 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSeek-Prover-V2: Advancing Formal Mathematical Reasoning via Reinforcement Learning for Subgoal Decomposition
Apr 30, 2025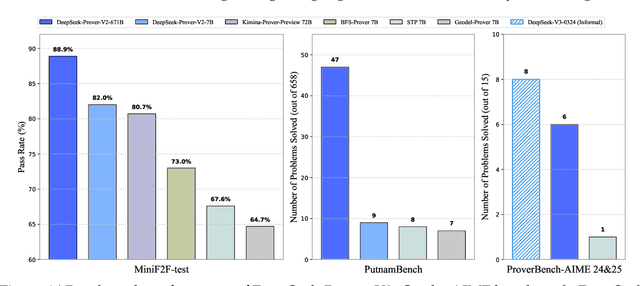
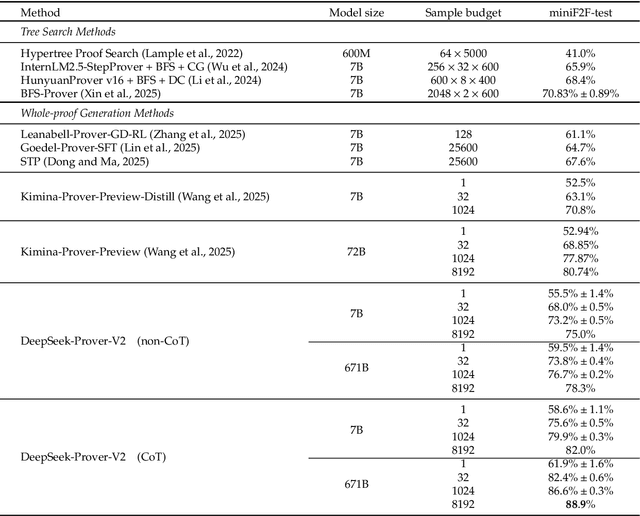

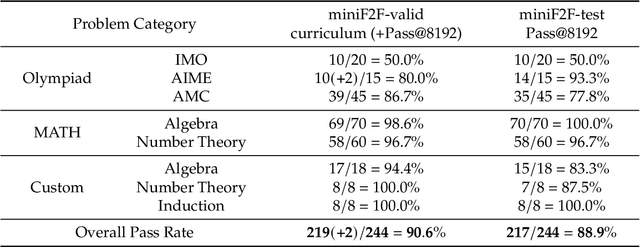
We introduce DeepSeek-Prover-V2, an open-source large language model designed for formal theorem proving in Lean 4, with initialization data collected through a recursive theorem proving pipeline powered by DeepSeek-V3. The cold-start training procedure begins by prompting DeepSeek-V3 to decompose complex problems into a series of subgoals. The proofs of resolved subgoals are synthesized into a chain-of-thought process, combined with DeepSeek-V3's step-by-step reasoning, to create an initial cold start for reinforcement learning. This process enables us to integrate both informal and formal mathematical reasoning into a unified model. The resulting model, DeepSeek-Prover-V2-671B, achieves state-of-the-art performance in neural theorem proving, reaching 88.9% pass ratio on the MiniF2F-test and solving 49 out of 658 problems from PutnamBench. In addition to standard benchmarks, we introduce ProverBench, a collection of 325 formalized problems, to enrich our evaluation, including 15 selected problems from the recent AIME competitions (years 24-25). Further evaluation on these 15 AIME problems shows that the model successfully solves 6 of them. In comparison, DeepSeek-V3 solves 8 of these problems using majority voting, highlighting that the gap between formal and informal mathematical reasoning in large language models is substantially narrowing.
CodeI/O: Condensing Reasoning Patterns via Code Input-Output Prediction
Feb 12, 2025Reasoning is a fundamental capability of Large Language Models. While prior research predominantly focuses on enhancing narrow skills like math or code generation, improving performance on many other reasoning tasks remains challenging due to sparse and fragmented training data. To address this issue, we propose CodeI/O, a novel approach that systematically condenses diverse reasoning patterns inherently embedded in contextually-grounded codes, through transforming the original code into a code input-output prediction format. By training models to predict inputs/outputs given code and test cases entirely in natural language as Chain-of-Thought (CoT) rationales, we expose them to universal reasoning primitives -- like logic flow planning, state-space searching, decision tree traversal, and modular decomposition -- while decoupling structured reasoning from code-specific syntax and preserving procedural rigor. Experimental results demonstrate CodeI/O leads to consistent improvements across symbolic, scientific, logic, math & numerical, and commonsense reasoning tasks. By matching the existing ground-truth outputs or re-executing the code with predicted inputs, we can verify each prediction and further enhance the CoTs through multi-turn revision, resulting in CodeI/O++ and achieving higher performance. Our data and models are available at https://github.com/hkust-nlp/CodeIO.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search
Aug 15, 2024



We introduce DeepSeek-Prover-V1.5, an open-source language model designed for theorem proving in Lean 4, which enhances DeepSeek-Prover-V1 by optimizing both training and inference processes. Pre-trained on DeepSeekMath-Base with specialization in formal mathematical languages, the model undergoes supervised fine-tuning using an enhanced formal theorem proving dataset derived from DeepSeek-Prover-V1. Further refinement is achieved through reinforcement learning from proof assistant feedback (RLPAF). Beyond the single-pass whole-proof generation approach of DeepSeek-Prover-V1, we propose RMaxTS, a variant of Monte-Carlo tree search that employs an intrinsic-reward-driven exploration strategy to generate diverse proof paths. DeepSeek-Prover-V1.5 demonstrates significant improvements over DeepSeek-Prover-V1, achieving new state-of-the-art results on the test set of the high school level miniF2F benchmark ($63.5\%$) and the undergraduate level ProofNet benchmark ($25.3\%$).
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
Jun 17, 2024



We present DeepSeek-Coder-V2, an open-source Mixture-of-Experts (MoE) code language model that achieves performance comparable to GPT4-Turbo in code-specific tasks. Specifically, DeepSeek-Coder-V2 is further pre-trained from an intermediate checkpoint of DeepSeek-V2 with additional 6 trillion tokens. Through this continued pre-training, DeepSeek-Coder-V2 substantially enhances the coding and mathematical reasoning capabilities of DeepSeek-V2, while maintaining comparable performance in general language tasks. Compared to DeepSeek-Coder-33B, DeepSeek-Coder-V2 demonstrates significant advancements in various aspects of code-related tasks, as well as reasoning and general capabilities. Additionally, DeepSeek-Coder-V2 expands its support for programming languages from 86 to 338, while extending the context length from 16K to 128K. In standard benchmark evaluations, DeepSeek-Coder-V2 achieves superior performance compared to closed-source models such as GPT4-Turbo, Claude 3 Opus, and Gemini 1.5 Pro in coding and math benchmarks.
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
Jan 26, 2024



The rapid development of large language models has revolutionized code intelligence in software development. However, the predominance of closed-source models has restricted extensive research and development. To address this, we introduce the DeepSeek-Coder series, a range of open-source code models with sizes from 1.3B to 33B, trained from scratch on 2 trillion tokens. These models are pre-trained on a high-quality project-level code corpus and employ a fill-in-the-blank task with a 16K window to enhance code generation and infilling. Our extensive evaluations demonstrate that DeepSeek-Coder not only achieves state-of-the-art performance among open-source code models across multiple benchmarks but also surpasses existing closed-source models like Codex and GPT-3.5. Furthermore, DeepSeek-Coder models are under a permissive license that allows for both research and unrestricted commercial use.
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Jan 05, 2024



The rapid development of open-source large language models (LLMs) has been truly remarkable. However, the scaling law described in previous literature presents varying conclusions, which casts a dark cloud over scaling LLMs. We delve into the study of scaling laws and present our distinctive findings that facilitate scaling of large scale models in two commonly used open-source configurations, 7B and 67B. Guided by the scaling laws, we introduce DeepSeek LLM, a project dedicated to advancing open-source language models with a long-term perspective. To support the pre-training phase, we have developed a dataset that currently consists of 2 trillion tokens and is continuously expanding. We further conduct supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, resulting in the creation of DeepSeek Chat models. Our evaluation results demonstrate that DeepSeek LLM 67B surpasses LLaMA-2 70B on various benchmarks, particularly in the domains of code, mathematics, and reasoning. Furthermore, open-ended evaluations reveal that DeepSeek LLM 67B Chat exhibits superior performance compared to GPT-3.5.
CERT: Continual Pre-Training on Sketches for Library-Oriented Code Generation
Jun 14, 2022
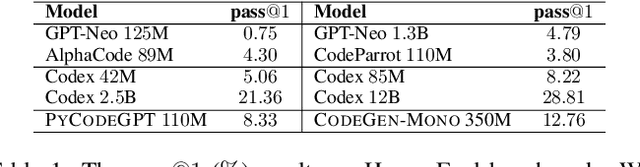

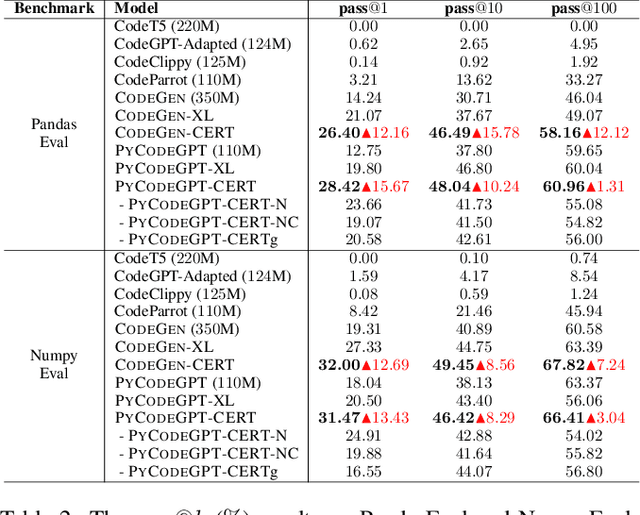
Code generation is a longstanding challenge, aiming to generate a code snippet based on a natural language description. Usually, expensive text-code paired data is essential for training a code generation model. Recently, thanks to the success of pre-training techniques, large language models are trained on large-scale unlabelled code corpora and perform well in code generation. In this paper, we investigate how to leverage an unlabelled code corpus to train a model for library-oriented code generation. Since it is a common practice for programmers to reuse third-party libraries, in which case the text-code paired data are harder to obtain due to the huge number of libraries. We observe that library-oriented code snippets are more likely to share similar code sketches. Hence, we present CERT with two steps: a sketcher generates the sketch, then a generator fills the details in the sketch. Both the sketcher and the generator are continually pre-trained upon a base model using unlabelled data. Furthermore, we craft two benchmarks named PandasEval and NumpyEval to evaluate library-oriented code generation. Experimental results demonstrate the impressive performance of CERT. For example, it surpasses the base model by an absolute 15.67% improvement in terms of pass@1 on PandasEval. Our work is available at https://github.com/microsoft/PyCodeGPT.
Awakening Latent Grounding from Pretrained Language Models for Semantic Parsing
Sep 22, 2021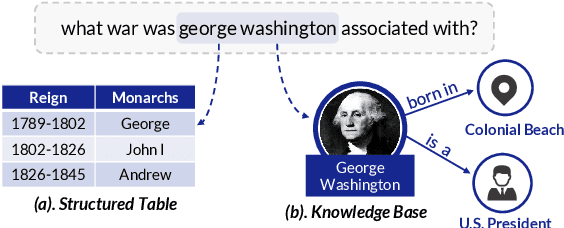
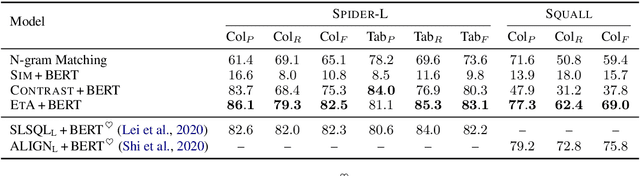
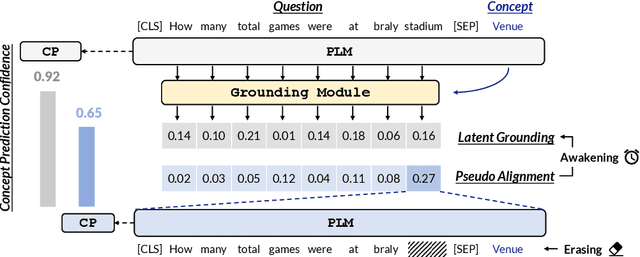
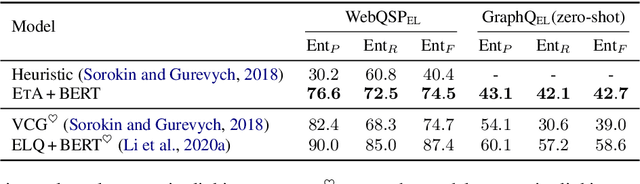
Recent years pretrained language models (PLMs) hit a success on several downstream tasks, showing their power on modeling language. To better understand and leverage what PLMs have learned, several techniques have emerged to explore syntactic structures entailed by PLMs. However, few efforts have been made to explore grounding capabilities of PLMs, which are also essential. In this paper, we highlight the ability of PLMs to discover which token should be grounded to which concept, if combined with our proposed erasing-then-awakening approach. Empirical studies on four datasets demonstrate that our approach can awaken latent grounding which is understandable to human experts, even if it is not exposed to such labels during training. More importantly, our approach shows great potential to benefit downstream semantic parsing models. Taking text-to-SQL as a case study, we successfully couple our approach with two off-the-shelf parsers, obtaining an absolute improvement of up to 9.8%.
Neural Response Generation with Dynamic Vocabularies
Nov 30, 2017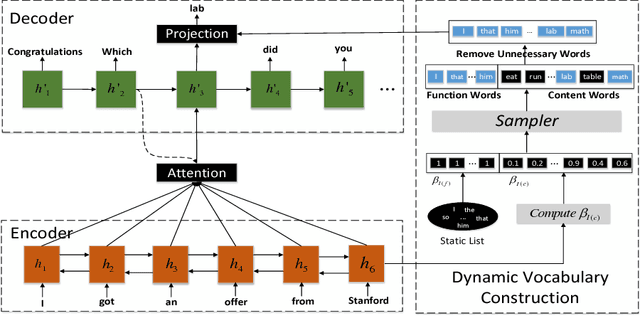

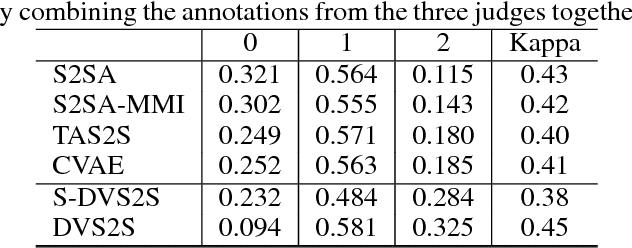
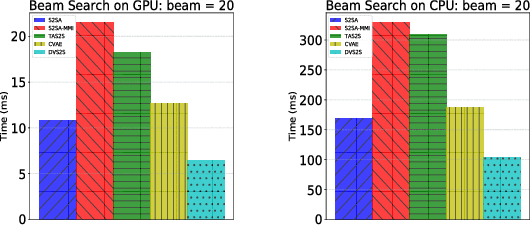
We study response generation for open domain conversation in chatbots. Existing methods assume that words in responses are generated from an identical vocabulary regardless of their inputs, which not only makes them vulnerable to generic patterns and irrelevant noise, but also causes a high cost in decoding. We propose a dynamic vocabulary sequence-to-sequence (DVS2S) model which allows each input to possess their own vocabulary in decoding. In training, vocabulary construction and response generation are jointly learned by maximizing a lower bound of the true objective with a Monte Carlo sampling method. In inference, the model dynamically allocates a small vocabulary for an input with the word prediction model, and conducts decoding only with the small vocabulary. Because of the dynamic vocabulary mechanism, DVS2S eludes many generic patterns and irrelevant words in generation, and enjoys efficient decoding at the same time. Experimental results on both automatic metrics and human annotations show that DVS2S can significantly outperform state-of-the-art methods in terms of response quality, but only requires 60% decoding time compared to the most efficient baseline.