 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiBrA-Net: Lie-Algebraic Bilateral Affine Fields for Real-Time 4K Video Dehazing
May 12, 2026Currently, there is a gap in the field of ultra-high-definition (UHD) video dehazing due to the lack of a benchmark for evaluation. Furthermore, existing video dehazing methods cannot run on consumer-grade GPUs when processing continuous UHD sequences of 3--5 frames at a time. In this paper, we address both issues with a new benchmark and an efficient method. Our key observation is that atmospheric dehazing reduces to a per-pixel affine transform governed by the low-frequency depth field, which can be compactly encoded in bilateral grids whose prediction cost is decoupled from the output resolution. Building on this, we propose LiBrA-Net, which factorizes the spatiotemporal affine field into a spatial--color and a temporal bilateral sub-grid predicted at a fixed low resolution, fuses their coefficients in the $\mathfrak{gl}(3)$ Lie algebra under group-theoretic regularization, maps the result to invertible GL(3) transforms via a Cayley parameterization, and restores high-frequency detail through a lightweight input-guided branch. We further release UHV-4K, the first paired 4K video dehazing benchmark with depth, transmission, and optical-flow annotations on every frame. Across UHV-4K, REVIDE, and HazeWorld, LiBrA-Net sets a new state of the art among compared video dehazing methods while running native 4K at 25 FPS on a single GPU with only 6.12 M parameters. Code and data are available at https://anonymous.4open.science/r/LiBrA-Net-42B8.
RPBA-Net: An Interpretable Residual Pyramid Bilateral Affine Network for RAW-Domain ISP Enhancement
May 05, 2026To address module fragmentation, uninterpretable mappings, and deployment constraints in RAW-domain demosaicing, color correction, and detail enhancement, this paper proposes RPBA-Net, an interpretable residual pyramid bilateral affine network for RAW-domain ISP enhancement. Given packed RAW as input, the method performs residual affine base reconstruction by estimating a base RGB representation and learning identity-guided residual affine corrections, thereby unifying demosaicing and enhancement. It further builds pyramid bilateral affine grids and combines guide-driven autoregressive adaptive slicing with adaptive cross-layer fusion to hierarchically model global tone restoration and local texture enhancement. In addition, smoothness, cross-scale consistency, and magnitude regularization terms are introduced to improve model stability, controllability, and structural interpretability. Extensive experiments demonstrate that RPBA-Net surpasses representative RAW-to-sRGB methods and achieves state-of-the-art performance in reconstruction fidelity and perceptual quality, while maintaining low model complexity and strong deployment potential for mobile and embedded platforms.
6thGrid-Net: Unified Remote Sensing Image Dehazing Based on Color Restoration and Edge-Preserving
Apr 27, 2026Remote sensing images are frequently degraded by adverse weather conditions, particularly clouds and haze, which severely impair downstream applications. Existing restoration methods typically rely on computationally heavy architectures or sequential pipelines (e.g., detail enhancement followed by color rendition) that suffer from mutual interference and artifact accumulation. Furthermore, recent unified grid-based approaches utilize fixed, isotropic interpolation kernels, neglecting the intrinsic low-dimensional manifold of natural images and inevitably causing edge blur. To address these limitations, we propose 6th Grid-Net, a highly efficient and unified remote sensing image restoration framework tailored for resource-constrained edge devices. Specifically, we construct a novel six-dimensional fusion tensor that seamlessly integrates the color rendition capabilities of 3D LUTs with the spatial-luminance detail preservation of bilateral grids. To overcome the drawbacks of standard trilinear interpolation, we introduce a manifold-adaptive high-dimensional sampling mechanism. This mechanism dynamically adjusts the interpolation kernel based on local edge orientation, texture strength, and color similarity, enabling simultaneous global color stylization and local edge refinement in a single forward pass. Additionally, an edge-aware grid smoothing constraint and dynamic quantization are incorporated to suppress ghosting artifacts and significantly compress the model size. Extensive experiments on multiple benchmark datasets demonstrate that 6th Grid-Net achieves state-of-the-art restoration quality across various degradation scenarios.
UHD-GPGNet: UHD Video Denoising via Gaussian-Process-Guided Local Spatio-Temporal Modeling
Apr 13, 2026Ultra-high-definition (UHD) video denoising requires simultaneously suppressing complex spatio-temporal degradations, preserving fine textures and chromatic stability, and maintaining efficient full-resolution 4K deployment. In this paper, we propose UHD-GPGNet, a Gaussian-process-guided local spatio-temporal denoising framework that addresses these requirements jointly. Rather than relying on implicit feature learning alone, the method estimates sparse GP posterior statistics over compact spatio-temporal descriptors to explicitly characterize local degradation response and uncertainty, which then guide adaptive temporal-detail fusion. A structure-color collaborative reconstruction head decouples luminance, chroma, and high-frequency correction, while a heteroscedastic objective and overlap-tiled inference further stabilize optimization and enable memory-bounded 4K deployment. Experiments on UVG and RealisVideo-4K show that UHD-GPGNet achieves competitive restoration fidelity with substantially fewer parameters than existing methods, enables real-time full-resolution 4K inference with significant speedup over the closest quality competitor, and maintains robust performance across a multi-level mixed-degradation schedule.A real-world study on phone-captured 4K video further confirms that the model, trained entirely on synthetic degradation, generalizes to unseen real sensor noise and improves downstream object detection under challenging conditions.
UHD Low-Light Image Enhancement via Real-Time Enhancement Methods with Clifford Information Fusion
Apr 10, 2026Considering efficiency, ultra-high-definition (UHD) low-light image restoration is extremely challenging. Existing methods based on Transformer architectures or high-dimensional complex convolutional neural networks often suffer from the "memory wall" bottleneck, failing to achieve millisecond-level inference on edge devices. To address this issue, we propose a novel real-time UHD low-light enhancement network based on geometric feature fusion using Clifford algebra in 2D Euclidean space. First, we construct a four-layer feature pyramid with gradually increasing resolution, which decomposes input images into low-frequency and high-frequency structural components via a Gaussian blur kernel, and adopts a lightweight U-Net based on depthwise separable convolution for dual-branch feature extraction. Second, to resolve structural information loss and artifacts from traditional high-low frequency feature fusion, we introduce spatially aware Clifford algebra, which maps feature tensors to a multivector space (scalars, vectors, bivectors) and uses Clifford similarity to aggregate features while suppressing noise and preserving textures. In the reconstruction stage, the network outputs adaptive Gamma and Gain maps, which perform physically constrained non-linear brightness adjustment via Retinex theory. Integrated with FP16 mixed-precision computation and dynamic operator fusion, our method achieves millisecond-level inference for 4K/8K images on a single consumer-grade device, while outperforming state-of-the-art (SOTA) models on several restoration metrics.
Unifying VLM-Guided Flow Matching and Spectral Anomaly Detection for Interpretable Veterinary Diagnosis
Apr 07, 2026Automatic diagnosis of canine pneumothorax is challenged by data scarcity and the need for trustworthy models. To address this, we first introduce a public, pixel-level annotated dataset to facilitate research. We then propose a novel diagnostic paradigm that reframes the task as a synergistic process of signal localization and spectral detection. For localization, our method employs a Vision-Language Model (VLM) to guide an iterative Flow Matching process, which progressively refines segmentation masks to achieve superior boundary accuracy. For detection, the segmented mask is used to isolate features from the suspected lesion. We then apply Random Matrix Theory (RMT), a departure from traditional classifiers, to analyze these features. This approach models healthy tissue as predictable random noise and identifies pneumothorax by detecting statistically significant outlier eigenvalues that represent a non-random pathological signal. The high-fidelity localization from Flow Matching is crucial for purifying the signal, thus maximizing the sensitivity of our RMT detector. This synergy of generative segmentation and first-principles statistical analysis yields a highly accurate and interpretable diagnostic system (source code is available at: https://github.com/Pu-Wang-alt/Canine-pneumothorax).
UHD Image Deblurring via Autoregressive Flow with Ill-conditioned Constraints
Mar 11, 2026Ultra-high-definition (UHD) image deblurring poses significant challenges for UHD restoration methods, which must balance fine-grained detail recovery and practical inference efficiency. Although prominent discriminative and generative methods have achieved remarkable results, a trade-off persists between computational cost and the ability to generate fine-grained detail for UHD image deblurring tasks. To further alleviate these issues, we propose a novel autoregressive flow method for UHD image deblurring with an ill-conditioned constraint. Our core idea is to decompose UHD restoration into a progressive, coarse-to-fine process: at each scale, the sharp estimate is formed by upsampling the previous-scale result and adding a current-scale residual, enabling stable, stage-wise refinement from low to high resolution. We further introduce Flow Matching to model residual generation as a conditional vector field and perform few-step ODE sampling with efficient Euler/Heun solvers, enriching details while keeping inference affordable. Since multi-step generation at UHD can be numerically unstable, we propose an ill-conditioning suppression scheme by imposing condition-number regularization on a feature-induced attention matrix, improving convergence and cross-scale consistency. Our method demonstrates promising performance on blurred images at 4K (3840$\times$2160) or higher resolutions.
Teacher-Guided Causal Interventions for Image Denoising: Orthogonal Content-Noise Disentanglement in Vision Transformers
Mar 01, 2026Conventional image denoising models often inadvertently learn spurious correlations between environmental factors and noise patterns. Moreover, due to high-frequency ambiguity, they struggle to reliably distinguish subtle textures from stochastic noise, resulting in over-removed details or residual noise artifacts. We therefore revisit denoising via causal intervention, arguing that purely correlational fitting entangles intrinsic content with extrinsic noise, which directly degrades robustness under distribution shifts. Motivated by this, we propose the Teacher-Guided Causal Disentanglement Network (TCD-Net), which explicitly decomposes the generative mechanism via structured interventions on feature spaces within a Vision Transformer framework. Specifically, our method integrates three key components: (1) An Environmental Bias Adjustment (EBA) module projects features into a stable, de-centered subspace to suppress global environmental bias (de-confounding). (2) A dual-branch disentanglement head employs an orthogonality constraint to force a strict separation between content and noise representations, preventing information leakage. (3) To resolve structural ambiguity, we leverage Nano Banana Pro, Google's reasoning-guided AI image generation model, to guide a causal prior, effectively pulling content representations back onto the natural-image manifold. Extensive experiments demonstrate that TCD-Net outperforms mainstream methods across multiple benchmarks in both fidelity and efficiency, achieving a real-time speed of 104.2 FPS on a single RTX 5090 GPU.
SSPFormer: Self-Supervised Pretrained Transformer for MRI Images
Jan 19, 2026The pre-trained transformer demonstrates remarkable generalization ability in natural image processing. However, directly transferring it to magnetic resonance images faces two key challenges: the inability to adapt to the specificity of medical anatomical structures and the limitations brought about by the privacy and scarcity of medical data. To address these issues, this paper proposes a Self-Supervised Pretrained Transformer (SSPFormer) for MRI images, which effectively learns domain-specific feature representations of medical images by leveraging unlabeled raw imaging data. To tackle the domain gap and data scarcity, we introduce inverse frequency projection masking, which prioritizes the reconstruction of high-frequency anatomical regions to enforce structure-aware representation learning. Simultaneously, to enhance robustness against real-world MRI artifacts, we employ frequency-weighted FFT noise enhancement that injects physiologically realistic noise into the Fourier domain. Together, these strategies enable the model to learn domain-invariant and artifact-robust features directly from raw scans. Through extensive experiments on segmentation, super-resolution, and denoising tasks, the proposed SSPFormer achieves state-of-the-art performance, fully verifying its ability to capture fine-grained MRI image fidelity and adapt to clinical application requirements.
DCA-LUT: Deep Chromatic Alignment with 5D LUT for Purple Fringing Removal
Nov 15, 2025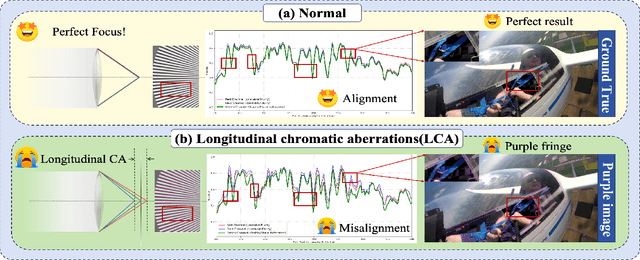
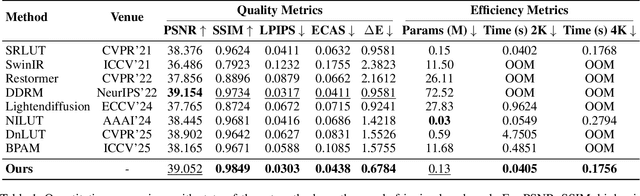
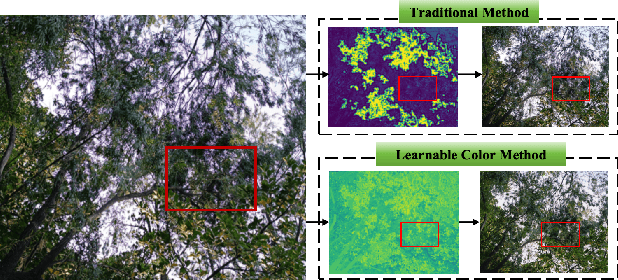
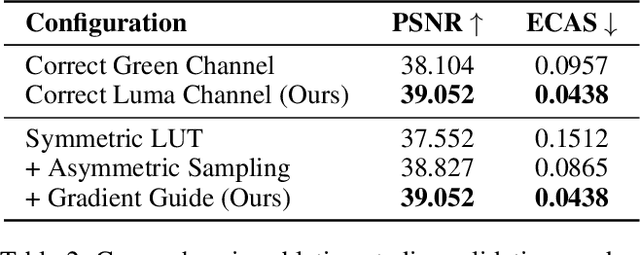
Purple fringing, a persistent artifact caused by Longitudinal Chromatic Aberration (LCA) in camera lenses, has long degraded the clarity and realism of digital imaging. Traditional solutions rely on complex and expensive apochromatic (APO) lens hardware and the extraction of handcrafted features, ignoring the data-driven approach. To fill this gap, we introduce DCA-LUT, the first deep learning framework for purple fringing removal. Inspired by the physical root of the problem, the spatial misalignment of RGB color channels due to lens dispersion, we introduce a novel Chromatic-Aware Coordinate Transformation (CA-CT) module, learning an image-adaptive color space to decouple and isolate fringing into a dedicated dimension. This targeted separation allows the network to learn a precise ``purple fringe channel", which then guides the accurate restoration of the luminance channel. The final color correction is performed by a learned 5D Look-Up Table (5D LUT), enabling efficient and powerful% non-linear color mapping. To enable robust training and fair evaluation, we constructed a large-scale synthetic purple fringing dataset (PF-Synth). Extensive experiments in synthetic and real-world datasets demonstrate that our method achieves state-of-the-art performance in purple fringing removal.