 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCERT: Continual Pre-Training on Sketches for Library-Oriented Code Generation
Paper and Code

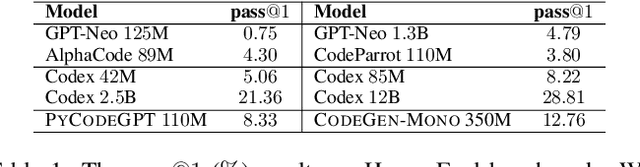

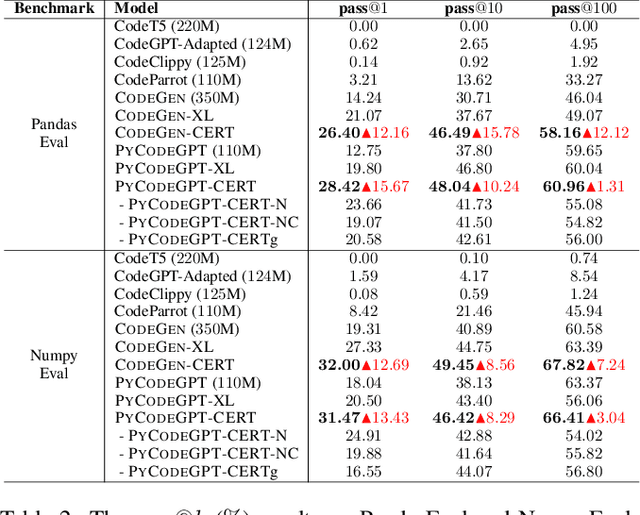
Code generation is a longstanding challenge, aiming to generate a code snippet based on a natural language description. Usually, expensive text-code paired data is essential for training a code generation model. Recently, thanks to the success of pre-training techniques, large language models are trained on large-scale unlabelled code corpora and perform well in code generation. In this paper, we investigate how to leverage an unlabelled code corpus to train a model for library-oriented code generation. Since it is a common practice for programmers to reuse third-party libraries, in which case the text-code paired data are harder to obtain due to the huge number of libraries. We observe that library-oriented code snippets are more likely to share similar code sketches. Hence, we present CERT with two steps: a sketcher generates the sketch, then a generator fills the details in the sketch. Both the sketcher and the generator are continually pre-trained upon a base model using unlabelled data. Furthermore, we craft two benchmarks named PandasEval and NumpyEval to evaluate library-oriented code generation. Experimental results demonstrate the impressive performance of CERT. For example, it surpasses the base model by an absolute 15.67% improvement in terms of pass@1 on PandasEval. Our work is available at https://github.com/microsoft/PyCodeGPT.