long-tailed learning with a sub-optimal classifier re-trained on a set of pseudo features, due to the unavailability of a global balanced dataset in FL. In this work, in order to re-balance the classifier more effectively, we integrate the local real data with the global gradient prototypes to form the local balanced datasets, and thus re-balance the classifier during the local training. Furthermore, we introduce an extra classifier in the training phase to help model the global data distribution, which addresses the problem of contradictory optimization goals caused by performing classifier re-balancing locally. Extensive experiments show that our method consistently outperforms the existing state-of-the-art methods in various settings.