 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-bench-java: A GitHub Issue Resolving Benchmark for Java
Aug 26, 2024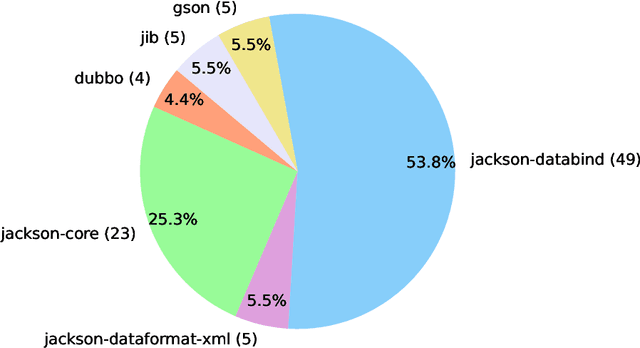



GitHub issue resolving is a critical task in software engineering, recently gaining significant attention in both industry and academia. Within this task, SWE-bench has been released to evaluate issue resolving capabilities of large language models (LLMs), but has so far only focused on Python version. However, supporting more programming languages is also important, as there is a strong demand in industry. As a first step toward multilingual support, we have developed a Java version of SWE-bench, called SWE-bench-java. We have publicly released the dataset, along with the corresponding Docker-based evaluation environment and leaderboard, which will be continuously maintained and updated in the coming months. To verify the reliability of SWE-bench-java, we implement a classic method SWE-agent and test several powerful LLMs on it. As is well known, developing a high-quality multi-lingual benchmark is time-consuming and labor-intensive, so we welcome contributions through pull requests or collaboration to accelerate its iteration and refinement, paving the way for fully automated programming.
CodeS: Natural Language to Code Repository via Multi-Layer Sketch
Mar 25, 2024



The impressive performance of large language models (LLMs) on code-related tasks has shown the potential of fully automated software development. In light of this, we introduce a new software engineering task, namely Natural Language to code Repository (NL2Repo). This task aims to generate an entire code repository from its natural language requirements. To address this task, we propose a simple yet effective framework CodeS, which decomposes NL2Repo into multiple sub-tasks by a multi-layer sketch. Specifically, CodeS includes three modules: RepoSketcher, FileSketcher, and SketchFiller. RepoSketcher first generates a repository's directory structure for given requirements; FileSketcher then generates a file sketch for each file in the generated structure; SketchFiller finally fills in the details for each function in the generated file sketch. To rigorously assess CodeS on the NL2Repo task, we carry out evaluations through both automated benchmarking and manual feedback analysis. For benchmark-based evaluation, we craft a repository-oriented benchmark, SketchEval, and design an evaluation metric, SketchBLEU. For feedback-based evaluation, we develop a VSCode plugin for CodeS and engage 30 participants in conducting empirical studies. Extensive experiments prove the effectiveness and practicality of CodeS on the NL2Repo task.
Improving Natural Language Capability of Code Large Language Model
Jan 25, 2024Code large language models (Code LLMs) have demonstrated remarkable performance in code generation. Nonetheless, most existing works focus on boosting code LLMs from the perspective of programming capabilities, while their natural language capabilities receive less attention. To fill this gap, we thus propose a novel framework, comprising two modules: AttentionExtractor, which is responsible for extracting key phrases from the user's natural language requirements, and AttentionCoder, which leverages these extracted phrases to generate target code to solve the requirement. This framework pioneers an innovative idea by seamlessly integrating code LLMs with traditional natural language processing tools. To validate the effectiveness of the framework, we craft a new code generation benchmark, called MultiNL-H, covering five natural languages. Extensive experimental results demonstrate the effectiveness of our proposed framework.
A GAN-based data poisoning framework against anomaly detection in vertical federated learning
Jan 17, 2024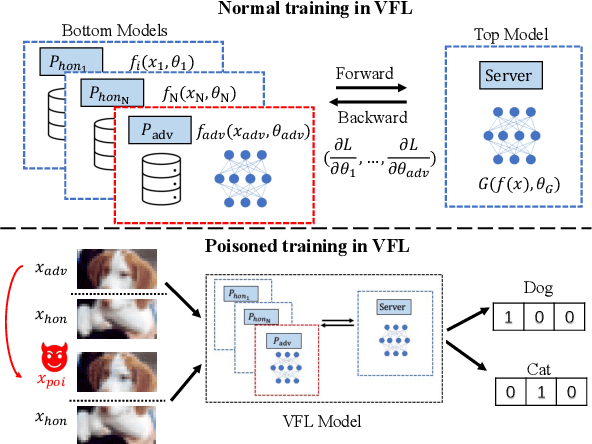
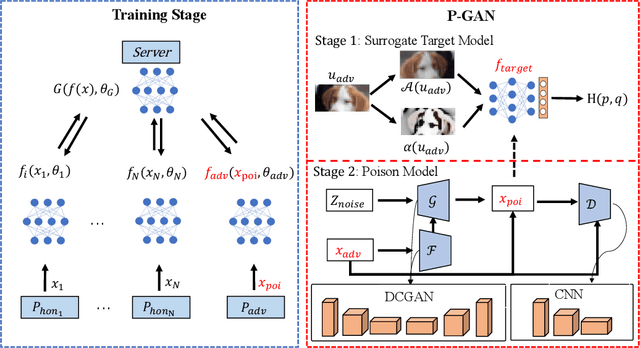
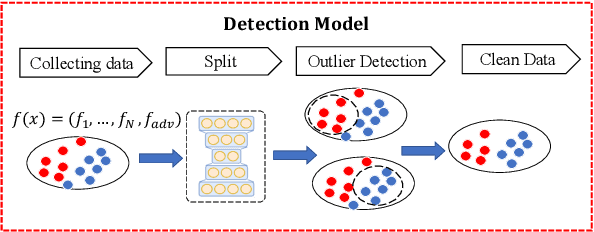
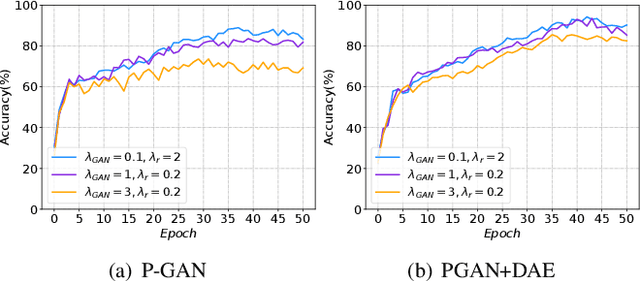
In vertical federated learning (VFL), commercial entities collaboratively train a model while preserving data privacy. However, a malicious participant's poisoning attack may degrade the performance of this collaborative model. The main challenge in achieving the poisoning attack is the absence of access to the server-side top model, leaving the malicious participant without a clear target model. To address this challenge, we introduce an innovative end-to-end poisoning framework P-GAN. Specifically, the malicious participant initially employs semi-supervised learning to train a surrogate target model. Subsequently, this participant employs a GAN-based method to produce adversarial perturbations to degrade the surrogate target model's performance. Finally, the generator is obtained and tailored for VFL poisoning. Besides, we develop an anomaly detection algorithm based on a deep auto-encoder (DAE), offering a robust defense mechanism to VFL scenarios. Through extensive experiments, we evaluate the efficacy of P-GAN and DAE, and further analyze the factors that influence their performance.
Hierarchical and Contrastive Representation Learning for Knowledge-aware Recommendation
Apr 15, 2023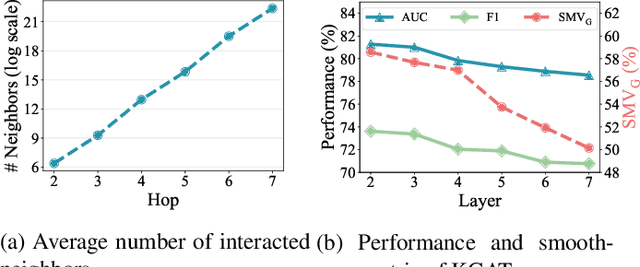
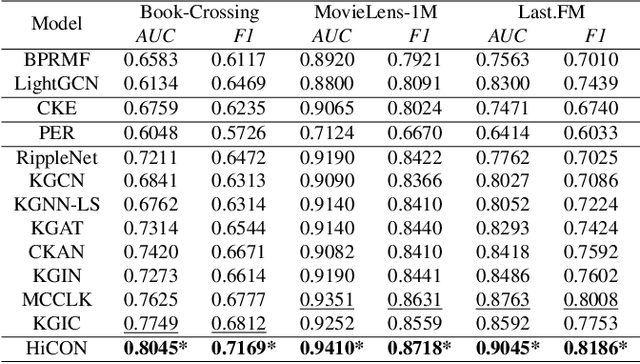
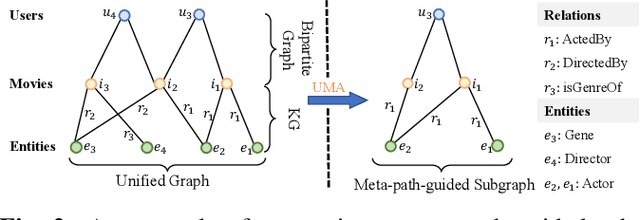

Incorporating knowledge graph into recommendation is an effective way to alleviate data sparsity. Most existing knowledge-aware methods usually perform recursive embedding propagation by enumerating graph neighbors. However, the number of nodes' neighbors grows exponentially as the hop number increases, forcing the nodes to be aware of vast neighbors under this recursive propagation for distilling the high-order semantic relatedness. This may induce more harmful noise than useful information into recommendation, leading the learned node representations to be indistinguishable from each other, that is, the well-known over-smoothing issue. To relieve this issue, we propose a Hierarchical and CONtrastive representation learning framework for knowledge-aware recommendation named HiCON. Specifically, for avoiding the exponential expansion of neighbors, we propose a hierarchical message aggregation mechanism to interact separately with low-order neighbors and meta-path-constrained high-order neighbors. Moreover, we also perform cross-order contrastive learning to enforce the representations to be more discriminative. Extensive experiments on three datasets show the remarkable superiority of HiCON over state-of-the-art approaches.
When Neural Model Meets NL2Code: A Survey
Dec 19, 2022Given a natural language that describes the user's demands, the NL2Code task aims to generate code that addresses the demands. This is a critical but challenging task that mirrors the capabilities of AI-powered programming. The NL2Code task is inherently versatile, diverse and complex. For example, a demand can be described in different languages, in different formats, and at different levels of granularity. This inspired us to do this survey for NL2Code. In this survey, we focus on how does neural network (NN) solves NL2Code. We first propose a comprehensive framework, which is able to cover all studies in this field. Then, we in-depth parse the existing studies into this framework. We create an online website to record the parsing results, which tracks existing and recent NL2Code progress. In addition, we summarize the current challenges of NL2Code as well as its future directions. We hope that this survey can foster the evolution of this field.
When Language Model Meets Private Library
Oct 31, 2022



With the rapid development of pre-training techniques, a number of language models have been pre-trained on large-scale code corpora and perform well in code generation. In this paper, we investigate how to equip pre-trained language models with the ability of code generation for private libraries. In practice, it is common for programmers to write code using private libraries. However, this is a challenge for language models since they have never seen private APIs during training. Motivated by the fact that private libraries usually come with elaborate API documentation, we propose a novel framework with two modules: the APIRetriever finds useful APIs, and then the APICoder generates code using these APIs. For APIRetriever, we present a dense retrieval system and also design a friendly interaction to involve uses. For APICoder, we can directly use off-the-shelf language models, or continually pre-train the base model on a code corpus containing API information. Both modules are trained with data from public libraries and can be generalized to private ones. Furthermore, we craft three benchmarks for private libraries, named TorchDataEval, MonkeyEval, and BeatNumEval. Experimental results demonstrate the impressive performance of our framework.
CERT: Continual Pre-Training on Sketches for Library-Oriented Code Generation
Jun 14, 2022
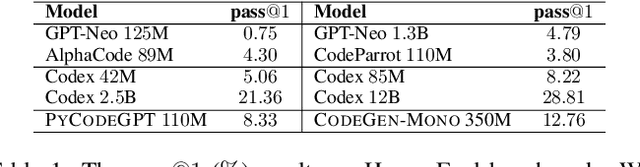

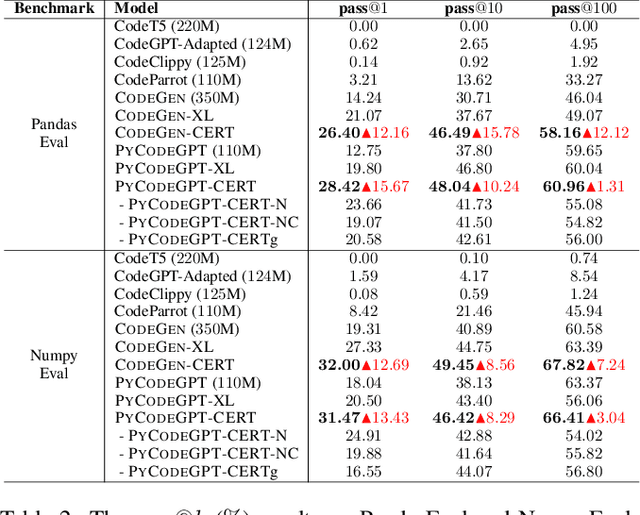
Code generation is a longstanding challenge, aiming to generate a code snippet based on a natural language description. Usually, expensive text-code paired data is essential for training a code generation model. Recently, thanks to the success of pre-training techniques, large language models are trained on large-scale unlabelled code corpora and perform well in code generation. In this paper, we investigate how to leverage an unlabelled code corpus to train a model for library-oriented code generation. Since it is a common practice for programmers to reuse third-party libraries, in which case the text-code paired data are harder to obtain due to the huge number of libraries. We observe that library-oriented code snippets are more likely to share similar code sketches. Hence, we present CERT with two steps: a sketcher generates the sketch, then a generator fills the details in the sketch. Both the sketcher and the generator are continually pre-trained upon a base model using unlabelled data. Furthermore, we craft two benchmarks named PandasEval and NumpyEval to evaluate library-oriented code generation. Experimental results demonstrate the impressive performance of CERT. For example, it surpasses the base model by an absolute 15.67% improvement in terms of pass@1 on PandasEval. Our work is available at https://github.com/microsoft/PyCodeGPT.